 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Design Space of Tri-Modal Masked Diffusion Models
Feb 25, 2026Discrete diffusion models have emerged as strong alternatives to autoregressive language models, with recent work initializing and fine-tuning a base unimodal model for bimodal generation. Diverging from previous approaches, we introduce the first tri-modal masked diffusion model pretrained from scratch on text, image-text, and audio-text data. We systematically analyze multimodal scaling laws, modality mixing ratios, noise schedules, and batch-size effects, and we provide optimized inference sampling defaults. Our batch-size analysis yields a novel stochastic differential equation (SDE)-based reparameterization that eliminates the need for tuning the optimal batch size as reported in recent work. This reparameterization decouples the physical batch size, often chosen based on compute constraints (GPU saturation, FLOP efficiency, wall-clock time), from the logical batch size, chosen to balance gradient variance during stochastic optimization. Finally, we pretrain a preliminary 3B-parameter tri-modal model on 6.4T tokens, demonstrating the capabilities of a unified design and achieving strong results in text generation, text-to-image tasks, and text-to-speech tasks. Our work represents the largest-scale systematic open study of multimodal discrete diffusion models conducted to date, providing insights into scaling behaviors across multiple modalities.
Improving vision-inspired keyword spotting using dynamic module skipping in streaming conformer encoder
Aug 31, 2023

Using a vision-inspired keyword spotting framework, we propose an architecture with input-dependent dynamic depth capable of processing streaming audio. Specifically, we extend a conformer encoder with trainable binary gates that allow us to dynamically skip network modules according to the input audio. Our approach improves detection and localization accuracy on continuous speech using Librispeech top-1000 most frequent words while maintaining a small memory footprint. The inclusion of gates also reduces the average amount of processing without affecting the overall performance. These benefits are shown to be even more pronounced using the Google speech commands dataset placed over background noise where up to 97% of the processing is skipped on non-speech inputs, therefore making our method particularly interesting for an always-on keyword spotter.
Flexible Keyword Spotting based on Homogeneous Audio-Text Embedding
Aug 12, 2023Spotting user-defined/flexible keywords represented in text frequently uses an expensive text encoder for joint analysis with an audio encoder in an embedding space, which can suffer from heterogeneous modality representation (i.e., large mismatch) and increased complexity. In this work, we propose a novel architecture to efficiently detect arbitrary keywords based on an audio-compliant text encoder which inherently has homogeneous representation with audio embedding, and it is also much smaller than a compatible text encoder. Our text encoder converts the text to phonemes using a grapheme-to-phoneme (G2P) model, and then to an embedding using representative phoneme vectors, extracted from the paired audio encoder on rich speech datasets. We further augment our method with confusable keyword generation to develop an audio-text embedding verifier with strong discriminative power. Experimental results show that our scheme outperforms the state-of-the-art results on Libriphrase hard dataset, increasing Area Under the ROC Curve (AUC) metric from 84.21% to 92.7% and reducing Equal-Error-Rate (EER) metric from 23.36% to 14.4%.
Modality Dropout for Improved Performance-driven Talking Faces
May 27, 2020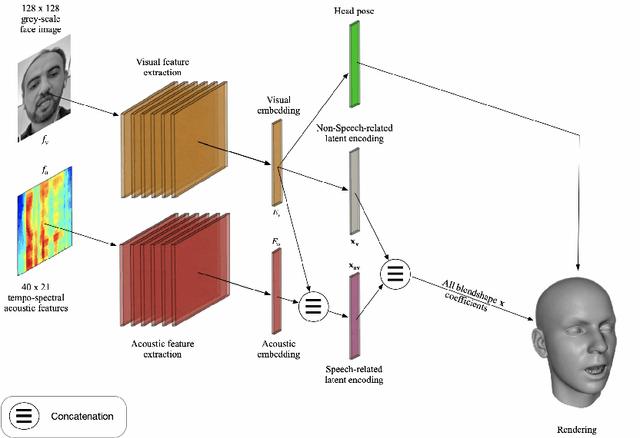



We describe our novel deep learning approach for driving animated faces using both acoustic and visual information. In particular, speech-related facial movements are generated using audiovisual information, and non-speech facial movements are generated using only visual information. To ensure that our model exploits both modalities during training, batches are generated that contain audio-only, video-only, and audiovisual input features. The probability of dropping a modality allows control over the degree to which the model exploits audio and visual information during training. Our trained model runs in real-time on resource limited hardware (e.g.\ a smart phone), it is user agnostic, and it is not dependent on a potentially error-prone transcription of the speech. We use subjective testing to demonstrate: 1) the improvement of audiovisual-driven animation over the equivalent video-only approach, and 2) the improvement in the animation of speech-related facial movements after introducing modality dropout. Before introducing dropout, viewers prefer audiovisual-driven animation in 51% of the test sequences compared with only 18% for video-driven. After introducing dropout viewer preference for audiovisual-driven animation increases to 74%, but decreases to 8% for video-only.
Speaker-Independent Speech-Driven Visual Speech Synthesis using Domain-Adapted Acoustic Models
May 15, 2019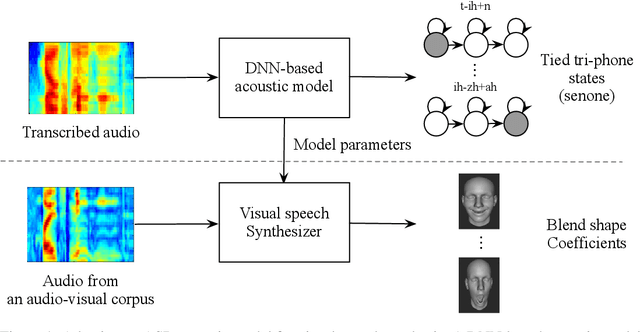

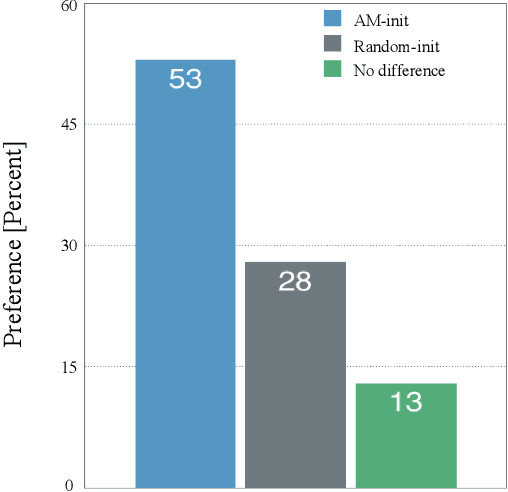
Speech-driven visual speech synthesis involves mapping features extracted from acoustic speech to the corresponding lip animation controls for a face model. This mapping can take many forms, but a powerful approach is to use deep neural networks (DNNs). However, a limitation is the lack of synchronized audio, video, and depth data required to reliably train the DNNs, especially for speaker-independent models. In this paper, we investigate adapting an automatic speech recognition (ASR) acoustic model (AM) for the visual speech synthesis problem. We train the AM on ten thousand hours of audio-only data. The AM is then adapted to the visual speech synthesis domain using ninety hours of synchronized audio-visual speech. Using a subjective assessment test, we compared the performance of the AM-initialized DNN to one with a random initialization. The results show that viewers significantly prefer animations generated from the AM-initialized DNN than the ones generated using the randomly initialized model. We conclude that visual speech synthesis can significantly benefit from the powerful representation of speech in the ASR acoustic models.