 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality Dropout for Improved Performance-driven Talking Faces
May 27, 2020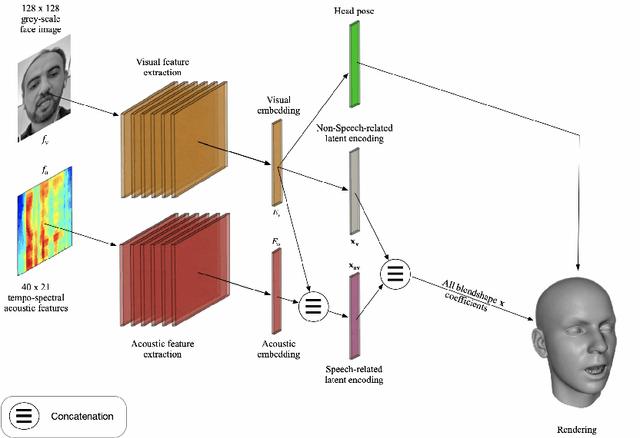



We describe our novel deep learning approach for driving animated faces using both acoustic and visual information. In particular, speech-related facial movements are generated using audiovisual information, and non-speech facial movements are generated using only visual information. To ensure that our model exploits both modalities during training, batches are generated that contain audio-only, video-only, and audiovisual input features. The probability of dropping a modality allows control over the degree to which the model exploits audio and visual information during training. Our trained model runs in real-time on resource limited hardware (e.g.\ a smart phone), it is user agnostic, and it is not dependent on a potentially error-prone transcription of the speech. We use subjective testing to demonstrate: 1) the improvement of audiovisual-driven animation over the equivalent video-only approach, and 2) the improvement in the animation of speech-related facial movements after introducing modality dropout. Before introducing dropout, viewers prefer audiovisual-driven animation in 51% of the test sequences compared with only 18% for video-driven. After introducing dropout viewer preference for audiovisual-driven animation increases to 74%, but decreases to 8% for video-only.
Speaker-Independent Speech-Driven Visual Speech Synthesis using Domain-Adapted Acoustic Models
May 15, 2019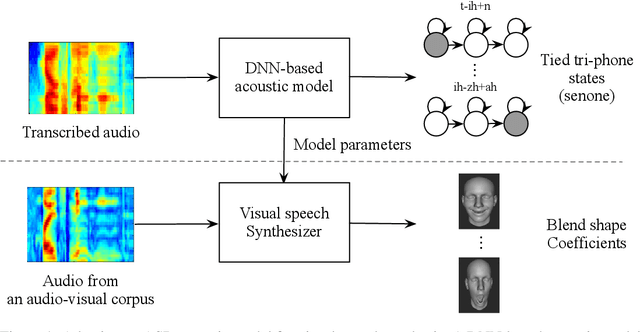

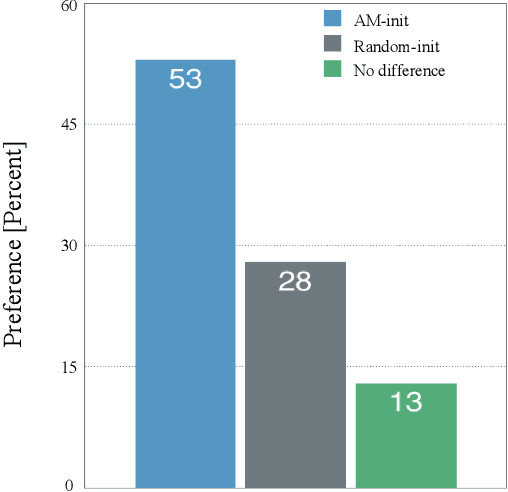
Speech-driven visual speech synthesis involves mapping features extracted from acoustic speech to the corresponding lip animation controls for a face model. This mapping can take many forms, but a powerful approach is to use deep neural networks (DNNs). However, a limitation is the lack of synchronized audio, video, and depth data required to reliably train the DNNs, especially for speaker-independent models. In this paper, we investigate adapting an automatic speech recognition (ASR) acoustic model (AM) for the visual speech synthesis problem. We train the AM on ten thousand hours of audio-only data. The AM is then adapted to the visual speech synthesis domain using ninety hours of synchronized audio-visual speech. Using a subjective assessment test, we compared the performance of the AM-initialized DNN to one with a random initialization. The results show that viewers significantly prefer animations generated from the AM-initialized DNN than the ones generated using the randomly initialized model. We conclude that visual speech synthesis can significantly benefit from the powerful representation of speech in the ASR acoustic models.