 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Audio Tokens: More Than a Survey!
Jun 12, 2025Discrete audio tokens are compact representations that aim to preserve perceptual quality, phonetic content, and speaker characteristics while enabling efficient storage and inference, as well as competitive performance across diverse downstream tasks.They provide a practical alternative to continuous features, enabling the integration of speech and audio into modern large language models (LLMs). As interest in token-based audio processing grows, various tokenization methods have emerged, and several surveys have reviewed the latest progress in the field. However, existing studies often focus on specific domains or tasks and lack a unified comparison across various benchmarks. This paper presents a systematic review and benchmark of discrete audio tokenizers, covering three domains: speech, music, and general audio. We propose a taxonomy of tokenization approaches based on encoder-decoder, quantization techniques, training paradigm, streamability, and application domains. We evaluate tokenizers on multiple benchmarks for reconstruction, downstream performance, and acoustic language modeling, and analyze trade-offs through controlled ablation studies. Our findings highlight key limitations, practical considerations, and open challenges, providing insight and guidance for future research in this rapidly evolving area. For more information, including our main results and tokenizer database, please refer to our website: https://poonehmousavi.github.io/dates-website/.
What Are They Doing? Joint Audio-Speech Co-Reasoning
Sep 22, 2024


In audio and speech processing, tasks usually focus on either the audio or speech modality, even when both sounds and human speech are present in the same audio clip. Recent Auditory Large Language Models (ALLMs) have made it possible to process audio and speech simultaneously within a single model, leading to further considerations of joint audio-speech tasks. In this paper, we investigate how well ALLMs can perform joint audio-speech processing. Specifically, we introduce Joint Audio-Speech Co-Reasoning (JASCO), a novel task that unifies audio and speech processing, strictly requiring co-reasoning across both modalities. We release a scene-reasoning dataset called "What Are They Doing" and establish a joint audio-speech benchmark to evaluate the joint reasoning capability of popular ALLMs. Additionally, we provide deeper insights into the models' behaviors by analyzing their dependence on each modality.
Open-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024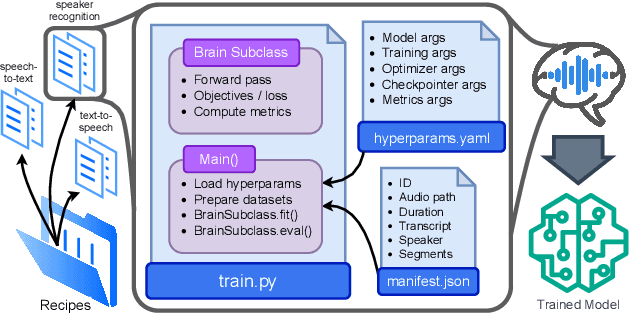

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
DASB -- Discrete Audio and Speech Benchmark
Jun 20, 2024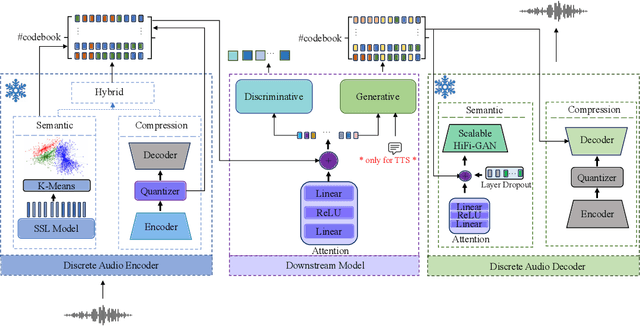
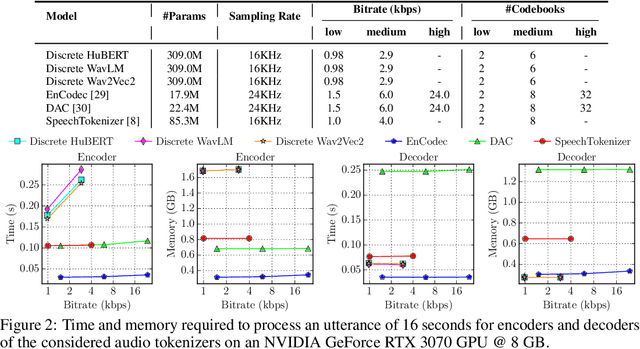
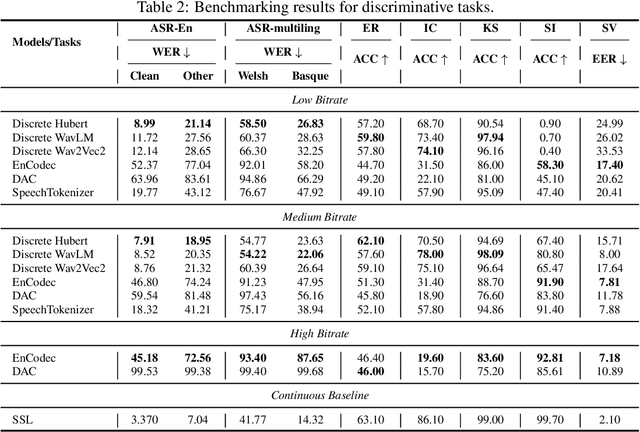
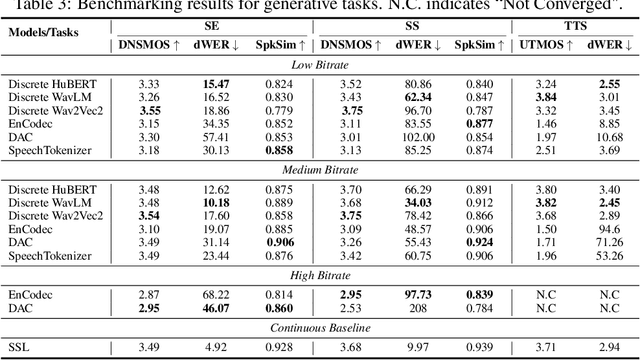
Discrete audio tokens have recently gained considerable attention for their potential to connect audio and language processing, enabling the creation of modern multimodal large language models. Ideal audio tokens must effectively preserve phonetic and semantic content along with paralinguistic information, speaker identity, and other details. While several types of audio tokens have been recently proposed, identifying the optimal tokenizer for various tasks is challenging due to the inconsistent evaluation settings in existing studies. To address this gap, we release the Discrete Audio and Speech Benchmark (DASB), a comprehensive leaderboard for benchmarking discrete audio tokens across a wide range of discriminative tasks, including speech recognition, speaker identification and verification, emotion recognition, keyword spotting, and intent classification, as well as generative tasks such as speech enhancement, separation, and text-to-speech. Our results show that, on average, semantic tokens outperform compression tokens across most discriminative and generative tasks. However, the performance gap between semantic tokens and standard continuous representations remains substantial, highlighting the need for further research in this field.
How Should We Extract Discrete Audio Tokens from Self-Supervised Models?
Jun 15, 2024



Discrete audio tokens have recently gained attention for their potential to bridge the gap between audio and language processing. Ideal audio tokens must preserve content, paralinguistic elements, speaker identity, and many other audio details. Current audio tokenization methods fall into two categories: Semantic tokens, acquired through quantization of Self-Supervised Learning (SSL) models, and Neural compression-based tokens (codecs). Although previous studies have benchmarked codec models to identify optimal configurations, the ideal setup for quantizing pretrained SSL models remains unclear. This paper explores the optimal configuration of semantic tokens across discriminative and generative tasks. We propose a scalable solution to train a universal vocoder across multiple SSL layers. Furthermore, an attention mechanism is employed to identify task-specific influential layers, enhancing the adaptability and performance of semantic tokens in diverse audio applications.
SoundChoice: Grapheme-to-Phoneme Models with Semantic Disambiguation
Jul 27, 2022
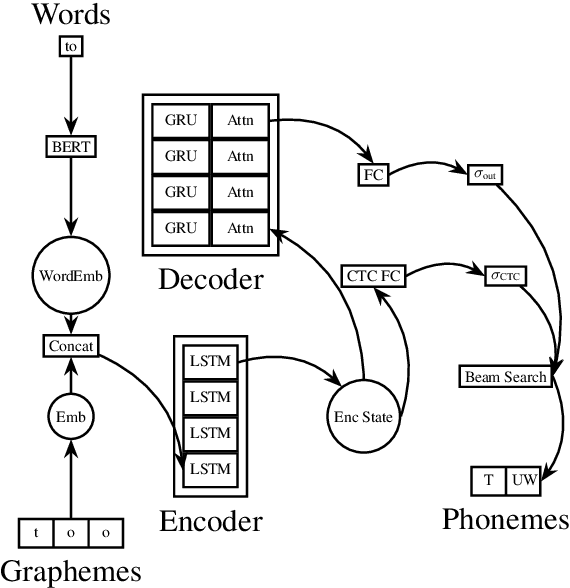

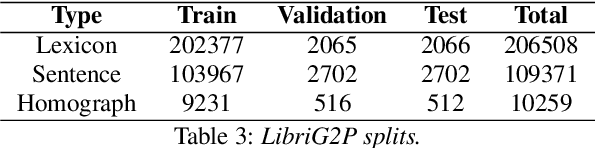
End-to-end speech synthesis models directly convert the input characters into an audio representation (e.g., spectrograms). Despite their impressive performance, such models have difficulty disambiguating the pronunciations of identically spelled words. To mitigate this issue, a separate Grapheme-to-Phoneme (G2P) model can be employed to convert the characters into phonemes before synthesizing the audio. This paper proposes SoundChoice, a novel G2P architecture that processes entire sentences rather than operating at the word level. The proposed architecture takes advantage of a weighted homograph loss (that improves disambiguation), exploits curriculum learning (that gradually switches from word-level to sentence-level G2P), and integrates word embeddings from BERT (for further performance improvement). Moreover, the model inherits the best practices in speech recognition, including multi-task learning with Connectionist Temporal Classification (CTC) and beam search with an embedded language model. As a result, SoundChoice achieves a Phoneme Error Rate (PER) of 2.65% on whole-sentence transcription using data from LibriSpeech and Wikipedia. Index Terms grapheme-to-phoneme, speech synthesis, text-tospeech, phonetics, pronunciation, disambiguation.