 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential
Jul 16, 2025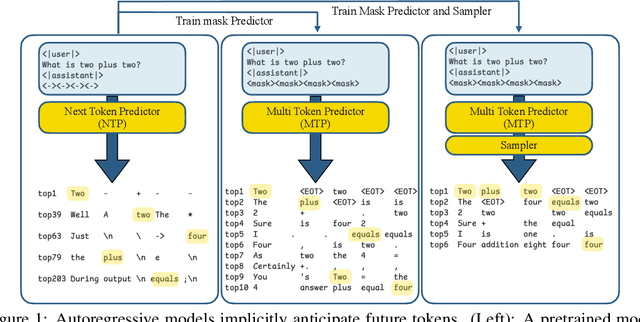
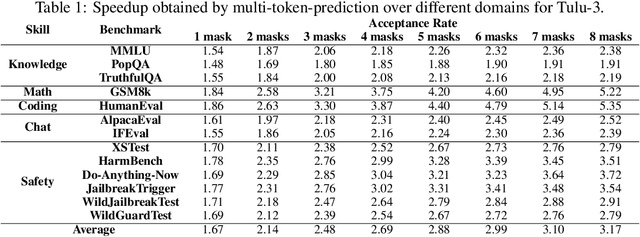
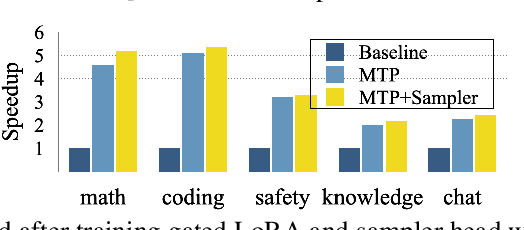
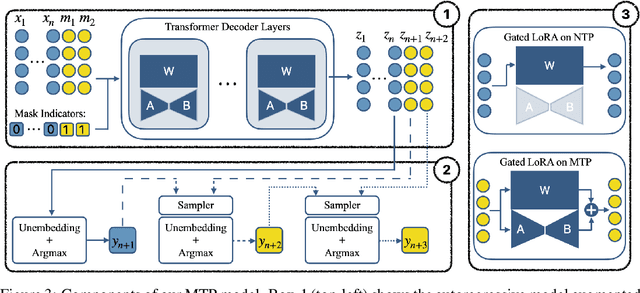
Autoregressive language models are constrained by their inherently sequential nature, generating one token at a time. This paradigm limits inference speed and parallelism, especially during later stages of generation when the direction and semantics of text are relatively certain. In this work, we propose a novel framework that leverages the inherent knowledge of vanilla autoregressive language models about future tokens, combining techniques to realize this potential and enable simultaneous prediction of multiple subsequent tokens. Our approach introduces several key innovations: (1) a masked-input formulation where multiple future tokens are jointly predicted from a common prefix; (2) a gated LoRA formulation that preserves the original LLM's functionality, while equipping it for multi-token prediction; (3) a lightweight, learnable sampler module that generates coherent sequences from the predicted future tokens; (4) a set of auxiliary training losses, including a consistency loss, to enhance the coherence and accuracy of jointly generated tokens; and (5) a speculative generation strategy that expands tokens quadratically in the future while maintaining high fidelity. Our method achieves significant speedups through supervised fine-tuning on pretrained models. For example, it generates code and math nearly 5x faster, and improves general chat and knowledge tasks by almost 2.5x. These gains come without any loss in quality.
From Dense to Dynamic: Token-Difficulty Driven MoEfication of Pre-Trained LLMs
Feb 17, 2025Training large language models (LLMs) for different inference constraints is computationally expensive, limiting control over efficiency-accuracy trade-offs. Moreover, once trained, these models typically process tokens uniformly, regardless of their complexity, leading to static and inflexible behavior. In this paper, we introduce a post-training optimization framework, DynaMoE, that adapts a pre-trained dense LLM to a token-difficulty-driven Mixture-of-Experts model with minimal fine-tuning cost. This adaptation makes the model dynamic, with sensitivity control to customize the balance between efficiency and accuracy. DynaMoE features a token-difficulty-aware router that predicts the difficulty of tokens and directs them to the appropriate sub-networks or experts, enabling larger experts to handle more complex tokens and smaller experts to process simpler ones. Our experiments demonstrate that DynaMoE can generate a range of adaptive model variants of the existing trained LLM with a single fine-tuning step, utilizing only $10B$ tokens, a minimal cost compared to the base model's training. Each variant offers distinct trade-offs between accuracy and performance. Compared to the baseline post-training optimization framework, Flextron, our method achieves similar aggregated accuracy across downstream tasks, despite using only $\frac{1}{9}\text{th}$ of their fine-tuning cost.
M2R2: Mixture of Multi-Rate Residuals for Efficient Transformer Inference
Feb 04, 2025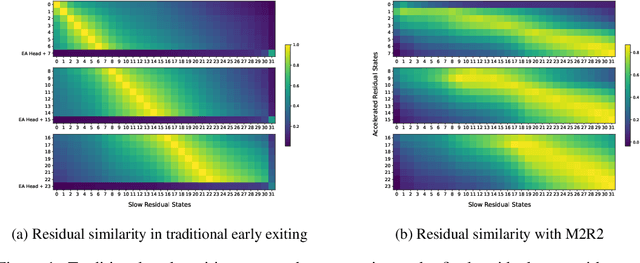
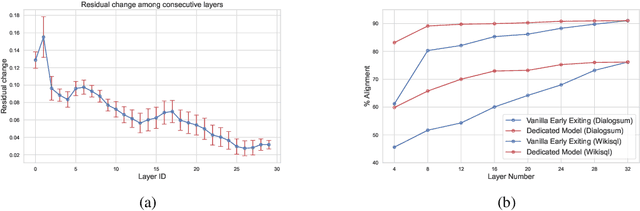
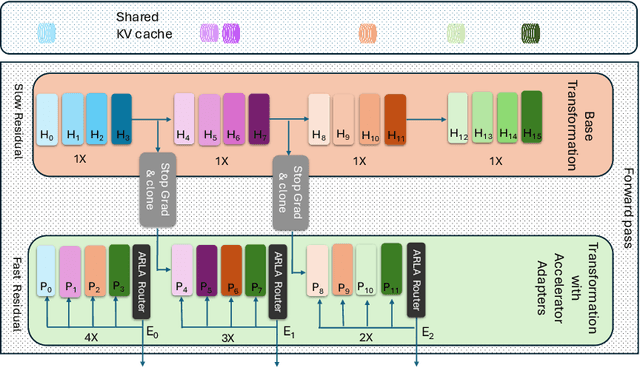
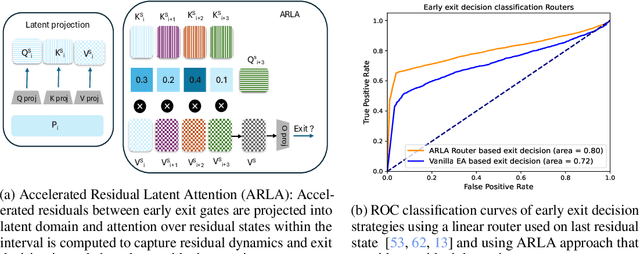
Residual transformations enhance the representational depth and expressive power of large language models (LLMs). However, applying static residual transformations across all tokens in auto-regressive generation leads to a suboptimal trade-off between inference efficiency and generation fidelity. Existing methods, including Early Exiting, Skip Decoding, and Mixture-of-Depth address this by modulating the residual transformation based on token-level complexity. Nevertheless, these approaches predominantly consider the distance traversed by tokens through the model layers, neglecting the underlying velocity of residual evolution. We introduce Mixture of Multi-rate Residuals (M2R2), a framework that dynamically modulates residual velocity to improve early alignment, enhancing inference efficiency. Evaluations on reasoning oriented tasks such as Koala, Self-Instruct, WizardLM, and MT-Bench show M2R2 surpasses state-of-the-art distance-based strategies, balancing generation quality and speedup. In self-speculative decoding setup, M2R2 achieves up to 2.8x speedups on MT-Bench, outperforming methods like 2-model speculative decoding, Medusa, LookAhead Decoding, and DEED. In Mixture-of-Experts (MoE) architectures, integrating early residual alignment with ahead-of-time expert loading into high-bandwidth memory (HBM) accelerates decoding, reduces expert-switching bottlenecks, and achieves a 2.9x speedup, making it highly effective in resource-constrained environments.
An Efficient and Streaming Audio Visual Active Speaker Detection System
Sep 13, 2024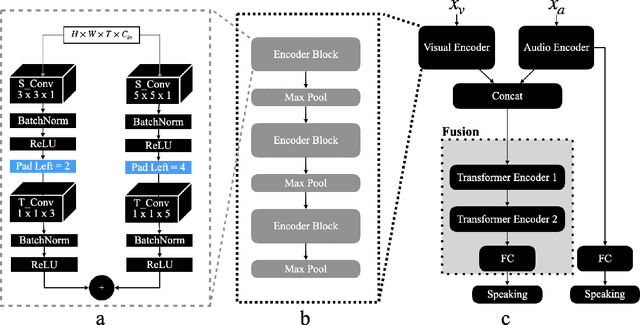


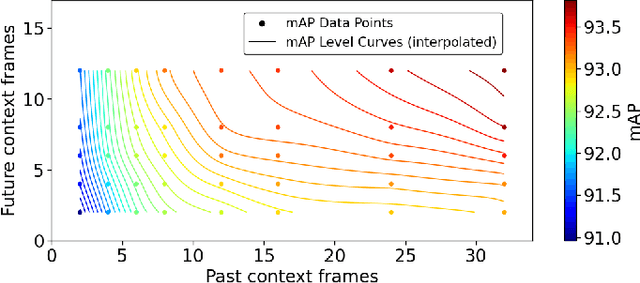
This paper delves into the challenging task of Active Speaker Detection (ASD), where the system needs to determine in real-time whether a person is speaking or not in a series of video frames. While previous works have made significant strides in improving network architectures and learning effective representations for ASD, a critical gap exists in the exploration of real-time system deployment. Existing models often suffer from high latency and memory usage, rendering them impractical for immediate applications. To bridge this gap, we present two scenarios that address the key challenges posed by real-time constraints. First, we introduce a method to limit the number of future context frames utilized by the ASD model. By doing so, we alleviate the need for processing the entire sequence of future frames before a decision is made, significantly reducing latency. Second, we propose a more stringent constraint that limits the total number of past frames the model can access during inference. This tackles the persistent memory issues associated with running streaming ASD systems. Beyond these theoretical frameworks, we conduct extensive experiments to validate our approach. Our results demonstrate that constrained transformer models can achieve performance comparable to or even better than state-of-the-art recurrent models, such as uni-directional GRUs, with a significantly reduced number of context frames. Moreover, we shed light on the temporal memory requirements of ASD systems, revealing that larger past context has a more profound impact on accuracy than future context. When profiling on a CPU we find that our efficient architecture is memory bound by the amount of past context it can use and that the compute cost is negligible as compared to the memory cost.
RepCNN: Micro-sized, Mighty Models for Wakeword Detection
Jun 04, 2024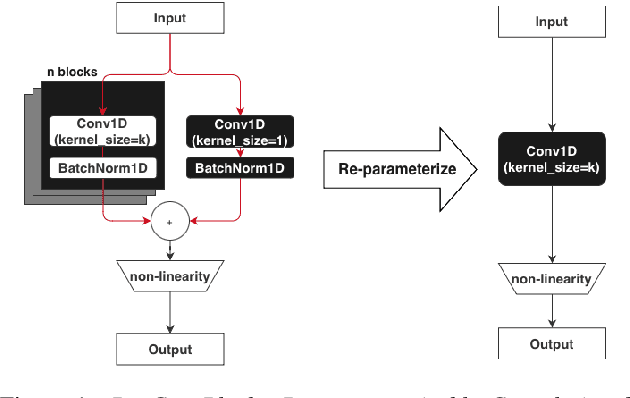

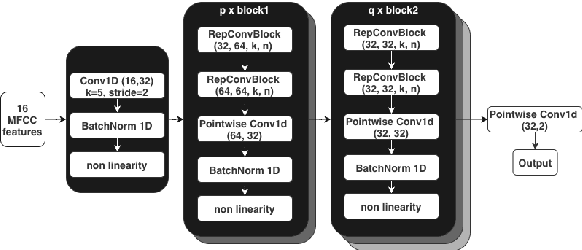

Always-on machine learning models require a very low memory and compute footprint. Their restricted parameter count limits the model's capacity to learn, and the effectiveness of the usual training algorithms to find the best parameters. Here we show that a small convolutional model can be better trained by first refactoring its computation into a larger redundant multi-branched architecture. Then, for inference, we algebraically re-parameterize the trained model into the single-branched form with fewer parameters for a lower memory footprint and compute cost. Using this technique, we show that our always-on wake-word detector model, RepCNN, provides a good trade-off between latency and accuracy during inference. RepCNN re-parameterized models are 43% more accurate than a uni-branch convolutional model while having the same runtime. RepCNN also meets the accuracy of complex architectures like BC-ResNet, while having 2x lesser peak memory usage and 10x faster runtime.
KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation
May 08, 2024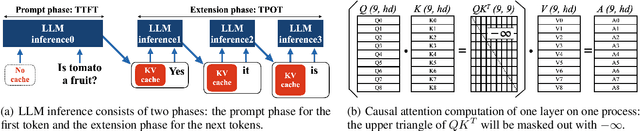

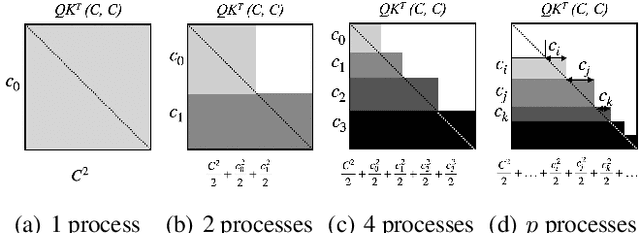
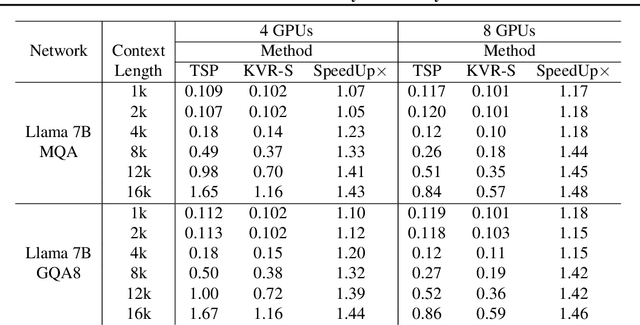
Large Language Model or LLM inference has two phases, the prompt (or prefill) phase to output the first token and the extension (or decoding) phase to the generate subsequent tokens. In this work, we propose an efficient parallelization scheme, KV-Runahead to accelerate the prompt phase. The key observation is that the extension phase generates tokens faster than the prompt phase because of key-value cache (KV-cache). Hence, KV-Runahead parallelizes the prompt phase by orchestrating multiple processes to populate the KV-cache and minimizes the time-to-first-token (TTFT). Dual-purposing the KV-cache scheme has two main benefits. Fist, since KV-cache is designed to leverage the causal attention map, we minimize computation and computation automatically. Second, since it already exists for the extension phase, KV-Runahead is easy to implement. We further propose context-level load-balancing to handle uneven KV-cache generation (due to the causal attention) and to optimize TTFT. Compared with an existing parallelization scheme such as tensor or sequential parallelization where keys and values are locally generated and exchanged via all-gather collectives, our experimental results demonstrate that KV-Runahead can offer over 1.4x and 1.6x speedups for Llama 7B and Falcon 7B respectively.
Weight subcloning: direct initialization of transformers using larger pretrained ones
Dec 14, 2023



Training large transformer models from scratch for a target task requires lots of data and is computationally demanding. The usual practice of transfer learning overcomes this challenge by initializing the model with weights of a pretrained model of the same size and specification to increase the convergence and training speed. However, what if no pretrained model of the required size is available? In this paper, we introduce a simple yet effective technique to transfer the knowledge of a pretrained model to smaller variants. Our approach called weight subcloning expedites the training of scaled-down transformers by initializing their weights from larger pretrained models. Weight subcloning involves an operation on the pretrained model to obtain the equivalent initialized scaled-down model. It consists of two key steps: first, we introduce neuron importance ranking to decrease the embedding dimension per layer in the pretrained model. Then, we remove blocks from the transformer model to match the number of layers in the scaled-down network. The result is a network ready to undergo training, which gains significant improvements in training speed compared to random initialization. For instance, we achieve 4x faster training for vision transformers in image classification and language models designed for next token prediction.
eDKM: An Efficient and Accurate Train-time Weight Clustering for Large Language Models
Sep 13, 2023Since Large Language Models or LLMs have demonstrated high-quality performance on many complex language tasks, there is a great interest in bringing these LLMs to mobile devices for faster responses and better privacy protection. However, the size of LLMs (i.e., billions of parameters) requires highly effective compression to fit into storage-limited devices. Among many compression techniques, weight-clustering, a form of non-linear quantization, is one of the leading candidates for LLM compression, and supported by modern smartphones. Yet, its training overhead is prohibitively significant for LLM fine-tuning. Especially, Differentiable KMeans Clustering, or DKM, has shown the state-of-the-art trade-off between compression ratio and accuracy regression, but its large memory complexity makes it nearly impossible to apply to train-time LLM compression. In this paper, we propose a memory-efficient DKM implementation, eDKM powered by novel techniques to reduce the memory footprint of DKM by orders of magnitudes. For a given tensor to be saved on CPU for the backward pass of DKM, we compressed the tensor by applying uniquification and sharding after checking if there is no duplicated tensor previously copied to CPU. Our experimental results demonstrate that \prjname can fine-tune and compress a pretrained LLaMA 7B model from 12.6 GB to 2.5 GB (3bit/weight) with the Alpaca dataset by reducing the train-time memory footprint of a decoder layer by 130$\times$, while delivering good accuracy on broader LLM benchmarks (i.e., 77.7% for PIQA, 66.1% for Winograde, and so on).
Improving vision-inspired keyword spotting using dynamic module skipping in streaming conformer encoder
Aug 31, 2023

Using a vision-inspired keyword spotting framework, we propose an architecture with input-dependent dynamic depth capable of processing streaming audio. Specifically, we extend a conformer encoder with trainable binary gates that allow us to dynamically skip network modules according to the input audio. Our approach improves detection and localization accuracy on continuous speech using Librispeech top-1000 most frequent words while maintaining a small memory footprint. The inclusion of gates also reduces the average amount of processing without affecting the overall performance. These benefits are shown to be even more pronounced using the Google speech commands dataset placed over background noise where up to 97% of the processing is skipped on non-speech inputs, therefore making our method particularly interesting for an always-on keyword spotter.
Flexible Keyword Spotting based on Homogeneous Audio-Text Embedding
Aug 12, 2023Spotting user-defined/flexible keywords represented in text frequently uses an expensive text encoder for joint analysis with an audio encoder in an embedding space, which can suffer from heterogeneous modality representation (i.e., large mismatch) and increased complexity. In this work, we propose a novel architecture to efficiently detect arbitrary keywords based on an audio-compliant text encoder which inherently has homogeneous representation with audio embedding, and it is also much smaller than a compatible text encoder. Our text encoder converts the text to phonemes using a grapheme-to-phoneme (G2P) model, and then to an embedding using representative phoneme vectors, extracted from the paired audio encoder on rich speech datasets. We further augment our method with confusable keyword generation to develop an audio-text embedding verifier with strong discriminative power. Experimental results show that our scheme outperforms the state-of-the-art results on Libriphrase hard dataset, increasing Area Under the ROC Curve (AUC) metric from 84.21% to 92.7% and reducing Equal-Error-Rate (EER) metric from 23.36% to 14.4%.