 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring neural oscillations during speech perception via surrogate gradient spiking neural networks
Apr 22, 2024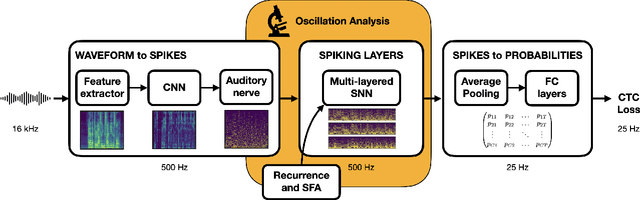
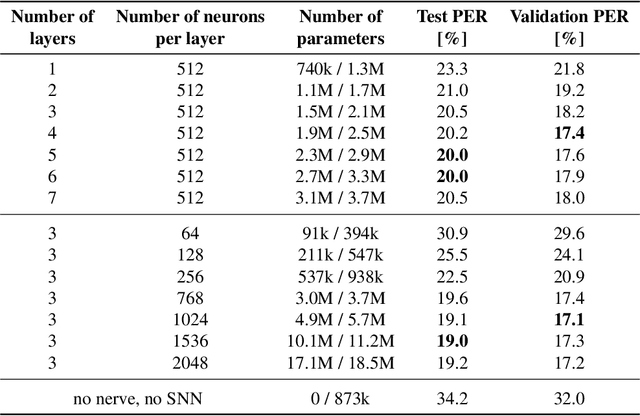

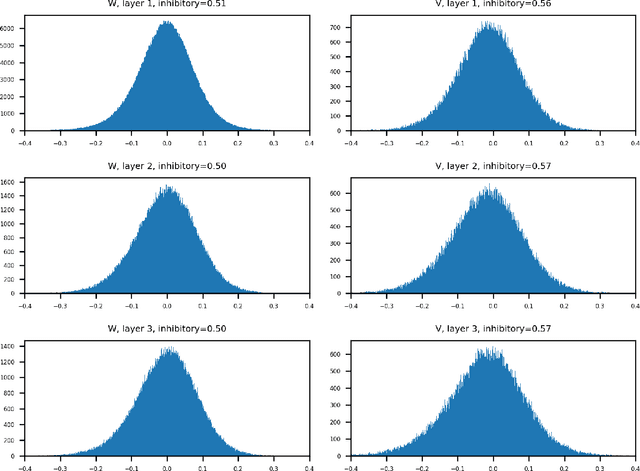
Understanding cognitive processes in the brain demands sophisticated models capable of replicating neural dynamics at large scales. We present a physiologically inspired speech recognition architecture, compatible and scalable with deep learning frameworks, and demonstrate that end-to-end gradient descent training leads to the emergence of neural oscillations in the central spiking neural network. Significant cross-frequency couplings, indicative of these oscillations, are measured within and across network layers during speech processing, whereas no such interactions are observed when handling background noise inputs. Furthermore, our findings highlight the crucial inhibitory role of feedback mechanisms, such as spike frequency adaptation and recurrent connections, in regulating and synchronising neural activity to improve recognition performance. Overall, on top of developing our understanding of synchronisation phenomena notably observed in the human auditory pathway, our architecture exhibits dynamic and efficient information processing, with relevance to neuromorphic technology.
Improving vision-inspired keyword spotting using dynamic module skipping in streaming conformer encoder
Aug 31, 2023

Using a vision-inspired keyword spotting framework, we propose an architecture with input-dependent dynamic depth capable of processing streaming audio. Specifically, we extend a conformer encoder with trainable binary gates that allow us to dynamically skip network modules according to the input audio. Our approach improves detection and localization accuracy on continuous speech using Librispeech top-1000 most frequent words while maintaining a small memory footprint. The inclusion of gates also reduces the average amount of processing without affecting the overall performance. These benefits are shown to be even more pronounced using the Google speech commands dataset placed over background noise where up to 97% of the processing is skipped on non-speech inputs, therefore making our method particularly interesting for an always-on keyword spotter.
Surrogate Gradient Spiking Neural Networks as Encoders for Large Vocabulary Continuous Speech Recognition
Dec 01, 2022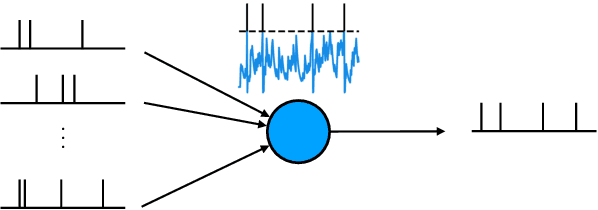

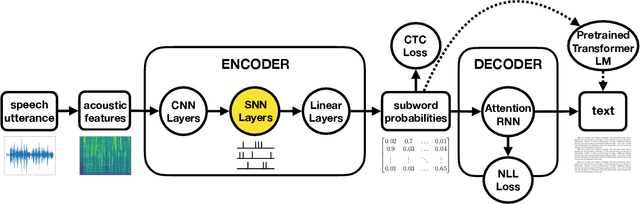

Compared to conventional artificial neurons that produce dense and real-valued responses, biologically-inspired spiking neurons transmit sparse and binary information, which can also lead to energy-efficient implementations. Recent research has shown that spiking neural networks can be trained like standard recurrent neural networks using the surrogate gradient method. They have shown promising results on speech command recognition tasks. Using the same technique, we show that they are scalable to large vocabulary continuous speech recognition, where they are capable of replacing LSTMs in the encoder with only minor loss of performance. This suggests that they may be applicable to more involved sequence-to-sequence tasks. Moreover, in contrast to their recurrent non-spiking counterparts, they show robustness to exploding gradient problems without the need to use gates.
Bayesian Recurrent Units and the Forward-Backward Algorithm
Jul 21, 2022

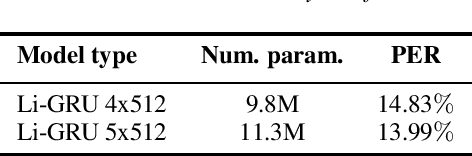
Using Bayes's theorem, we derive a unit-wise recurrence as well as a backward recursion similar to the forward-backward algorithm. The resulting Bayesian recurrent units can be integrated as recurrent neural networks within deep learning frameworks, while retaining a probabilistic interpretation from the direct correspondence with hidden Markov models. Whilst the contribution is mainly theoretical, experiments on speech recognition indicate that adding the derived units at the end of state-of-the-art recurrent architectures can improve the performance at a very low cost in terms of trainable parameters.