 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning for Personalized Speech Enhancement
Paper and Code
Apr 05, 2021


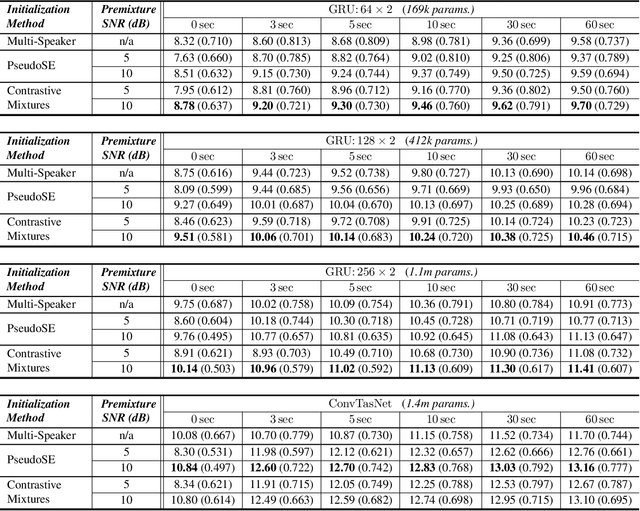
Speech enhancement systems can show improved performance by adapting the model towards a single test-time speaker. In this personalization context, the test-time user might only provide a small amount of noise-free speech data, likely insufficient for traditional fully-supervised learning. One way to overcome the lack of personal data is to transfer the model parameters from a speaker-agnostic model to initialize the personalized model, and then to finetune the model using the small amount of personal speech data. This baseline marginally adapts over the scarce clean speech data. Alternatively, we propose self-supervised methods that are designed specifically to learn personalized and discriminative features from abundant in-the-wild noisy, but still personal speech recordings. Our experiment shows that the proposed self-supervised learning methods initialize personalized speech enhancement models better than the baseline fully-supervised methods, yielding superior speech enhancement performance. The proposed methods also result in a more robust feature set under the real-world conditions: compressed model sizes and fewness of the labeled data.