 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential
Jul 16, 2025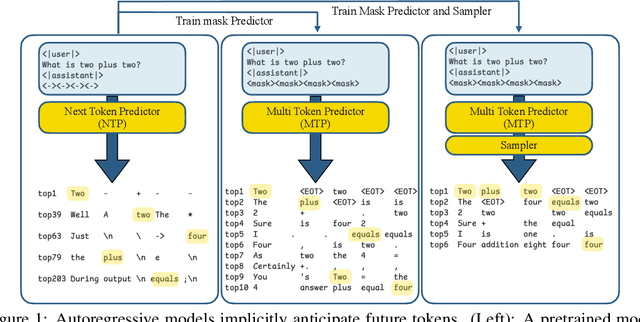
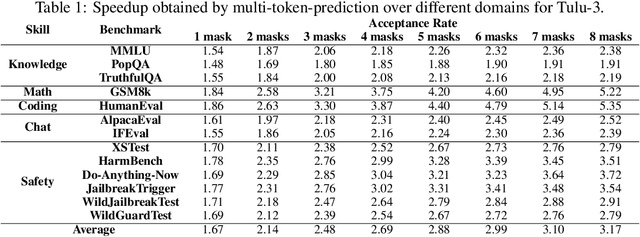
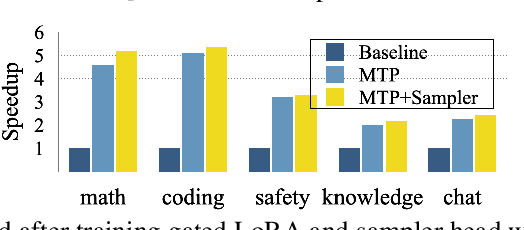
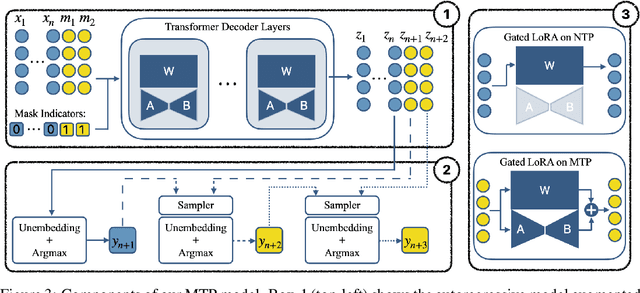
Autoregressive language models are constrained by their inherently sequential nature, generating one token at a time. This paradigm limits inference speed and parallelism, especially during later stages of generation when the direction and semantics of text are relatively certain. In this work, we propose a novel framework that leverages the inherent knowledge of vanilla autoregressive language models about future tokens, combining techniques to realize this potential and enable simultaneous prediction of multiple subsequent tokens. Our approach introduces several key innovations: (1) a masked-input formulation where multiple future tokens are jointly predicted from a common prefix; (2) a gated LoRA formulation that preserves the original LLM's functionality, while equipping it for multi-token prediction; (3) a lightweight, learnable sampler module that generates coherent sequences from the predicted future tokens; (4) a set of auxiliary training losses, including a consistency loss, to enhance the coherence and accuracy of jointly generated tokens; and (5) a speculative generation strategy that expands tokens quadratically in the future while maintaining high fidelity. Our method achieves significant speedups through supervised fine-tuning on pretrained models. For example, it generates code and math nearly 5x faster, and improves general chat and knowledge tasks by almost 2.5x. These gains come without any loss in quality.
From Dense to Dynamic: Token-Difficulty Driven MoEfication of Pre-Trained LLMs
Feb 17, 2025Training large language models (LLMs) for different inference constraints is computationally expensive, limiting control over efficiency-accuracy trade-offs. Moreover, once trained, these models typically process tokens uniformly, regardless of their complexity, leading to static and inflexible behavior. In this paper, we introduce a post-training optimization framework, DynaMoE, that adapts a pre-trained dense LLM to a token-difficulty-driven Mixture-of-Experts model with minimal fine-tuning cost. This adaptation makes the model dynamic, with sensitivity control to customize the balance between efficiency and accuracy. DynaMoE features a token-difficulty-aware router that predicts the difficulty of tokens and directs them to the appropriate sub-networks or experts, enabling larger experts to handle more complex tokens and smaller experts to process simpler ones. Our experiments demonstrate that DynaMoE can generate a range of adaptive model variants of the existing trained LLM with a single fine-tuning step, utilizing only $10B$ tokens, a minimal cost compared to the base model's training. Each variant offers distinct trade-offs between accuracy and performance. Compared to the baseline post-training optimization framework, Flextron, our method achieves similar aggregated accuracy across downstream tasks, despite using only $\frac{1}{9}\text{th}$ of their fine-tuning cost.
Improving vision-inspired keyword spotting using dynamic module skipping in streaming conformer encoder
Aug 31, 2023

Using a vision-inspired keyword spotting framework, we propose an architecture with input-dependent dynamic depth capable of processing streaming audio. Specifically, we extend a conformer encoder with trainable binary gates that allow us to dynamically skip network modules according to the input audio. Our approach improves detection and localization accuracy on continuous speech using Librispeech top-1000 most frequent words while maintaining a small memory footprint. The inclusion of gates also reduces the average amount of processing without affecting the overall performance. These benefits are shown to be even more pronounced using the Google speech commands dataset placed over background noise where up to 97% of the processing is skipped on non-speech inputs, therefore making our method particularly interesting for an always-on keyword spotter.
Flexible Keyword Spotting based on Homogeneous Audio-Text Embedding
Aug 12, 2023Spotting user-defined/flexible keywords represented in text frequently uses an expensive text encoder for joint analysis with an audio encoder in an embedding space, which can suffer from heterogeneous modality representation (i.e., large mismatch) and increased complexity. In this work, we propose a novel architecture to efficiently detect arbitrary keywords based on an audio-compliant text encoder which inherently has homogeneous representation with audio embedding, and it is also much smaller than a compatible text encoder. Our text encoder converts the text to phonemes using a grapheme-to-phoneme (G2P) model, and then to an embedding using representative phoneme vectors, extracted from the paired audio encoder on rich speech datasets. We further augment our method with confusable keyword generation to develop an audio-text embedding verifier with strong discriminative power. Experimental results show that our scheme outperforms the state-of-the-art results on Libriphrase hard dataset, increasing Area Under the ROC Curve (AUC) metric from 84.21% to 92.7% and reducing Equal-Error-Rate (EER) metric from 23.36% to 14.4%.
Matching Latent Encoding for Audio-Text based Keyword Spotting
Jun 08, 2023Using audio and text embeddings jointly for Keyword Spotting (KWS) has shown high-quality results, but the key challenge of how to semantically align two embeddings for multi-word keywords of different sequence lengths remains largely unsolved. In this paper, we propose an audio-text-based end-to-end model architecture for flexible keyword spotting (KWS), which builds upon learned audio and text embeddings. Our architecture uses a novel dynamic programming-based algorithm, Dynamic Sequence Partitioning (DSP), to optimally partition the audio sequence into the same length as the word-based text sequence using the monotonic alignment of spoken content. Our proposed model consists of an encoder block to get audio and text embeddings, a projector block to project individual embeddings to a common latent space, and an audio-text aligner containing a novel DSP algorithm, which aligns the audio and text embeddings to determine if the spoken content is the same as the text. Experimental results show that our DSP is more effective than other partitioning schemes, and the proposed architecture outperformed the state-of-the-art results on the public dataset in terms of Area Under the ROC Curve (AUC) and Equal-Error-Rate (EER) by 14.4 % and 28.9%, respectively.