 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Personalized Speech Enhancement through Speaker-Informed Model Selection
Paper and Code
May 08, 2021
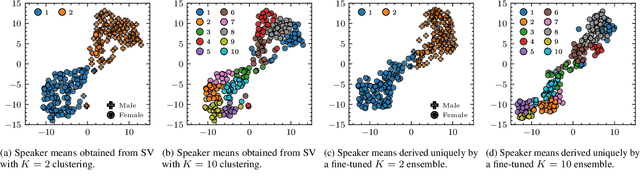
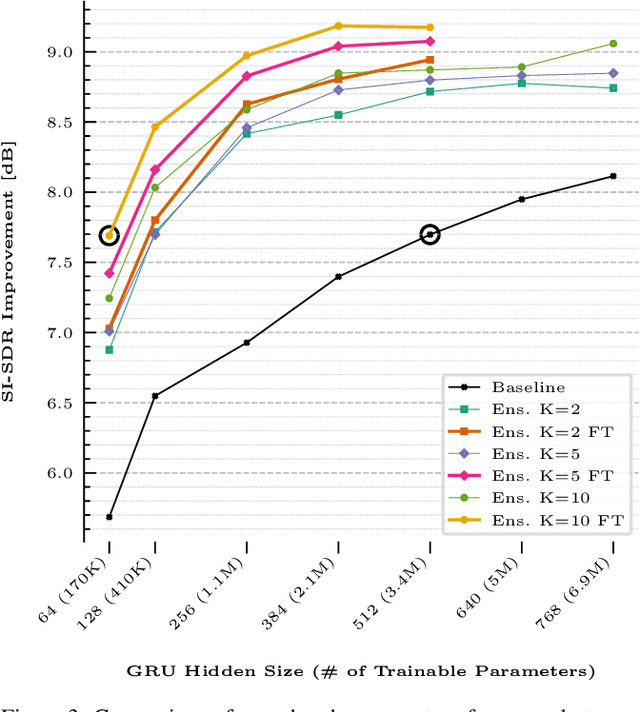
This paper presents a novel zero-shot learning approach towards personalized speech enhancement through the use of a sparsely active ensemble model. Optimizing speech denoising systems towards a particular test-time speaker can improve performance and reduce run-time complexity. However, test-time model adaptation may be challenging if collecting data from the test-time speaker is not possible. To this end, we propose using an ensemble model wherein each specialist module denoises noisy utterances from a distinct partition of training set speakers. The gating module inexpensively estimates test-time speaker characteristics in the form of an embedding vector and selects the most appropriate specialist module for denoising the test signal. Grouping the training set speakers into non-overlapping semantically similar groups is non-trivial and ill-defined. To do this, we first train a Siamese network using noisy speech pairs to maximize or minimize the similarity of its output vectors depending on whether the utterances derive from the same speaker or not. Next, we perform k-means clustering on the latent space formed by the averaged embedding vectors per training set speaker. In this way, we designate speaker groups and train specialist modules optimized around partitions of the complete training set. Our experiments show that ensemble models made up of low-capacity specialists can outperform high-capacity generalist models with greater efficiency and improved adaptation towards unseen test-time speakers.