 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrevailing Research Areas for Music AI in the Era of Foundation Models
Sep 14, 2024In tandem with the recent advancements in foundation model research, there has been a surge of generative music AI applications within the past few years. As the idea of AI-generated or AI-augmented music becomes more mainstream, many researchers in the music AI community may be wondering what avenues of research are left. With regards to music generative models, we outline the current areas of research with significant room for exploration. Firstly, we pose the question of foundational representation of these generative models and investigate approaches towards explainability. Next, we discuss the current state of music datasets and their limitations. We then overview different generative models, forms of evaluating these models, and their computational constraints/limitations. Subsequently, we highlight applications of these generative models towards extensions to multiple modalities and integration with artists' workflow as well as music education systems. Finally, we survey the potential copyright implications of generative music and discuss strategies for protecting the rights of musicians. While it is not meant to be exhaustive, our survey calls to attention a variety of research directions enabled by music foundation models.
Multimodal Large Language Models with Fusion Low Rank Adaptation for Device Directed Speech Detection
Jun 13, 2024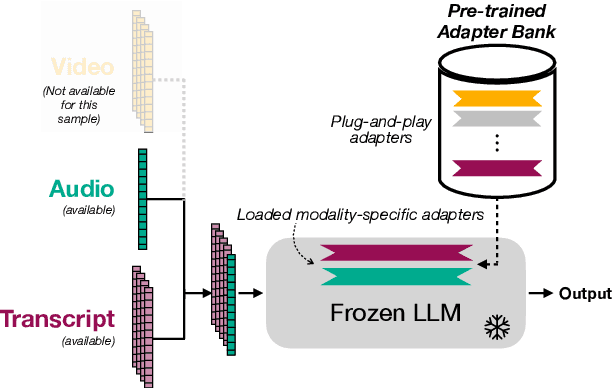
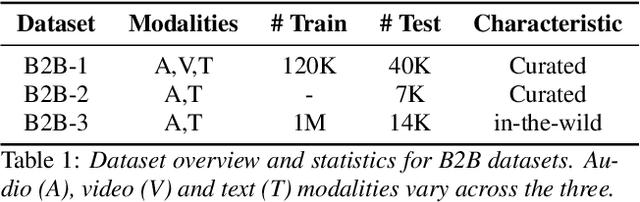
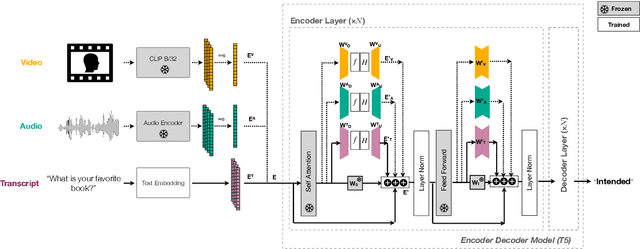
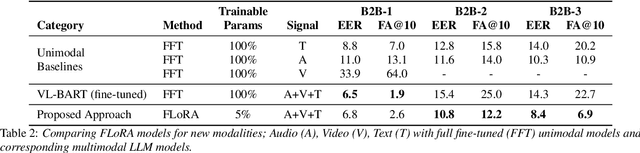
Although Large Language Models (LLMs) have shown promise for human-like conversations, they are primarily pre-trained on text data. Incorporating audio or video improves performance, but collecting large-scale multimodal data and pre-training multimodal LLMs is challenging. To this end, we propose a Fusion Low Rank Adaptation (FLoRA) technique that efficiently adapts a pre-trained unimodal LLM to consume new, previously unseen modalities via low rank adaptation. For device-directed speech detection, using FLoRA, the multimodal LLM achieves 22% relative reduction in equal error rate (EER) over the text-only approach and attains performance parity with its full fine-tuning (FFT) counterpart while needing to tune only a fraction of its parameters. Furthermore, with the newly introduced adapter dropout, FLoRA is robust to missing data, improving over FFT by 20% lower EER and 56% lower false accept rate. The proposed approach scales well for model sizes from 16M to 3B parameters.
The Potential of Neural Speech Synthesis-based Data Augmentation for Personalized Speech Enhancement
Nov 14, 2022
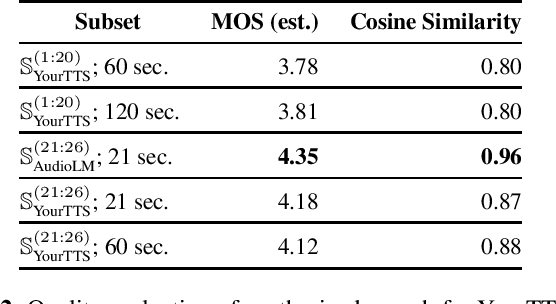

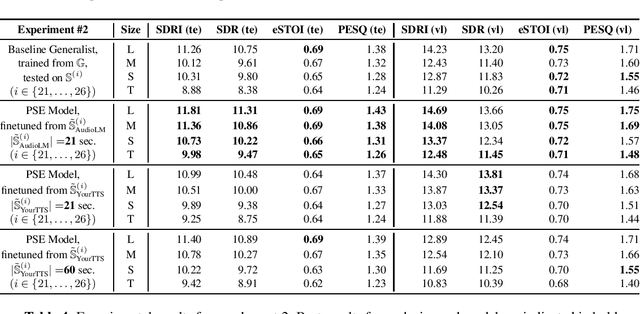
With the advances in deep learning, speech enhancement systems benefited from large neural network architectures and achieved state-of-the-art quality. However, speaker-agnostic methods are not always desirable, both in terms of quality and their complexity, when they are to be used in a resource-constrained environment. One promising way is personalized speech enhancement (PSE), which is a smaller and easier speech enhancement problem for small models to solve, because it focuses on a particular test-time user. To achieve the personalization goal, while dealing with the typical lack of personal data, we investigate the effect of data augmentation based on neural speech synthesis (NSS). In the proposed method, we show that the quality of the NSS system's synthetic data matters, and if they are good enough the augmented dataset can be used to improve the PSE system that outperforms the speaker-agnostic baseline. The proposed PSE systems show significant complexity reduction while preserving the enhancement quality.
Adapting Speech Separation to Real-World Meetings Using Mixture Invariant Training
Oct 20, 2021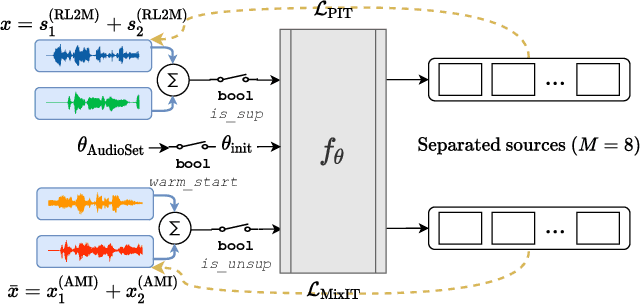
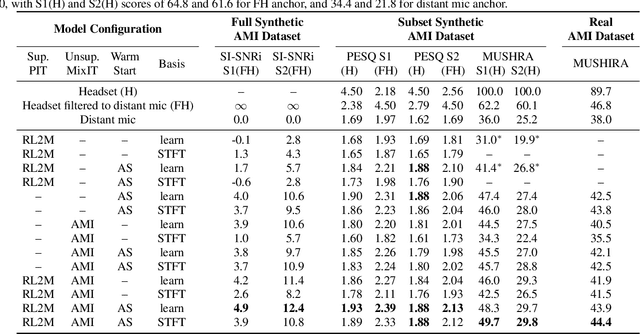
The recently-proposed mixture invariant training (MixIT) is an unsupervised method for training single-channel sound separation models in the sense that it does not require ground-truth isolated reference sources. In this paper, we investigate using MixIT to adapt a separation model on real far-field overlapping reverberant and noisy speech data from the AMI Corpus. The models are tested on real AMI recordings containing overlapping speech, and are evaluated subjectively by human listeners. To objectively evaluate our models, we also devise a synthetic AMI test set. For human evaluations on real recordings, we also propose a modification of the standard MUSHRA protocol to handle imperfect reference signals, which we call MUSHIRA. Holding network architectures constant, we find that a fine-tuned semi-supervised model yields the largest SI-SNR improvement, PESQ scores, and human listening ratings across synthetic and real datasets, outperforming unadapted generalist models trained on orders of magnitude more data. Our results show that unsupervised learning through MixIT enables model adaptation on real-world unlabeled spontaneous speech recordings.
Zero-Shot Personalized Speech Enhancement through Speaker-Informed Model Selection
May 08, 2021
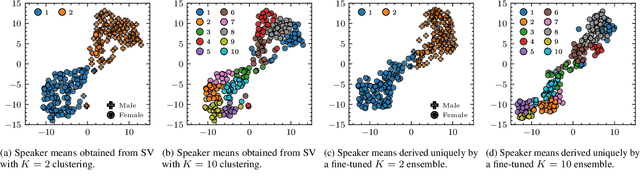
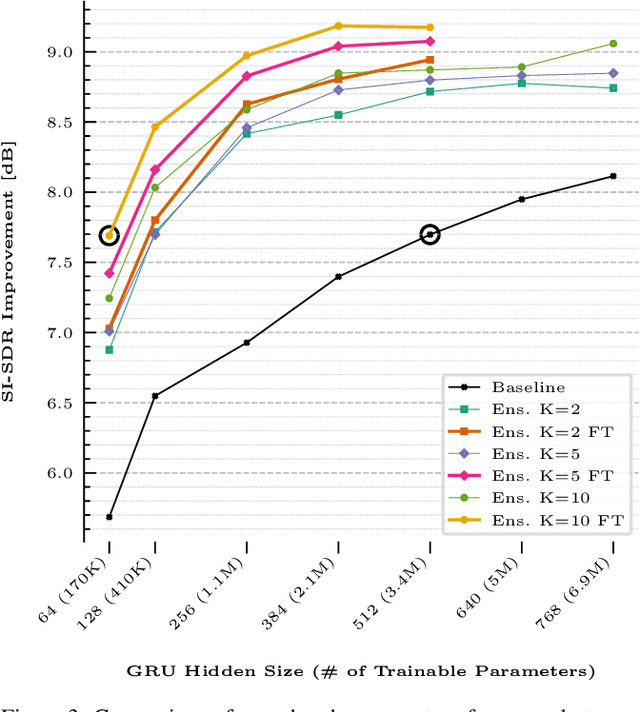
This paper presents a novel zero-shot learning approach towards personalized speech enhancement through the use of a sparsely active ensemble model. Optimizing speech denoising systems towards a particular test-time speaker can improve performance and reduce run-time complexity. However, test-time model adaptation may be challenging if collecting data from the test-time speaker is not possible. To this end, we propose using an ensemble model wherein each specialist module denoises noisy utterances from a distinct partition of training set speakers. The gating module inexpensively estimates test-time speaker characteristics in the form of an embedding vector and selects the most appropriate specialist module for denoising the test signal. Grouping the training set speakers into non-overlapping semantically similar groups is non-trivial and ill-defined. To do this, we first train a Siamese network using noisy speech pairs to maximize or minimize the similarity of its output vectors depending on whether the utterances derive from the same speaker or not. Next, we perform k-means clustering on the latent space formed by the averaged embedding vectors per training set speaker. In this way, we designate speaker groups and train specialist modules optimized around partitions of the complete training set. Our experiments show that ensemble models made up of low-capacity specialists can outperform high-capacity generalist models with greater efficiency and improved adaptation towards unseen test-time speakers.
Personalized Speech Enhancement through Self-Supervised Data Augmentation and Purification
Apr 05, 2021
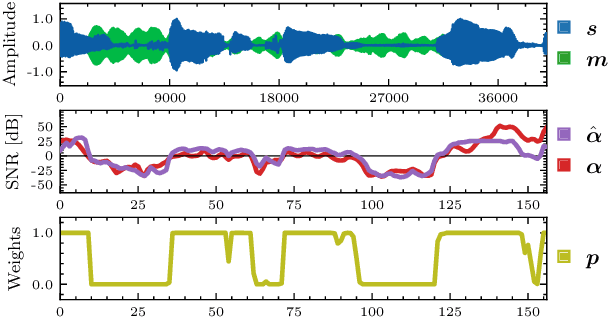

Training personalized speech enhancement models is innately a no-shot learning problem due to privacy constraints and limited access to noise-free speech from the target user. If there is an abundance of unlabeled noisy speech from the test-time user, a personalized speech enhancement model can be trained using self-supervised learning. One straightforward approach to model personalization is to use the target speaker's noisy recordings as pseudo-sources. Then, a pseudo denoising model learns to remove injected training noises and recover the pseudo-sources. However, this approach is volatile as it depends on the quality of the pseudo-sources, which may be too noisy. As a remedy, we propose an improvement to the self-supervised approach through data purification. We first train an SNR predictor model to estimate the frame-by-frame SNR of the pseudo-sources. Then, the predictor's estimates are converted into weights which adjust the frame-by-frame contribution of the pseudo-sources towards training the personalized model. We empirically show that the proposed data purification step improves the usability of the speaker-specific noisy data in the context of personalized speech enhancement. Without relying on any clean speech recordings or speaker embeddings, our approach may be seen as privacy-preserving.
Self-Supervised Learning for Personalized Speech Enhancement
Apr 05, 2021


Speech enhancement systems can show improved performance by adapting the model towards a single test-time speaker. In this personalization context, the test-time user might only provide a small amount of noise-free speech data, likely insufficient for traditional fully-supervised learning. One way to overcome the lack of personal data is to transfer the model parameters from a speaker-agnostic model to initialize the personalized model, and then to finetune the model using the small amount of personal speech data. This baseline marginally adapts over the scarce clean speech data. Alternatively, we propose self-supervised methods that are designed specifically to learn personalized and discriminative features from abundant in-the-wild noisy, but still personal speech recordings. Our experiment shows that the proposed self-supervised learning methods initialize personalized speech enhancement models better than the baseline fully-supervised methods, yielding superior speech enhancement performance. The proposed methods also result in a more robust feature set under the real-world conditions: compressed model sizes and fewness of the labeled data.
Detecting Extraneous Content in Podcasts
Mar 03, 2021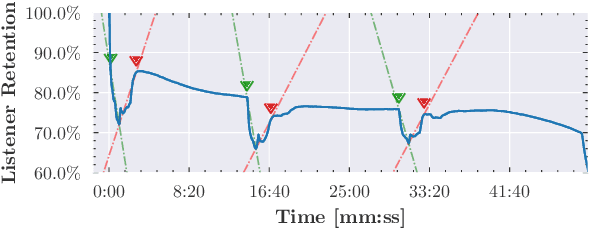
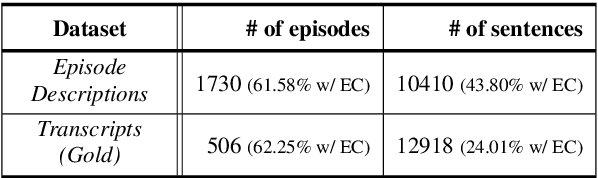
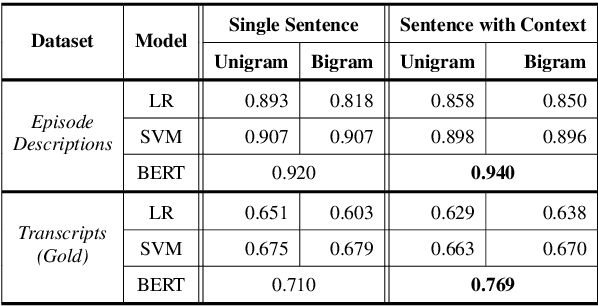
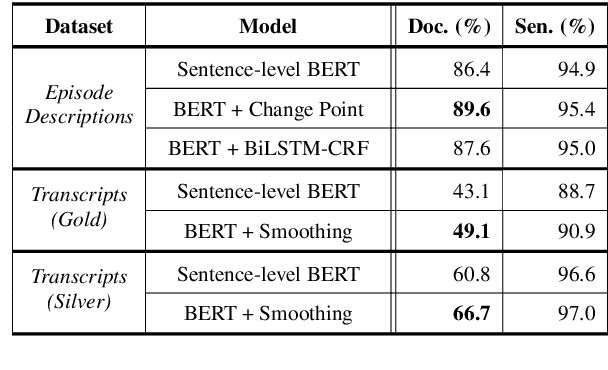
Podcast episodes often contain material extraneous to the main content, such as advertisements, interleaved within the audio and the written descriptions. We present classifiers that leverage both textual and listening patterns in order to detect such content in podcast descriptions and audio transcripts. We demonstrate that our models are effective by evaluating them on the downstream task of podcast summarization and show that we can substantively improve ROUGE scores and reduce the extraneous content generated in the summaries.
Self-Supervised Learning from Contrastive Mixtures for Personalized Speech Enhancement
Nov 06, 2020
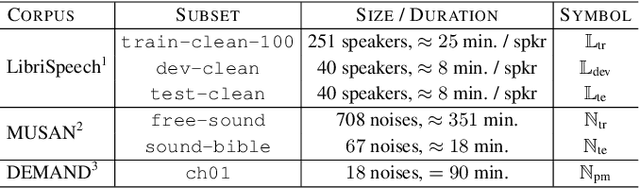


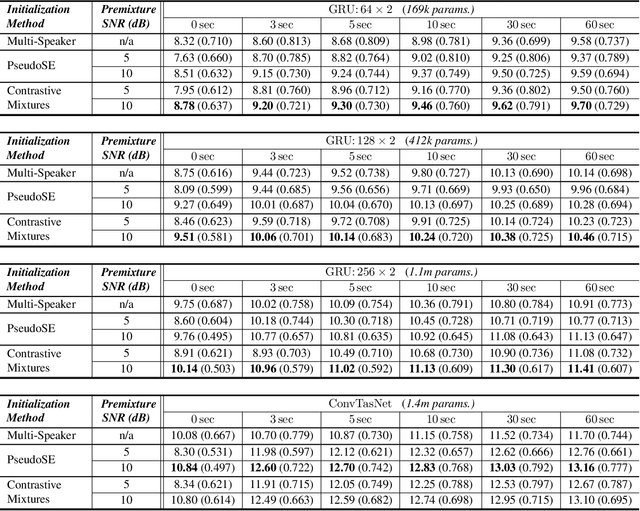
This work explores how self-supervised learning can be universally used to discover speaker-specific features towards enabling personalized speech enhancement models. We specifically address the few-shot learning scenario where access to cleaning recordings of a test-time speaker is limited to a few seconds, but noisy recordings of the speaker are abundant. We develop a simple contrastive learning procedure which treats the abundant noisy data as makeshift training targets through pairwise noise injection: the model is pretrained to maximize agreement between pairs of differently deformed identical utterances and to minimize agreement between pairs of similarly deformed nonidentical utterances. Our experiments compare the proposed pretraining approach with two baseline alternatives: speaker-agnostic fully-supervised pretraining, and speaker-specific self-supervised pretraining without contrastive loss terms. Of all three approaches, the proposed method using contrastive mixtures is found to be most robust to model compression (using 85% fewer parameters) and reduced clean speech (requiring only 3 seconds).
Sparse Mixture of Local Experts for Efficient Speech Enhancement
May 16, 2020

In this paper, we investigate a deep learning approach for speech denoising through an efficient ensemble of specialist neural networks. By splitting up the speech denoising task into non-overlapping subproblems and introducing a classifier, we are able to improve denoising performance while also reducing computational complexity. More specifically, the proposed model incorporates a gating network which assigns noisy speech signals to an appropriate specialist network based on either speech degradation level or speaker gender. In our experiments, a baseline recurrent network is compared against an ensemble of similarly-designed smaller recurrent networks regulated by the auxiliary gating network. Using stochastically generated batches from a large noisy speech corpus, the proposed model learns to estimate a time-frequency masking matrix based on the magnitude spectrogram of an input mixture signal. Both baseline and specialist networks are trained to estimate the ideal ratio mask, while the gating network is trained to perform subproblem classification. Our findings demonstrate that a fine-tuned ensemble network is able to exceed the speech denoising capabilities of a generalist network, doing so with fewer model parameters.