 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevice-Directed Speech Detection for Follow-up Conversations Using Large Language Models
Nov 04, 2024Follow-up conversations with virtual assistants (VAs) enable a user to seamlessly interact with a VA without the need to repeatedly invoke it using a keyword (after the first query). Therefore, accurate Device-directed Speech Detection (DDSD) from the follow-up queries is critical for enabling naturalistic user experience. To this end, we explore the notion of Large Language Models (LLMs) and model the first query when making inference about the follow-ups (based on the ASR-decoded text), via prompting of a pretrained LLM, or by adapting a binary classifier on top of the LLM. In doing so, we also exploit the ASR uncertainty when designing the LLM prompts. We show on the real-world dataset of follow-up conversations that this approach yields large gains (20-40% reduction in false alarms at 10% fixed false rejects) due to the joint modeling of the previous speech context and ASR uncertainty, compared to when follow-ups are modeled alone.
Multimodal Large Language Models with Fusion Low Rank Adaptation for Device Directed Speech Detection
Jun 13, 2024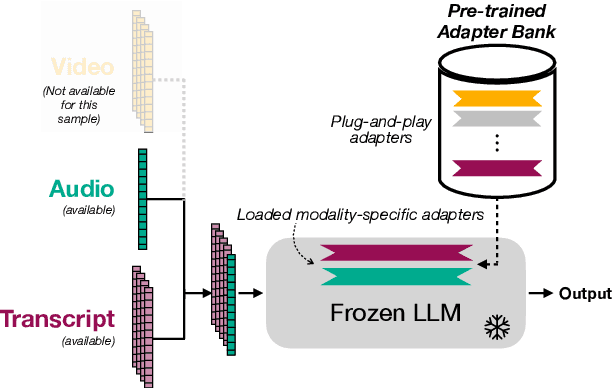
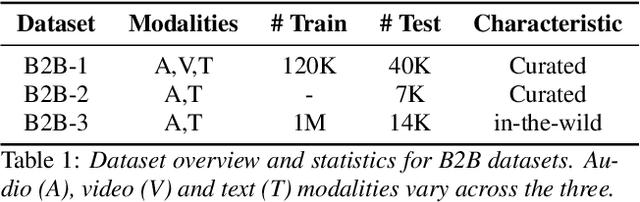
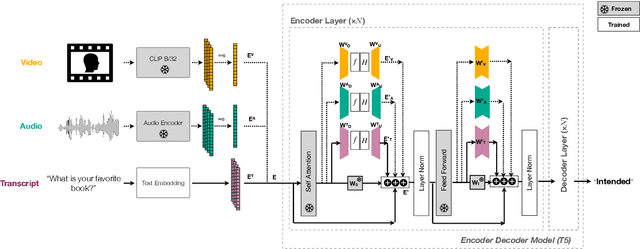
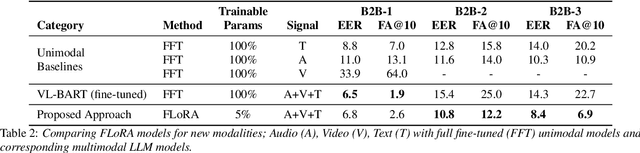
Although Large Language Models (LLMs) have shown promise for human-like conversations, they are primarily pre-trained on text data. Incorporating audio or video improves performance, but collecting large-scale multimodal data and pre-training multimodal LLMs is challenging. To this end, we propose a Fusion Low Rank Adaptation (FLoRA) technique that efficiently adapts a pre-trained unimodal LLM to consume new, previously unseen modalities via low rank adaptation. For device-directed speech detection, using FLoRA, the multimodal LLM achieves 22% relative reduction in equal error rate (EER) over the text-only approach and attains performance parity with its full fine-tuning (FFT) counterpart while needing to tune only a fraction of its parameters. Furthermore, with the newly introduced adapter dropout, FLoRA is robust to missing data, improving over FFT by 20% lower EER and 56% lower false accept rate. The proposed approach scales well for model sizes from 16M to 3B parameters.
Streaming Anchor Loss: Augmenting Supervision with Temporal Significance
Oct 09, 2023Streaming neural network models for fast frame-wise responses to various speech and sensory signals are widely adopted on resource-constrained platforms. Hence, increasing the learning capacity of such streaming models (i.e., by adding more parameters) to improve the predictive power may not be viable for real-world tasks. In this work, we propose a new loss, Streaming Anchor Loss (SAL), to better utilize the given learning capacity by encouraging the model to learn more from essential frames. More specifically, our SAL and its focal variations dynamically modulate the frame-wise cross entropy loss based on the importance of the corresponding frames so that a higher loss penalty is assigned for frames within the temporal proximity of semantically critical events. Therefore, our loss ensures that the model training focuses on predicting the relatively rare but task-relevant frames. Experimental results with standard lightweight convolutional and recurrent streaming networks on three different speech based detection tasks demonstrate that SAL enables the model to learn the overall task more effectively with improved accuracy and latency, without any additional data, model parameters, or architectural changes.
Leveraging Large Language Models for Exploiting ASR Uncertainty
Sep 12, 2023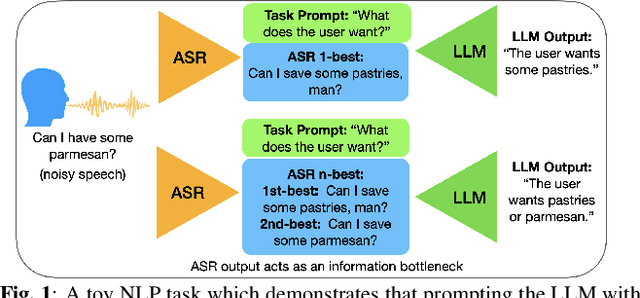


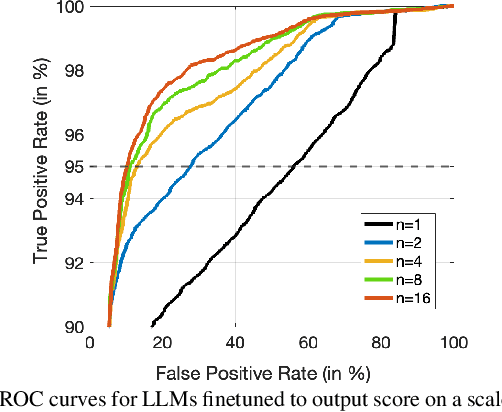
While large language models excel in a variety of natural language processing (NLP) tasks, to perform well on spoken language understanding (SLU) tasks, they must either rely on off-the-shelf automatic speech recognition (ASR) systems for transcription, or be equipped with an in-built speech modality. This work focuses on the former scenario, where LLM's accuracy on SLU tasks is constrained by the accuracy of a fixed ASR system on the spoken input. Specifically, we tackle speech-intent classification task, where a high word-error-rate can limit the LLM's ability to understand the spoken intent. Instead of chasing a high accuracy by designing complex or specialized architectures regardless of deployment costs, we seek to answer how far we can go without substantially changing the underlying ASR and LLM, which can potentially be shared by multiple unrelated tasks. To this end, we propose prompting the LLM with an n-best list of ASR hypotheses instead of only the error-prone 1-best hypothesis. We explore prompt-engineering to explain the concept of n-best lists to the LLM; followed by the finetuning of Low-Rank Adapters on the downstream tasks. Our approach using n-best lists proves to be effective on a device-directed speech detection task as well as on a keyword spotting task, where systems using n-best list prompts outperform those using 1-best ASR hypothesis; thus paving the way for an efficient method to exploit ASR uncertainty via LLMs for speech-based applications.
Automotive RADAR sub-sampling via object detection networks: Leveraging prior signal information
Feb 21, 2023


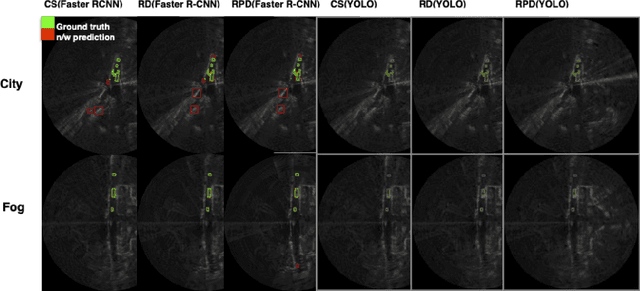
Automotive radar has increasingly attracted attention due to growing interest in autonomous driving technologies. Acquiring situational awareness using multimodal data collected at high sampling rates by various sensing devices including cameras, LiDAR, and radar requires considerable power, memory and compute resources which are often limited at an edge device. In this paper, we present a novel adaptive radar sub-sampling algorithm designed to identify regions that require more detailed/accurate reconstruction based on prior environmental conditions' knowledge, enabling near-optimal performance at considerably lower effective sampling rates. Designed to robustly perform under variable weather conditions, the algorithm was shown on the Oxford raw radar and RADIATE dataset to achieve accurate reconstruction utilizing only 10% of the original samples in good weather and 20% in extreme (snow, fog) weather conditions. A further modification of the algorithm incorporates object motion to enable reliable identification of important regions. This includes monitoring possible future occlusions caused by objects detected in the present frame. Finally, we train a YOLO network on the RADIATE dataset to perform object detection directly on RADAR data and obtain a 6.6% AP50 improvement over the baseline Faster R-CNN network.
Radiomics-Guided Global-Local Transformer for Weakly Supervised Pathology Localization in Chest X-Rays
Jul 14, 2022



Before the recent success of deep learning methods for automated medical image analysis, practitioners used handcrafted radiomic features to quantitatively describe local patches of medical images. However, extracting discriminative radiomic features relies on accurate pathology localization, which is difficult to acquire in real-world settings. Despite advances in disease classification and localization from chest X-rays, many approaches fail to incorporate clinically-informed domain knowledge. For these reasons, we propose a Radiomics-Guided Transformer (RGT) that fuses \textit{global} image information with \textit{local} knowledge-guided radiomics information to provide accurate cardiopulmonary pathology localization and classification \textit{without any bounding box annotations}. RGT consists of an image Transformer branch, a radiomics Transformer branch, and fusion layers that aggregate image and radiomic information. Using the learned self-attention of its image branch, RGT extracts a bounding box for which to compute radiomic features, which are further processed by the radiomics branch; learned image and radiomic features are then fused and mutually interact via cross-attention layers. Thus, RGT utilizes a novel end-to-end feedback loop that can bootstrap accurate pathology localization only using image-level disease labels. Experiments on the NIH ChestXRay dataset demonstrate that RGT outperforms prior works in weakly supervised disease localization (by an average margin of 3.6\% over various intersection-over-union thresholds) and classification (by 1.1\% in average area under the receiver operating characteristic curve). We publicly release our codes and pre-trained models at \url{https://github.com/VITA-Group/chext}.
Improving Voice Trigger Detection with Metric Learning
Apr 05, 2022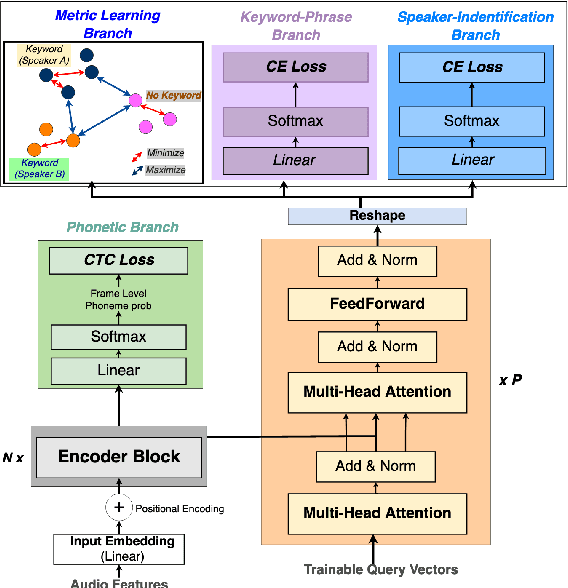

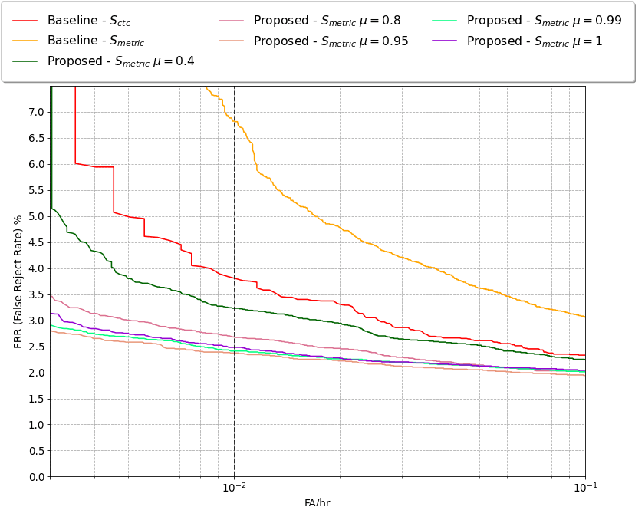
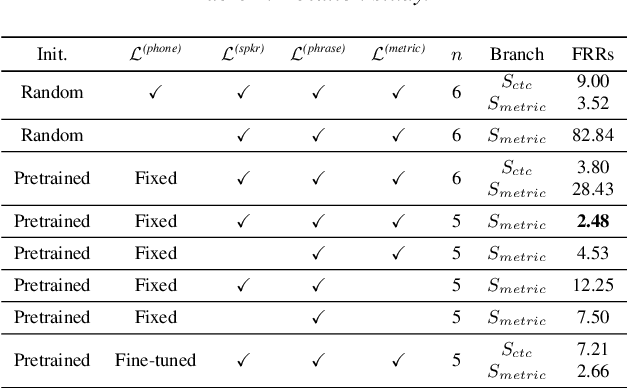
Voice trigger detection is an important task, which enables activating a voice assistant when a target user speaks a keyword phrase. A detector is typically trained on speech data independent of speaker information and used for the voice trigger detection task. However, such a speaker independent voice trigger detector typically suffers from performance degradation on speech from underrepresented groups, such as accented speakers. In this work, we propose a novel voice trigger detector that can use a small number of utterances from a target speaker to improve detection accuracy. Our proposed model employs an encoder-decoder architecture. While the encoder performs speaker independent voice trigger detection, similar to the conventional detector, the decoder predicts a personalized embedding for each utterance. A personalized voice trigger score is then obtained as a similarity score between the embeddings of enrollment utterances and a test utterance. The personalized embedding allows adapting to target speaker's speech when computing the voice trigger score, hence improving voice trigger detection accuracy. Experimental results show that the proposed approach achieves a 38% relative reduction in a false rejection rate (FRR) compared to a baseline speaker independent voice trigger model.
Device-Directed Speech Detection: Regularization via Distillation for Weakly-Supervised Models
Mar 30, 2022


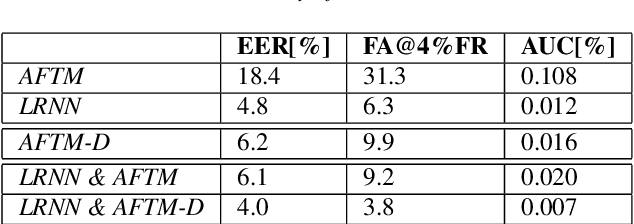
We address the problem of detecting speech directed to a device that does not contain a specific wake-word. Specifically, we focus on audio coming from a touch-based invocation. Mitigating virtual assistants (VAs) activation due to accidental button presses is critical for user experience. While the majority of approaches to false trigger mitigation (FTM) are designed to detect the presence of a target keyword, inferring user intent in absence of keyword is difficult. This also poses a challenge when creating the training/evaluation data for such systems due to inherent ambiguity in the user's data. To this end, we propose a novel FTM approach that uses weakly-labeled training data obtained with a newly introduced data sampling strategy. While this sampling strategy reduces data annotation efforts, the data labels are noisy as the data are not annotated manually. We use these data to train an acoustics-only model for the FTM task by regularizing its loss function via knowledge distillation from an ASR-based (LatticeRNN) model. This improves the model decisions, resulting in 66% gain in accuracy, as measured by equal-error-rate (EER), over the base acoustics-only model. We also show that the ensemble of the LatticeRNN and acoustic-distilled models brings further accuracy improvement of 20%.
End-to-end system for object detection from sub-sampled radar data
Mar 08, 2022


Robust and accurate sensing is of critical importance for advancing autonomous automotive systems. The need to acquire situational awareness in complex urban conditions using sensors such as radar has motivated research on power and latency-efficient signal acquisition methods. In this paper, we present an end-to-end signal processing pipeline, capable of operating in extreme weather conditions, that relies on sub-sampled radar data to perform object detection in vehicular settings. The results of the object detection are further utilized to sub-sample forthcoming radar data, which stands in contrast to prior work where the sub-sampling relies on image information. We show robust detection based on radar data reconstructed using 20% of samples under extreme weather conditions such as snow or fog, and on low-illuminated nights. Additionally, we generate 20% sampled radar data in a fine-tuning set and show 1.1% gain in AP50 across scenes and 3% AP50 gain in motorway condition.
Cross-Modal Contrastive Learning for Abnormality Classification and Localization in Chest X-rays with Radiomics using a Feedback Loop
Apr 19, 2021
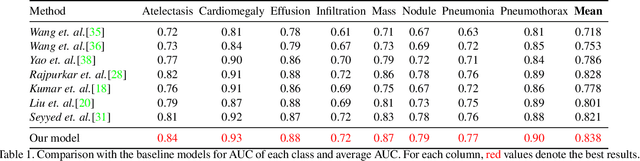
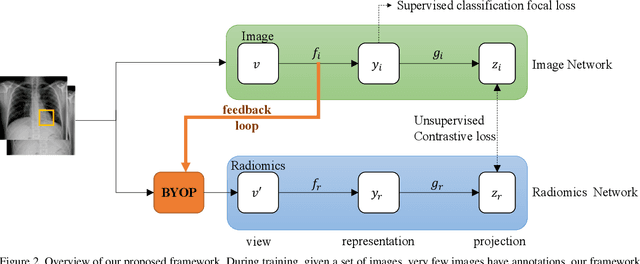
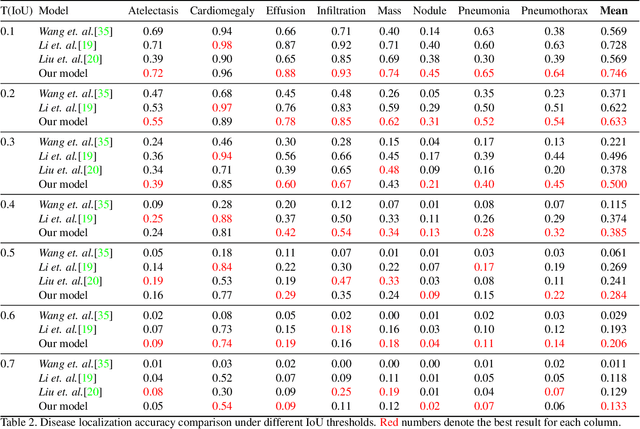
Building a highly accurate predictive model for these tasks usually requires a large number of manually annotated labels and pixel regions (bounding boxes) of abnormalities. However, it is expensive to acquire such annotations, especially the bounding boxes. Recently, contrastive learning has shown strong promise in leveraging unlabeled natural images to produce highly generalizable and discriminative features. However, extending its power to the medical image domain is under-explored and highly non-trivial, since medical images are much less amendable to data augmentations. In contrast, their domain knowledge, as well as multi-modality information, is often crucial. To bridge this gap, we propose an end-to-end semi-supervised cross-modal contrastive learning framework, that simultaneously performs disease classification and localization tasks. The key knob of our framework is a unique positive sampling approach tailored for the medical images, by seamlessly integrating radiomic features as an auxiliary modality. Specifically, we first apply an image encoder to classify the chest X-rays and to generate the image features. We next leverage Grad-CAM to highlight the crucial (abnormal) regions for chest X-rays (even when unannotated), from which we extract radiomic features. The radiomic features are then passed through another dedicated encoder to act as the positive sample for the image features generated from the same chest X-ray. In this way, our framework constitutes a feedback loop for image and radiomic modality features to mutually reinforce each other. Their contrasting yields cross-modality representations that are both robust and interpretable. Extensive experiments on the NIH Chest X-ray dataset demonstrate that our approach outperforms existing baselines in both classification and localization tasks.