 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
Jun 07, 2025Recent generations of language models have introduced Large Reasoning Models (LRMs) that generate detailed thinking processes before providing answers. While these models demonstrate improved performance on reasoning benchmarks, their fundamental capabilities, scaling properties, and limitations remain insufficiently understood. Current evaluations primarily focus on established math and coding benchmarks, emphasizing final answer accuracy. However, this evaluation paradigm often suffers from contamination and does not provide insights into the reasoning traces. In this work, we systematically investigate these gaps with the help of controllable puzzle environments that allow precise manipulation of complexity while maintaining consistent logical structures. This setup enables the analysis of not only final answers but also the internal reasoning traces, offering insights into how LRMs think. Through extensive experiments, we show that LRMs face a complete accuracy collapse beyond certain complexities. Moreover, they exhibit a counterintuitive scaling limit: their reasoning effort increases with problem complexity up to a point, then declines despite having remaining token budget. By comparing LRMs with their standard LLM counterparts under same inference compute, we identify three performance regimes: (1) low-complexity tasks where standard models outperform LRMs, (2) medium-complexity tasks where LRMs demonstrates advantage, and (3) high-complexity tasks where both models face complete collapse. We found that LRMs have limitations in exact computation: they fail to use explicit algorithms and reason inconsistently across scales. We also investigate the reasoning traces in more depth, studying the patterns of explored solutions and analyzing the models' computational behavior, shedding light on their strengths, limitations, and raising questions about their reasoning capabilities.
From Dense to Dynamic: Token-Difficulty Driven MoEfication of Pre-Trained LLMs
Feb 17, 2025Training large language models (LLMs) for different inference constraints is computationally expensive, limiting control over efficiency-accuracy trade-offs. Moreover, once trained, these models typically process tokens uniformly, regardless of their complexity, leading to static and inflexible behavior. In this paper, we introduce a post-training optimization framework, DynaMoE, that adapts a pre-trained dense LLM to a token-difficulty-driven Mixture-of-Experts model with minimal fine-tuning cost. This adaptation makes the model dynamic, with sensitivity control to customize the balance between efficiency and accuracy. DynaMoE features a token-difficulty-aware router that predicts the difficulty of tokens and directs them to the appropriate sub-networks or experts, enabling larger experts to handle more complex tokens and smaller experts to process simpler ones. Our experiments demonstrate that DynaMoE can generate a range of adaptive model variants of the existing trained LLM with a single fine-tuning step, utilizing only $10B$ tokens, a minimal cost compared to the base model's training. Each variant offers distinct trade-offs between accuracy and performance. Compared to the baseline post-training optimization framework, Flextron, our method achieves similar aggregated accuracy across downstream tasks, despite using only $\frac{1}{9}\text{th}$ of their fine-tuning cost.
SALSA: Soup-based Alignment Learning for Stronger Adaptation in RLHF
Nov 04, 2024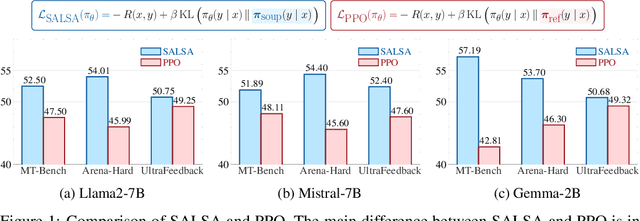


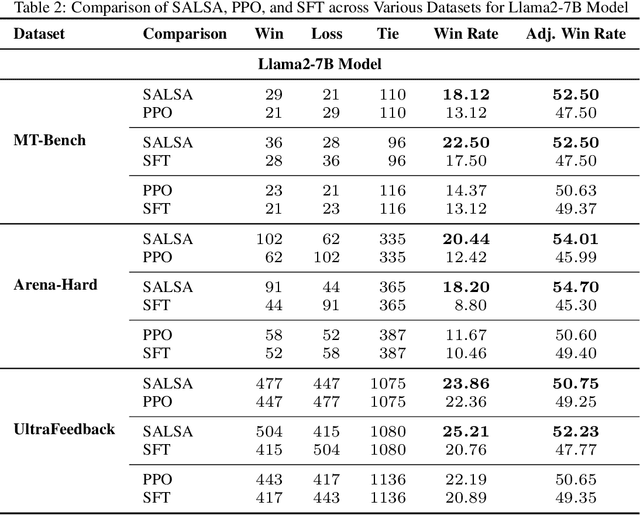
In Large Language Model (LLM) development, Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning models with human values and preferences. RLHF traditionally relies on the Kullback-Leibler (KL) divergence between the current policy and a frozen initial policy as a reference, which is added as a penalty in policy optimization algorithms like Proximal Policy Optimization (PPO). While this constraint prevents models from deviating too far from the initial checkpoint, it limits exploration of the reward landscape, reducing the model's ability to discover higher-quality solutions. As a result, policy optimization is often trapped in a narrow region of the parameter space, leading to suboptimal alignment and performance. This paper presents SALSA (Soup-based Alignment Learning for Stronger Adaptation), a novel approach designed to overcome these limitations by creating a more flexible and better located reference model through weight-space averaging of two independent supervised fine-tuned (SFT) models. This model soup allows for larger deviation in KL divergence and exploring a promising region of the solution space without sacrificing stability. By leveraging this more robust reference model, SALSA fosters better exploration, achieving higher rewards and improving model robustness, out-of-distribution generalization, and performance. We validate the effectiveness of SALSA through extensive experiments on popular open models (Llama2-7B, Mistral-7B, and Gemma-2B) across various benchmarks (MT-Bench, Arena-Hard, UltraFeedback), where it consistently surpasses PPO by fostering deeper exploration and achieving superior alignment in LLMs.
SeedLM: Compressing LLM Weights into Seeds of Pseudo-Random Generators
Oct 14, 2024



Large Language Models (LLMs) have transformed natural language processing, but face significant challenges in widespread deployment due to their high runtime cost. In this paper, we introduce SeedLM, a novel post-training compression method that uses seeds of pseudo-random generators to encode and compress model weights. Specifically, for each block of weights, we find a seed that is fed into a Linear Feedback Shift Register (LFSR) during inference to efficiently generate a random matrix. This matrix is then linearly combined with compressed coefficients to reconstruct the weight block. SeedLM reduces memory access and leverages idle compute cycles during inference, effectively speeding up memory-bound tasks by trading compute for fewer memory accesses. Unlike state-of-the-art compression methods that rely on calibration data, our approach is data-free and generalizes well across diverse tasks. Our experiments with Llama 3 70B, which is particularly challenging to compress, show that SeedLM achieves significantly better zero-shot accuracy retention at 4- and 3-bit than state-of-the-art techniques, while maintaining performance comparable to FP16 baselines. Additionally, FPGA-based tests demonstrate that 4-bit SeedLM, as model size increases to 70B, approaches a 4x speed-up over an FP16 Llama 2/3 baseline.
KV Prediction for Improved Time to First Token
Oct 10, 2024



Inference with transformer-based language models begins with a prompt processing step. In this step, the model generates the first output token and stores the KV cache needed for future generation steps. This prompt processing step can be computationally expensive, taking 10s of seconds or more for billion-parameter models on edge devices when prompt lengths or batch sizes rise. This degrades user experience by introducing significant latency into the model's outputs. To reduce the time spent producing the first output (known as the ``time to first token'', or TTFT) of a pretrained model, we introduce a novel method called KV Prediction. In our method, a small auxiliary model is used to process the prompt and produce an approximation of the KV cache used by a base model. This approximated KV cache is then used with the base model for autoregressive generation without the need to query the auxiliary model again. We demonstrate that our method produces a pareto-optimal efficiency-accuracy trade-off when compared to baselines. On TriviaQA, we demonstrate relative accuracy improvements in the range of $15\%-50\%$ across a range of TTFT FLOPs budgets. We also demonstrate accuracy improvements of up to $30\%$ on HumanEval python code completion at fixed TTFT FLOPs budgets. Additionally, we benchmark models on an Apple M2 Pro CPU and demonstrate that our improvement in FLOPs translates to a TTFT speedup on hardware. We release our code at https://github.com/apple/corenet/tree/main/projects/kv-prediction .
OpenELM: An Efficient Language Model Family with Open Training and Inference Framework
May 02, 2024The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks. To this end, we release OpenELM, a state-of-the-art open language model. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. For example, with a parameter budget of approximately one billion parameters, OpenELM exhibits a 2.36% improvement in accuracy compared to OLMo while requiring $2\times$ fewer pre-training tokens. Diverging from prior practices that only provide model weights and inference code, and pre-train on private datasets, our release includes the complete framework for training and evaluation of the language model on publicly available datasets, including training logs, multiple checkpoints, and pre-training configurations. We also release code to convert models to MLX library for inference and fine-tuning on Apple devices. This comprehensive release aims to empower and strengthen the open research community, paving the way for future open research endeavors. Our source code along with pre-trained model weights and training recipes is available at \url{https://github.com/apple/corenet}. Additionally, \model models can be found on HuggingFace at: \url{https://huggingface.co/apple/OpenELM}.
CatLIP: CLIP-level Visual Recognition Accuracy with 2.7x Faster Pre-training on Web-scale Image-Text Data
Apr 24, 2024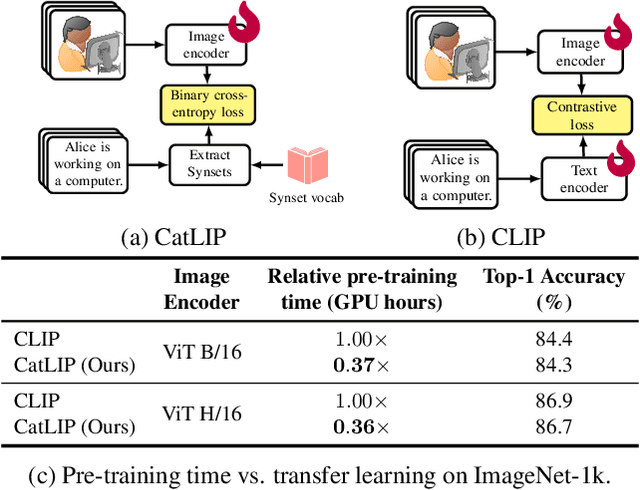

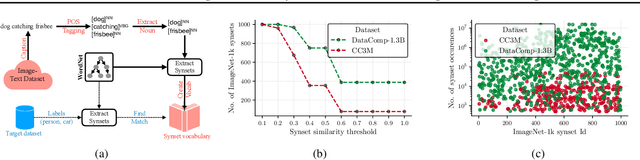
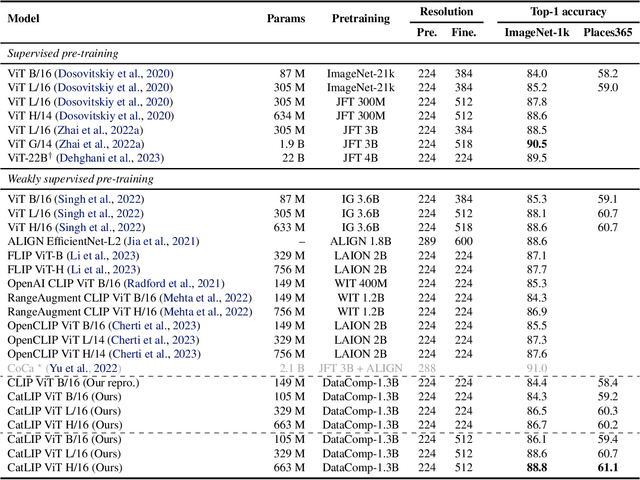
Contrastive learning has emerged as a transformative method for learning effective visual representations through the alignment of image and text embeddings. However, pairwise similarity computation in contrastive loss between image and text pairs poses computational challenges. This paper presents a novel weakly supervised pre-training of vision models on web-scale image-text data. The proposed method reframes pre-training on image-text data as a classification task. Consequently, it eliminates the need for pairwise similarity computations in contrastive loss, achieving a remarkable $2.7\times$ acceleration in training speed compared to contrastive learning on web-scale data. Through extensive experiments spanning diverse vision tasks, including detection and segmentation, we demonstrate that the proposed method maintains high representation quality. Our source code along with pre-trained model weights and training recipes is available at \url{https://github.com/apple/corenet}.
CLIP meets Model Zoo Experts: Pseudo-Supervision for Visual Enhancement
Oct 21, 2023Contrastive language image pretraining (CLIP) is a standard method for training vision-language models. While CLIP is scalable, promptable, and robust to distribution shifts on image classification tasks, it lacks object localization capabilities. This paper studies the following question: Can we augment CLIP training with task-specific vision models from model zoos to improve its visual representations? Towards this end, we leverage open-source task-specific vision models to generate pseudo-labels for an uncurated and noisy image-text dataset. Subsequently, we train CLIP models on these pseudo-labels in addition to the contrastive training on image and text pairs. This simple setup shows substantial improvements of up to 16.3% across different vision tasks, including segmentation, detection, depth estimation, and surface normal estimation. Importantly, these enhancements are achieved without compromising CLIP's existing capabilities, including its proficiency in promptable zero-shot classification.
Diffusion Models as Masked Audio-Video Learners
Oct 05, 2023



Over the past several years, the synchronization between audio and visual signals has been leveraged to learn richer audio-visual representations. Aided by the large availability of unlabeled videos, many unsupervised training frameworks have demonstrated impressive results in various downstream audio and video tasks. Recently, Masked Audio-Video Learners (MAViL) has emerged as a state-of-the-art audio-video pre-training framework. MAViL couples contrastive learning with masked autoencoding to jointly reconstruct audio spectrograms and video frames by fusing information from both modalities. In this paper, we study the potential synergy between diffusion models and MAViL, seeking to derive mutual benefits from these two frameworks. The incorporation of diffusion into MAViL, combined with various training efficiency methodologies that include the utilization of a masking ratio curriculum and adaptive batch sizing, results in a notable 32% reduction in pre-training Floating-Point Operations (FLOPS) and an 18% decrease in pre-training wall clock time. Crucially, this enhanced efficiency does not compromise the model's performance in downstream audio-classification tasks when compared to MAViL's performance.
On the Efficacy of Multi-scale Data Samplers for Vision Applications
Sep 08, 2023



Multi-scale resolution training has seen an increased adoption across multiple vision tasks, including classification and detection. Training with smaller resolutions enables faster training at the expense of a drop in accuracy. Conversely, training with larger resolutions has been shown to improve performance, but memory constraints often make this infeasible. In this paper, we empirically study the properties of multi-scale training procedures. We focus on variable batch size multi-scale data samplers that randomly sample an input resolution at each training iteration and dynamically adjust their batch size according to the resolution. Such samplers have been shown to improve model accuracy beyond standard training with a fixed batch size and resolution, though it is not clear why this is the case. We explore the properties of these data samplers by performing extensive experiments on ResNet-101 and validate our conclusions across multiple architectures, tasks, and datasets. We show that multi-scale samplers behave as implicit data regularizers and accelerate training speed. Compared to models trained with single-scale samplers, we show that models trained with multi-scale samplers retain or improve accuracy, while being better-calibrated and more robust to scaling and data distribution shifts. We additionally extend a multi-scale variable batch sampler with a simple curriculum that progressively grows resolutions throughout training, allowing for a compute reduction of more than 30%. We show that the benefits of multi-scale training extend to detection and instance segmentation tasks, where we observe a 37% reduction in training FLOPs along with a 3-4% mAP increase on MS-COCO using a Mask R-CNN model.