 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning for End-to-End ASR by Averaging Domain Experts
May 12, 2023Continual learning for end-to-end automatic speech recognition has to contend with a number of difficulties. Fine-tuning strategies tend to lose performance on data already seen, a process known as catastrophic forgetting. On the other hand, strategies that freeze parameters and append tunable parameters must maintain multiple models. We suggest a strategy that maintains only a single model for inference and avoids catastrophic forgetting. Our experiments show that a simple linear interpolation of several models' parameters, each fine-tuned from the same generalist model, results in a single model that performs well on all tested data. For our experiments we selected two open-source end-to-end speech recognition models pre-trained on large datasets and fine-tuned them on 3 separate datasets: SGPISpeech, CORAAL, and DiPCo. The proposed average of domain experts model performs well on all tested data, and has almost no loss in performance on data from the domain of original training.
Improving Voice Trigger Detection with Metric Learning
Apr 05, 2022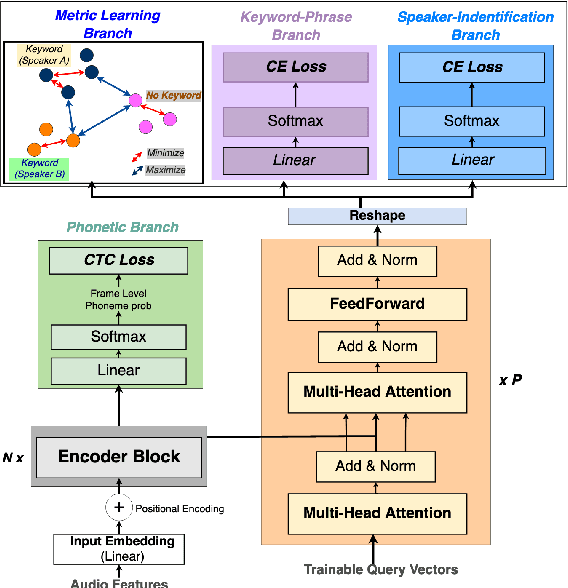

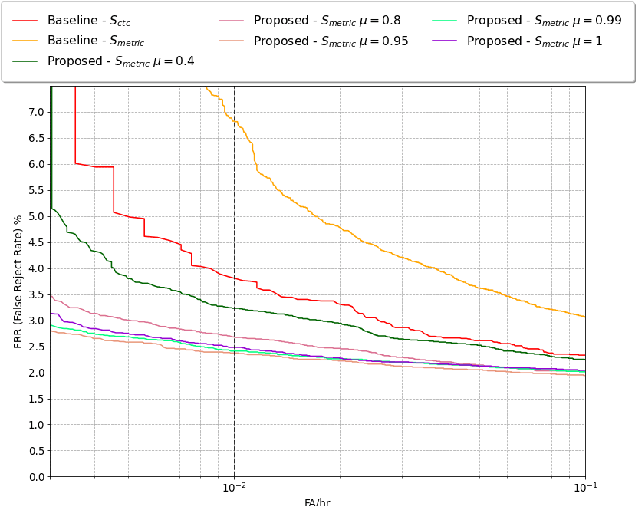
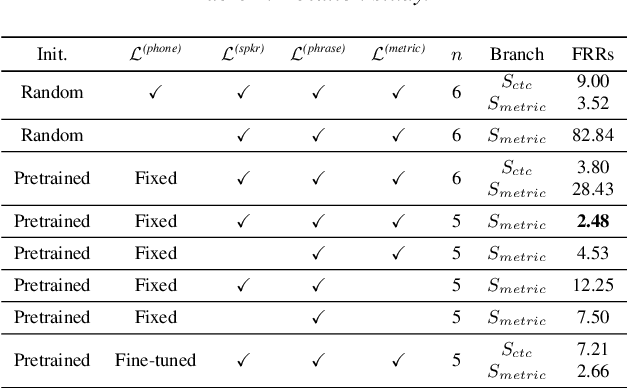
Voice trigger detection is an important task, which enables activating a voice assistant when a target user speaks a keyword phrase. A detector is typically trained on speech data independent of speaker information and used for the voice trigger detection task. However, such a speaker independent voice trigger detector typically suffers from performance degradation on speech from underrepresented groups, such as accented speakers. In this work, we propose a novel voice trigger detector that can use a small number of utterances from a target speaker to improve detection accuracy. Our proposed model employs an encoder-decoder architecture. While the encoder performs speaker independent voice trigger detection, similar to the conventional detector, the decoder predicts a personalized embedding for each utterance. A personalized voice trigger score is then obtained as a similarity score between the embeddings of enrollment utterances and a test utterance. The personalized embedding allows adapting to target speaker's speech when computing the voice trigger score, hence improving voice trigger detection accuracy. Experimental results show that the proposed approach achieves a 38% relative reduction in a false rejection rate (FRR) compared to a baseline speaker independent voice trigger model.
Device-Directed Speech Detection: Regularization via Distillation for Weakly-Supervised Models
Mar 30, 2022


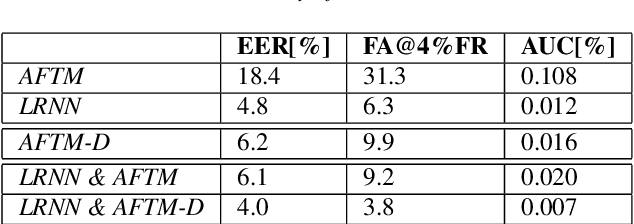
We address the problem of detecting speech directed to a device that does not contain a specific wake-word. Specifically, we focus on audio coming from a touch-based invocation. Mitigating virtual assistants (VAs) activation due to accidental button presses is critical for user experience. While the majority of approaches to false trigger mitigation (FTM) are designed to detect the presence of a target keyword, inferring user intent in absence of keyword is difficult. This also poses a challenge when creating the training/evaluation data for such systems due to inherent ambiguity in the user's data. To this end, we propose a novel FTM approach that uses weakly-labeled training data obtained with a newly introduced data sampling strategy. While this sampling strategy reduces data annotation efforts, the data labels are noisy as the data are not annotated manually. We use these data to train an acoustics-only model for the FTM task by regularizing its loss function via knowledge distillation from an ASR-based (LatticeRNN) model. This improves the model decisions, resulting in 66% gain in accuracy, as measured by equal-error-rate (EER), over the base acoustics-only model. We also show that the ensemble of the LatticeRNN and acoustic-distilled models brings further accuracy improvement of 20%.
Multi-task Learning with Cross Attention for Keyword Spotting
Jul 15, 2021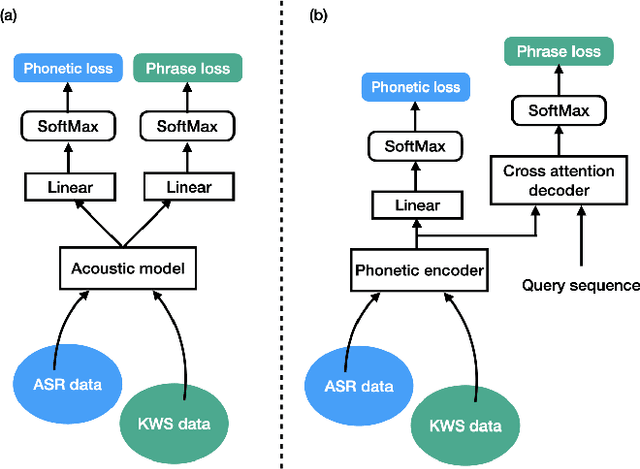
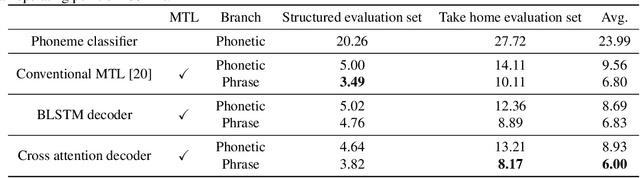
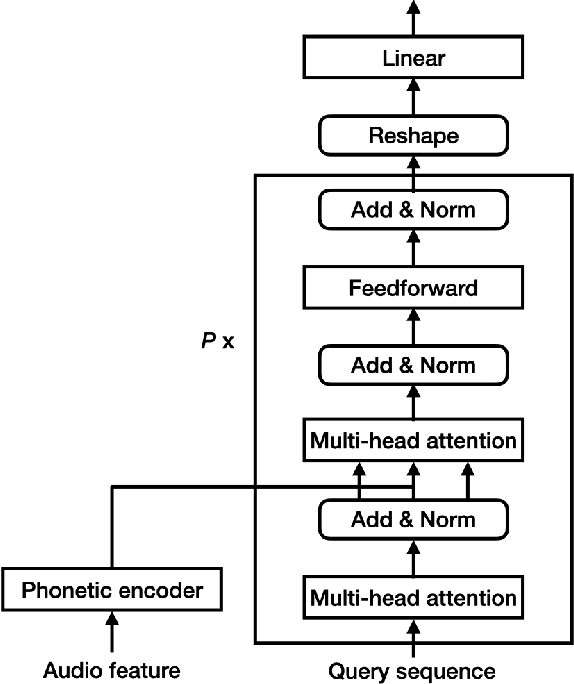
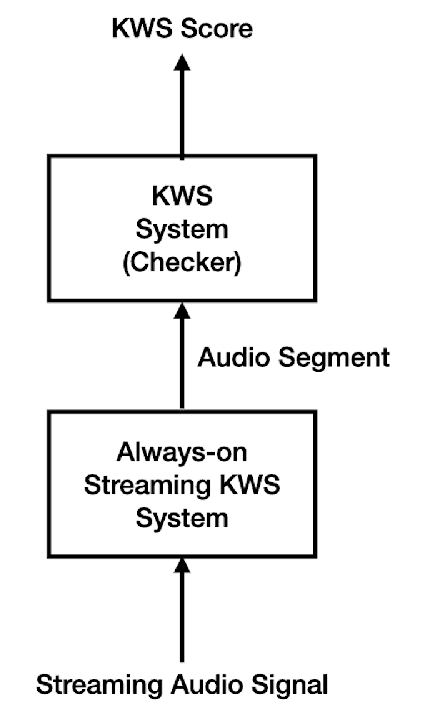
Keyword spotting (KWS) is an important technique for speech applications, which enables users to activate devices by speaking a keyword phrase. Although a phoneme classifier can be used for KWS, exploiting a large amount of transcribed data for automatic speech recognition (ASR), there is a mismatch between the training criterion (phoneme recognition) and the target task (KWS). Recently, multi-task learning has been applied to KWS to exploit both ASR and KWS training data. In this approach, an output of an acoustic model is split into two branches for the two tasks, one for phoneme transcription trained with the ASR data and one for keyword classification trained with the KWS data. In this paper, we introduce a cross attention decoder in the multi-task learning framework. Unlike the conventional multi-task learning approach with the simple split of the output layer, the cross attention decoder summarizes information from a phonetic encoder by performing cross attention between the encoder outputs and a trainable query sequence to predict a confidence score for the KWS task. Experimental results on KWS tasks show that the proposed approach outperformed the conventional multi-task learning with split branches and a bi-directional long short-team memory decoder by 12% on average.
Streaming Transformer for Hardware Efficient Voice Trigger Detection and False Trigger Mitigation
May 14, 2021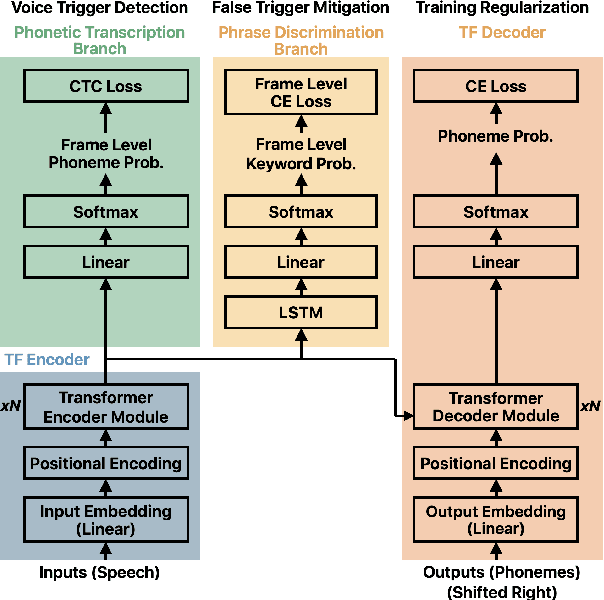
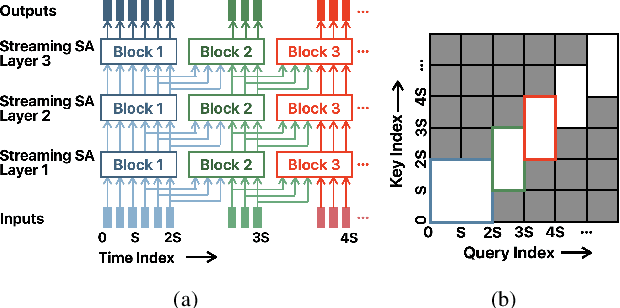

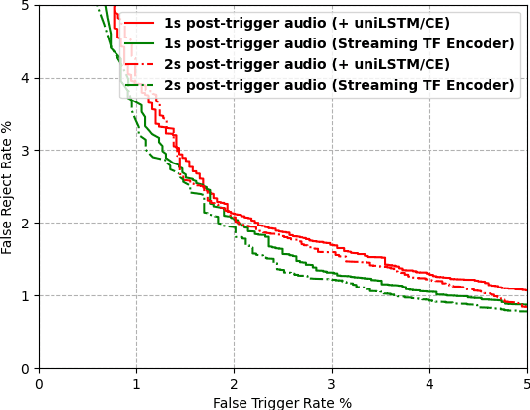
We present a unified and hardware efficient architecture for two stage voice trigger detection (VTD) and false trigger mitigation (FTM) tasks. Two stage VTD systems of voice assistants can get falsely activated to audio segments acoustically similar to the trigger phrase of interest. FTM systems cancel such activations by using post trigger audio context. Traditional FTM systems rely on automatic speech recognition lattices which are computationally expensive to obtain on device. We propose a streaming transformer (TF) encoder architecture, which progressively processes incoming audio chunks and maintains audio context to perform both VTD and FTM tasks using only acoustic features. The proposed joint model yields an average 18% relative reduction in false reject rate (FRR) for the VTD task at a given false alarm rate. Moreover, our model suppresses 95% of the false triggers with an additional one second of post-trigger audio. Finally, on-device measurements show 32% reduction in runtime memory and 56% reduction in inference time compared to non-streaming version of the model.
Dynamic curriculum learning via data parameters for noise robust keyword spotting
Feb 18, 2021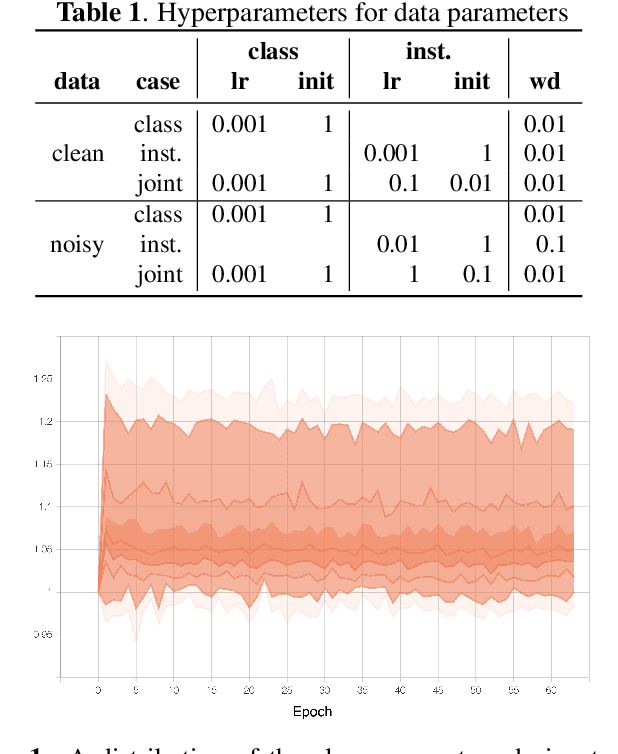
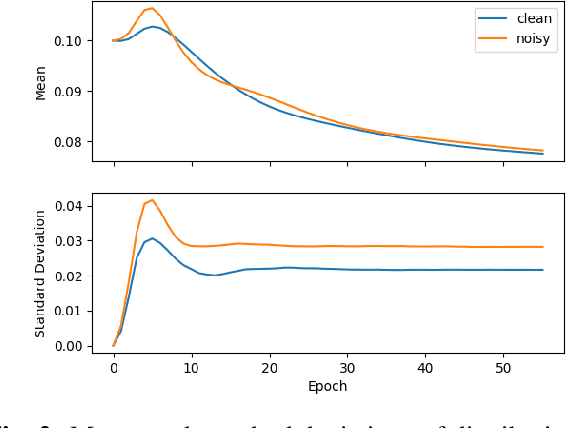
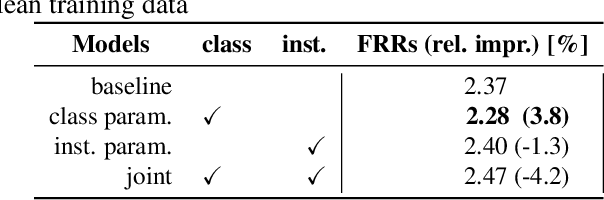

We propose dynamic curriculum learning via data parameters for noise robust keyword spotting. Data parameter learning has recently been introduced for image processing, where weight parameters, so-called data parameters, for target classes and instances are introduced and optimized along with model parameters. The data parameters scale logits and control importance over classes and instances during training, which enables automatic curriculum learning without additional annotations for training data. Similarly, in this paper, we propose using this curriculum learning approach for acoustic modeling, and train an acoustic model on clean and noisy utterances with the data parameters. The proposed approach automatically learns the difficulty of the classes and instances, e.g. due to low speech to noise ratio (SNR), in the gradient descent optimization and performs curriculum learning. This curriculum learning leads to overall improvement of the accuracy of the acoustic model. We evaluate the effectiveness of the proposed approach on a keyword spotting task. Experimental results show 7.7% relative reduction in false reject ratio with the data parameters compared to a baseline model which is simply trained on the multiconditioned dataset.
Optimize what matters: Training DNN-HMM Keyword Spotting Model Using End Metric
Nov 02, 2020

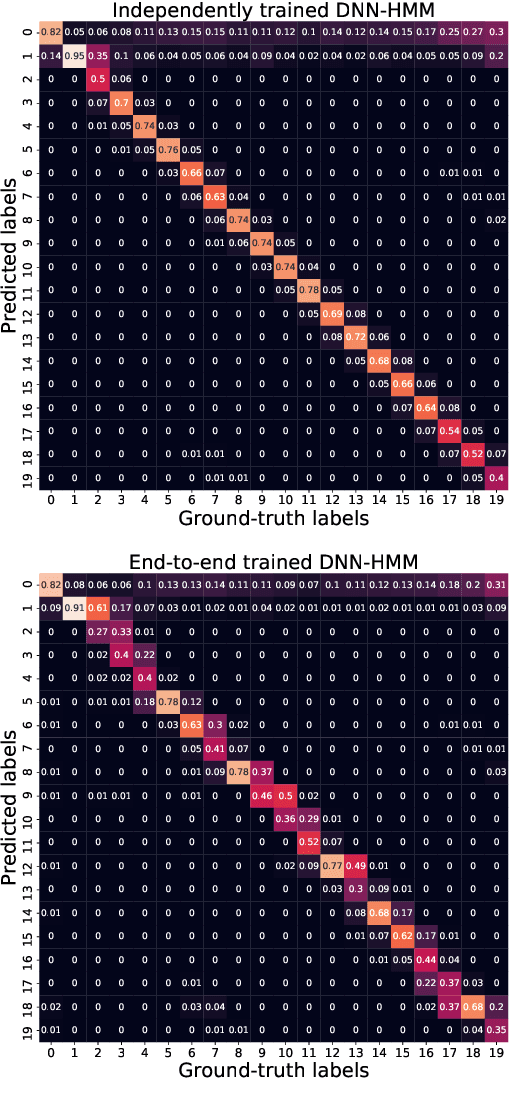
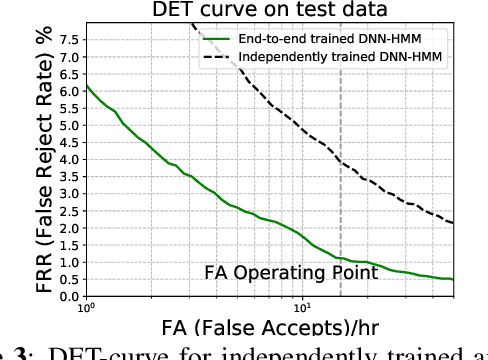
Deep Neural Network--Hidden Markov Model (DNN-HMM) based methods have been successfully used for many always-on keyword spotting algorithms that detect a wake word to trigger a device. The DNN predicts the state probabilities of a given speech frame, while HMM decoder combines the DNN predictions of multiple speech frames to compute the keyword detection score. The DNN, in prior methods, is trained independent of the HMM parameters to minimize the cross-entropy loss between the predicted and the ground-truth state probabilities. The mis-match between the DNN training loss (cross-entropy) and the end metric (detection score) is the main source of sub-optimal performance for the keyword spotting task. We address this loss-metric mismatch with a novel end-to-end training strategy that learns the DNN parameters by optimizing for the detection score. To this end, we make the HMM decoder (dynamic programming) differentiable and back-propagate through it to maximize the score for the keyword and minimize the scores for non-keyword speech segments. Our method does not require any change in the model architecture or the inference framework; therefore, there is no overhead in run-time memory or compute requirements. Moreover, we show significant reduction in false rejection rate (FRR) at the same false trigger experience (> 70% over independent DNN training).
Hybrid Transformer/CTC Networks for Hardware Efficient Voice Triggering
Aug 05, 2020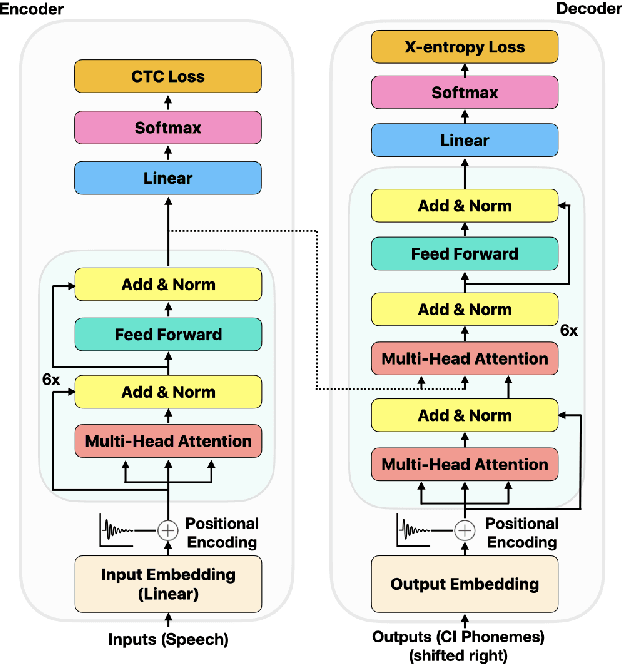
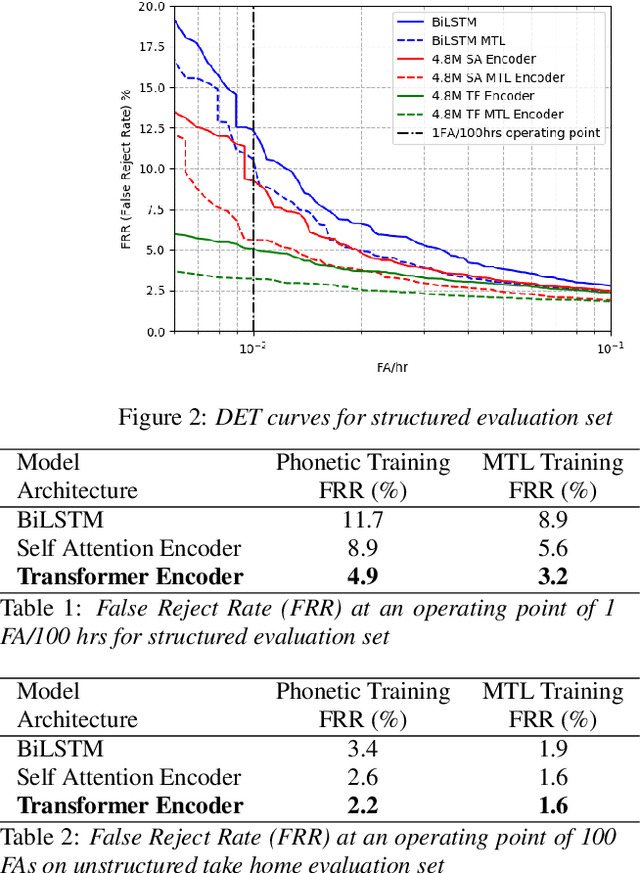
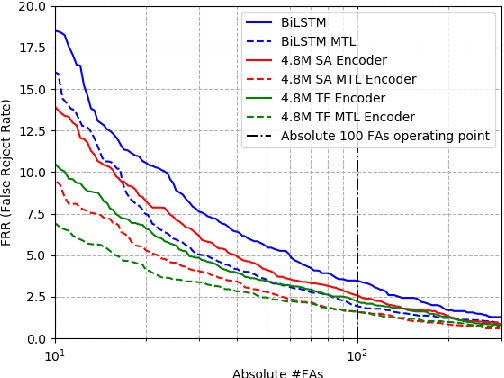
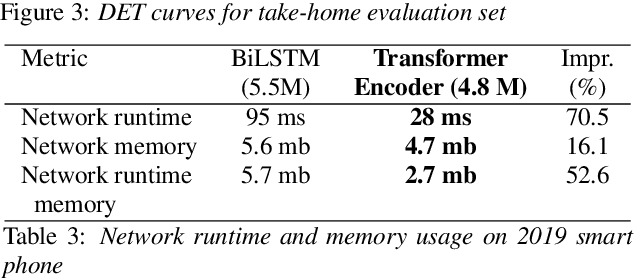
We consider the design of two-pass voice trigger detection systems. We focus on the networks in the second pass that are used to re-score candidate segments obtained from the first-pass. Our baseline is an acoustic model(AM), with BiLSTM layers, trained by minimizing the CTC loss. We replace the BiLSTM layers with self-attention layers. Results on internal evaluation sets show that self-attention networks yield better accuracy while requiring fewer parameters. We add an auto-regressive decoder network on top of the self-attention layers and jointly minimize the CTC loss on the encoder and the cross-entropy loss on the decoder. This design yields further improvements over the baseline. We retrain all the models above in a multi-task learning(MTL) setting, where one branch of a shared network is trained as an AM, while the second branch classifies the whole sequence to be true-trigger or not. Results demonstrate that networks with self-attention layers yield $\sim$60% relative reduction in false reject rates for a given false-alarm rate, while requiring 10% fewer parameters. When trained in the MTL setup, self-attention networks yield further accuracy improvements. On-device measurements show that we observe 70% relative reduction in inference time. Additionally, the proposed network architectures are $\sim$5X faster to train.
Unsupervised Style and Content Separation by Minimizing Mutual Information for Speech Synthesis
Mar 09, 2020

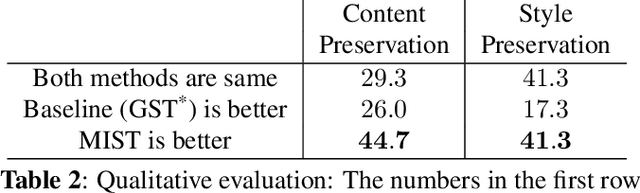

We present a method to generate speech from input text and a style vector that is extracted from a reference speech signal in an unsupervised manner, i.e., no style annotation, such as speaker information, is required. Existing unsupervised methods, during training, generate speech by computing style from the corresponding ground truth sample and use a decoder to combine the style vector with the input text. Training the model in such a way leaks content information into the style vector. The decoder can use the leaked content and ignore some of the input text to minimize the reconstruction loss. At inference time, when the reference speech does not match the content input, the output may not contain all of the content of the input text. We refer to this problem as "content leakage", which we address by explicitly estimating and minimizing the mutual information between the style and the content through an adversarial training formulation. We call our method MIST - Mutual Information based Style Content Separation. The main goal of the method is to preserve the input content in the synthesized speech signal, which we measure by the word error rate (WER) and show substantial improvements over state-of-the-art unsupervised speech synthesis methods.