 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Audio Tokens: More Than a Survey!
Jun 12, 2025Discrete audio tokens are compact representations that aim to preserve perceptual quality, phonetic content, and speaker characteristics while enabling efficient storage and inference, as well as competitive performance across diverse downstream tasks.They provide a practical alternative to continuous features, enabling the integration of speech and audio into modern large language models (LLMs). As interest in token-based audio processing grows, various tokenization methods have emerged, and several surveys have reviewed the latest progress in the field. However, existing studies often focus on specific domains or tasks and lack a unified comparison across various benchmarks. This paper presents a systematic review and benchmark of discrete audio tokenizers, covering three domains: speech, music, and general audio. We propose a taxonomy of tokenization approaches based on encoder-decoder, quantization techniques, training paradigm, streamability, and application domains. We evaluate tokenizers on multiple benchmarks for reconstruction, downstream performance, and acoustic language modeling, and analyze trade-offs through controlled ablation studies. Our findings highlight key limitations, practical considerations, and open challenges, providing insight and guidance for future research in this rapidly evolving area. For more information, including our main results and tokenizer database, please refer to our website: https://poonehmousavi.github.io/dates-website/.
The Potential of Neural Speech Synthesis-based Data Augmentation for Personalized Speech Enhancement
Nov 14, 2022
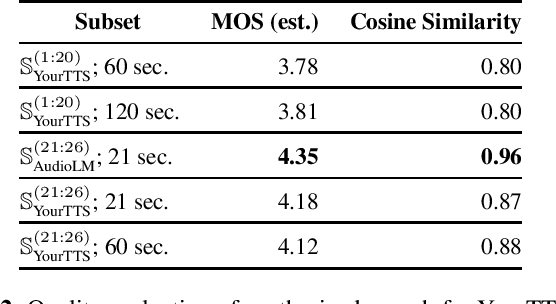

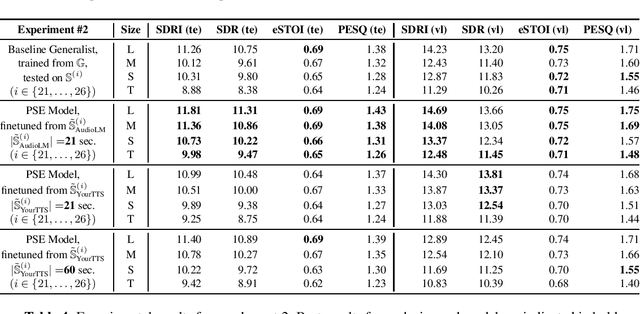
With the advances in deep learning, speech enhancement systems benefited from large neural network architectures and achieved state-of-the-art quality. However, speaker-agnostic methods are not always desirable, both in terms of quality and their complexity, when they are to be used in a resource-constrained environment. One promising way is personalized speech enhancement (PSE), which is a smaller and easier speech enhancement problem for small models to solve, because it focuses on a particular test-time user. To achieve the personalization goal, while dealing with the typical lack of personal data, we investigate the effect of data augmentation based on neural speech synthesis (NSS). In the proposed method, we show that the quality of the NSS system's synthetic data matters, and if they are good enough the augmented dataset can be used to improve the PSE system that outperforms the speaker-agnostic baseline. The proposed PSE systems show significant complexity reduction while preserving the enhancement quality.
Curriculum optimization for low-resource speech recognition
Feb 17, 2022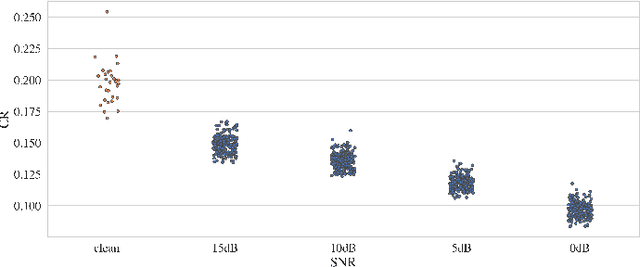
Modern end-to-end speech recognition models show astonishing results in transcribing audio signals into written text. However, conventional data feeding pipelines may be sub-optimal for low-resource speech recognition, which still remains a challenging task. We propose an automated curriculum learning approach to optimize the sequence of training examples based on both the progress of the model while training and prior knowledge about the difficulty of the training examples. We introduce a new difficulty measure called compression ratio that can be used as a scoring function for raw audio in various noise conditions. The proposed method improves speech recognition Word Error Rate performance by up to 33% relative over the baseline system
A bandit approach to curriculum generation for automatic speech recognition
Feb 06, 2021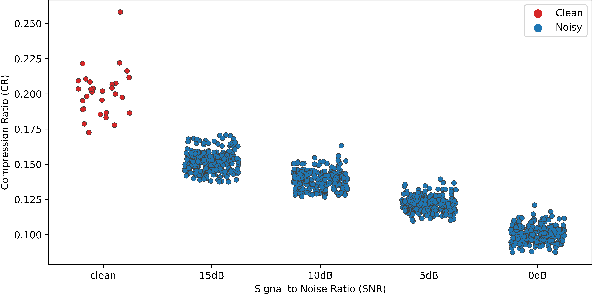
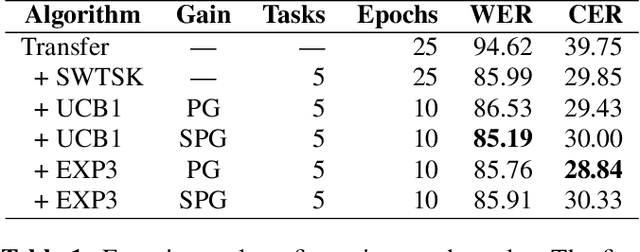
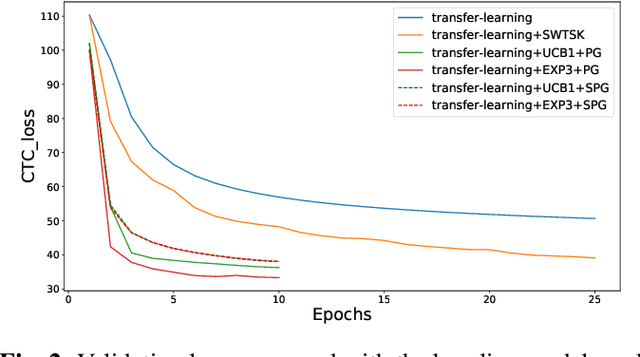
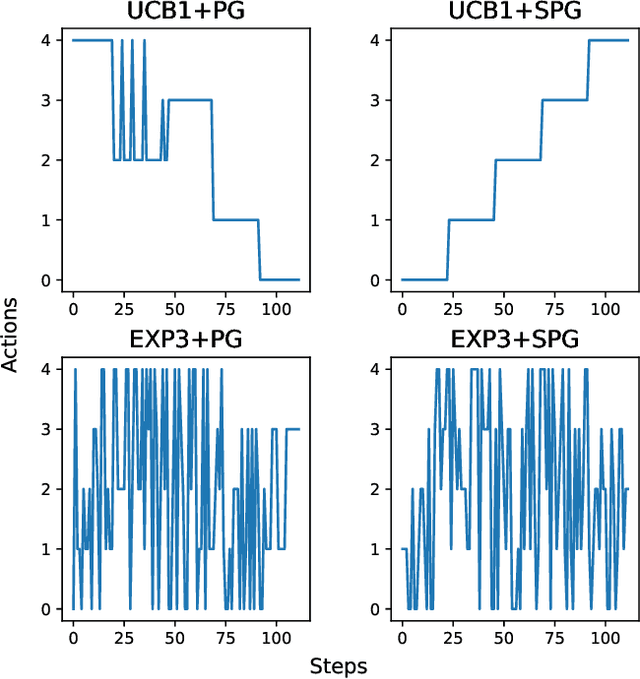
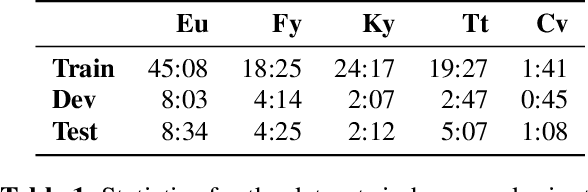
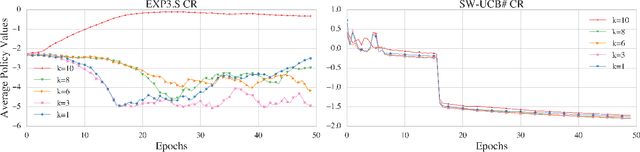
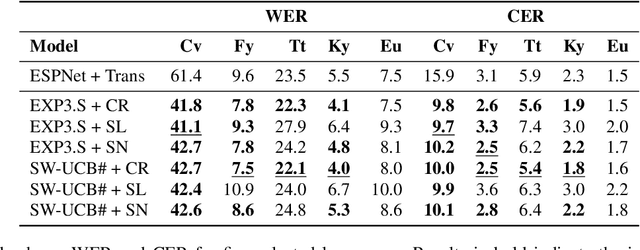
The Automated Speech Recognition (ASR) task has been a challenging domain especially for low data scenarios with few audio examples. This is the main problem in training ASR systems on the data from low-resource or marginalized languages. In this paper we present an approach to mitigate the lack of training data by employing Automated Curriculum Learning in combination with an adversarial bandit approach inspired by Reinforcement learning. The goal of the approach is to optimize the training sequence of mini-batches ranked by the level of difficulty and compare the ASR performance metrics against the random training sequence and discrete curriculum. We test our approach on a truly low-resource language and show that the bandit framework has a good improvement over the baseline transfer-learning model.