 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning from Contrastive Mixtures for Personalized Speech Enhancement
Paper and Code
Nov 06, 2020
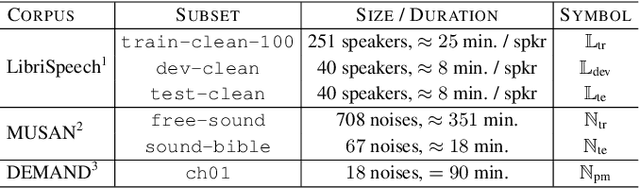


This work explores how self-supervised learning can be universally used to discover speaker-specific features towards enabling personalized speech enhancement models. We specifically address the few-shot learning scenario where access to cleaning recordings of a test-time speaker is limited to a few seconds, but noisy recordings of the speaker are abundant. We develop a simple contrastive learning procedure which treats the abundant noisy data as makeshift training targets through pairwise noise injection: the model is pretrained to maximize agreement between pairs of differently deformed identical utterances and to minimize agreement between pairs of similarly deformed nonidentical utterances. Our experiments compare the proposed pretraining approach with two baseline alternatives: speaker-agnostic fully-supervised pretraining, and speaker-specific self-supervised pretraining without contrastive loss terms. Of all three approaches, the proposed method using contrastive mixtures is found to be most robust to model compression (using 85% fewer parameters) and reduced clean speech (requiring only 3 seconds).