 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecMD: A Comprehensive Study On Speculative Expert Prefetching
Feb 03, 2026Mixture-of-Experts (MoE) models enable sparse expert activation, meaning that only a subset of the model's parameters is used during each inference. However, to translate this sparsity into practical performance, an expert caching mechanism is required. Previous works have proposed hardware-centric caching policies, but how these various caching policies interact with each other and different hardware specification remains poorly understood. To address this gap, we develop \textbf{SpecMD}, a standardized framework for benchmarking ad-hoc cache policies on various hardware configurations. Using SpecMD, we perform an exhaustive benchmarking of several MoE caching strategies, reproducing and extending prior approaches in controlled settings with realistic constraints. Our experiments reveal that MoE expert access is not consistent with temporal locality assumptions (e.g LRU, LFU). Motivated by this observation, we propose \textbf{Least-Stale}, a novel eviction policy that exploits MoE's predictable expert access patterns to reduce collision misses by up to $85\times$ over LRU. With such gains, we achieve over $88\%$ hit rates with up to $34.7\%$ Time-to-first-token (TTFT) reduction on OLMoE at only $5\%$ or $0.6GB$ of VRAM cache capacity.
Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential
Jul 16, 2025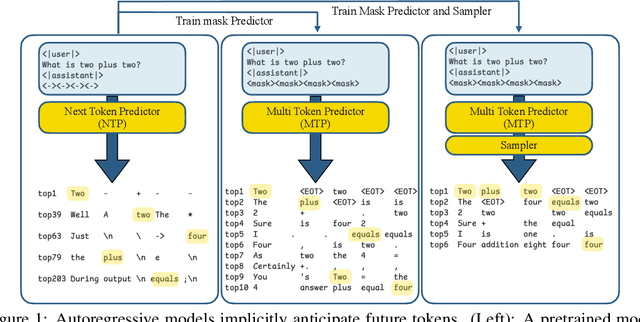
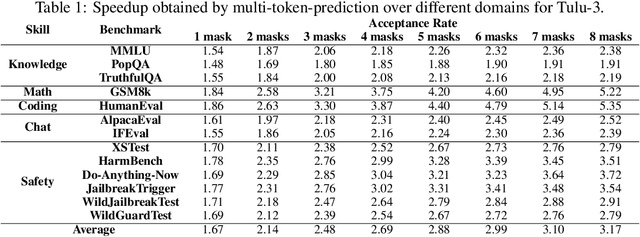
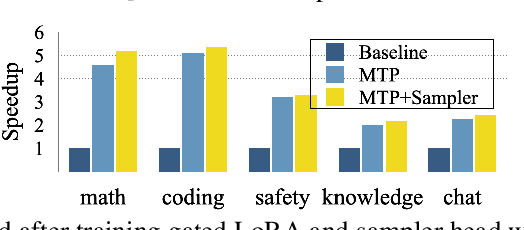
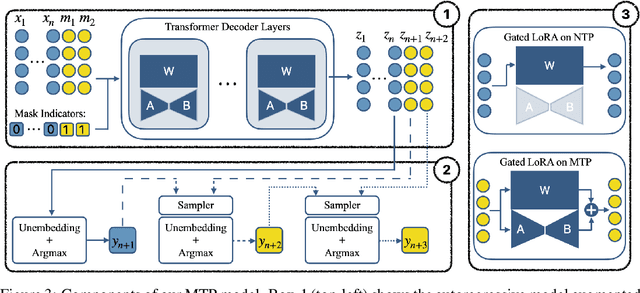
Autoregressive language models are constrained by their inherently sequential nature, generating one token at a time. This paradigm limits inference speed and parallelism, especially during later stages of generation when the direction and semantics of text are relatively certain. In this work, we propose a novel framework that leverages the inherent knowledge of vanilla autoregressive language models about future tokens, combining techniques to realize this potential and enable simultaneous prediction of multiple subsequent tokens. Our approach introduces several key innovations: (1) a masked-input formulation where multiple future tokens are jointly predicted from a common prefix; (2) a gated LoRA formulation that preserves the original LLM's functionality, while equipping it for multi-token prediction; (3) a lightweight, learnable sampler module that generates coherent sequences from the predicted future tokens; (4) a set of auxiliary training losses, including a consistency loss, to enhance the coherence and accuracy of jointly generated tokens; and (5) a speculative generation strategy that expands tokens quadratically in the future while maintaining high fidelity. Our method achieves significant speedups through supervised fine-tuning on pretrained models. For example, it generates code and math nearly 5x faster, and improves general chat and knowledge tasks by almost 2.5x. These gains come without any loss in quality.
SPD: Sync-Point Drop for efficient tensor parallelism of Large Language Models
Feb 28, 2025With the rapid expansion in the scale of large language models (LLMs), enabling efficient distributed inference across multiple computing units has become increasingly critical. However, communication overheads from popular distributed inference techniques such as Tensor Parallelism pose a significant challenge to achieve scalability and low latency. Therefore, we introduce a novel optimization technique, Sync-Point Drop (SPD), to reduce communication overheads in tensor parallelism by selectively dropping synchronization on attention outputs. In detail, we first propose a block design that allows execution to proceed without communication through SPD. Second, we apply different SPD strategies to attention blocks based on their sensitivity to the model accuracy. The proposed methods effectively alleviate communication bottlenecks while minimizing accuracy degradation during LLM inference, offering a scalable solution for diverse distributed environments: SPD offered about 20% overall inference latency reduction with < 1% accuracy regression for LLaMA2-70B inference over 8 GPUs.
Weight subcloning: direct initialization of transformers using larger pretrained ones
Dec 14, 2023



Training large transformer models from scratch for a target task requires lots of data and is computationally demanding. The usual practice of transfer learning overcomes this challenge by initializing the model with weights of a pretrained model of the same size and specification to increase the convergence and training speed. However, what if no pretrained model of the required size is available? In this paper, we introduce a simple yet effective technique to transfer the knowledge of a pretrained model to smaller variants. Our approach called weight subcloning expedites the training of scaled-down transformers by initializing their weights from larger pretrained models. Weight subcloning involves an operation on the pretrained model to obtain the equivalent initialized scaled-down model. It consists of two key steps: first, we introduce neuron importance ranking to decrease the embedding dimension per layer in the pretrained model. Then, we remove blocks from the transformer model to match the number of layers in the scaled-down network. The result is a network ready to undergo training, which gains significant improvements in training speed compared to random initialization. For instance, we achieve 4x faster training for vision transformers in image classification and language models designed for next token prediction.
Improving vision-inspired keyword spotting using dynamic module skipping in streaming conformer encoder
Aug 31, 2023

Using a vision-inspired keyword spotting framework, we propose an architecture with input-dependent dynamic depth capable of processing streaming audio. Specifically, we extend a conformer encoder with trainable binary gates that allow us to dynamically skip network modules according to the input audio. Our approach improves detection and localization accuracy on continuous speech using Librispeech top-1000 most frequent words while maintaining a small memory footprint. The inclusion of gates also reduces the average amount of processing without affecting the overall performance. These benefits are shown to be even more pronounced using the Google speech commands dataset placed over background noise where up to 97% of the processing is skipped on non-speech inputs, therefore making our method particularly interesting for an always-on keyword spotter.
I see what you hear: a vision-inspired method to localize words
Oct 24, 2022This paper explores the possibility of using visual object detection techniques for word localization in speech data. Object detection has been thoroughly studied in the contemporary literature for visual data. Noting that an audio can be interpreted as a 1-dimensional image, object localization techniques can be fundamentally useful for word localization. Building upon this idea, we propose a lightweight solution for word detection and localization. We use bounding box regression for word localization, which enables our model to detect the occurrence, offset, and duration of keywords in a given audio stream. We experiment with LibriSpeech and train a model to localize 1000 words. Compared to existing work, our method reduces model size by 94%, and improves the F1 score by 6.5\%.
Trojan Signatures in DNN Weights
Sep 07, 2021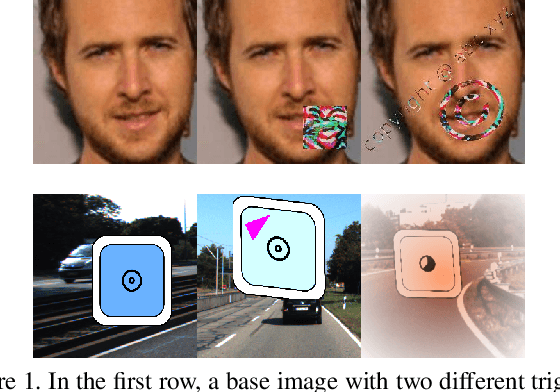
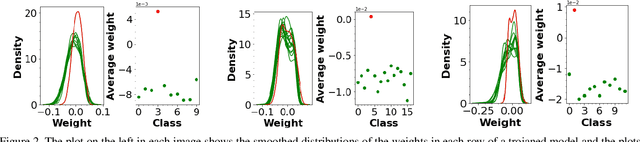
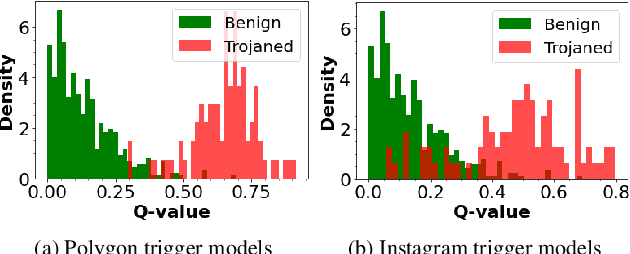
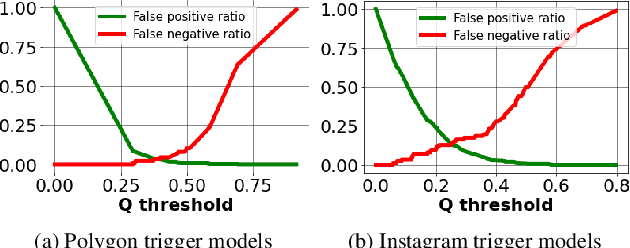
Deep neural networks have been shown to be vulnerable to backdoor, or trojan, attacks where an adversary has embedded a trigger in the network at training time such that the model correctly classifies all standard inputs, but generates a targeted, incorrect classification on any input which contains the trigger. In this paper, we present the first ultra light-weight and highly effective trojan detection method that does not require access to the training/test data, does not involve any expensive computations, and makes no assumptions on the nature of the trojan trigger. Our approach focuses on analysis of the weights of the final, linear layer of the network. We empirically demonstrate several characteristics of these weights that occur frequently in trojaned networks, but not in benign networks. In particular, we show that the distribution of the weights associated with the trojan target class is clearly distinguishable from the weights associated with other classes. Using this, we demonstrate the effectiveness of our proposed detection method against state-of-the-art attacks across a variety of architectures, datasets, and trigger types.
Unsupervised Information Obfuscation for Split Inference of Neural Networks
Apr 23, 2021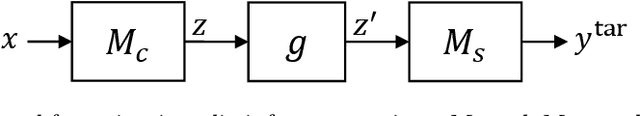
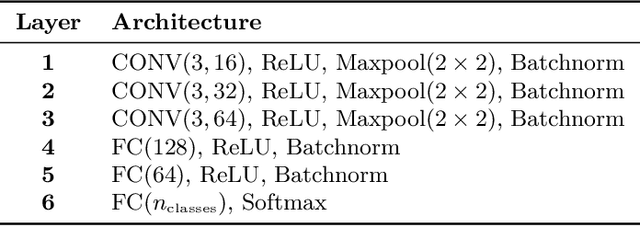

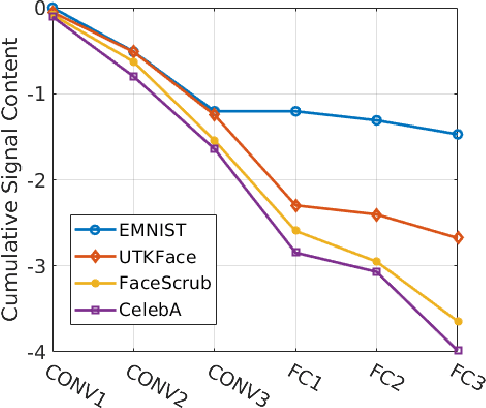
Splitting network computations between the edge device and a server enables low edge-compute inference of neural networks but might expose sensitive information about the test query to the server. To address this problem, existing techniques train the model to minimize information leakage for a given set of sensitive attributes. In practice, however, the test queries might contain attributes that are not foreseen during training. We propose instead an unsupervised obfuscation method to discard the information irrelevant to the main task. We formulate the problem via an information theoretical framework and derive an analytical solution for a given distortion to the model output. In our method, the edge device runs the model up to a split layer determined based on its computational capacity. It then obfuscates the obtained feature vector based on the first layer of the server model by removing the components in the null space as well as the low-energy components of the remaining signal. Our experimental results show that our method outperforms existing techniques in removing the information of the irrelevant attributes and maintaining the accuracy on the target label. We also show that our method reduces the communication cost and incurs only a small computational overhead.
CLEANN: Accelerated Trojan Shield for Embedded Neural Networks
Sep 04, 2020
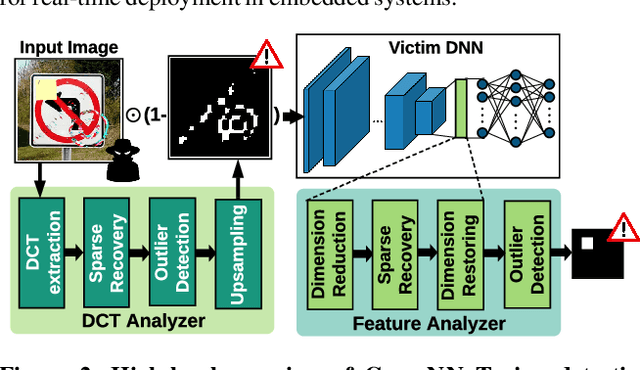

We propose CLEANN, the first end-to-end framework that enables online mitigation of Trojans for embedded Deep Neural Network (DNN) applications. A Trojan attack works by injecting a backdoor in the DNN while training; during inference, the Trojan can be activated by the specific backdoor trigger. What differentiates CLEANN from the prior work is its lightweight methodology which recovers the ground-truth class of Trojan samples without the need for labeled data, model retraining, or prior assumptions on the trigger or the attack. We leverage dictionary learning and sparse approximation to characterize the statistical behavior of benign data and identify Trojan triggers. CLEANN is devised based on algorithm/hardware co-design and is equipped with specialized hardware to enable efficient real-time execution on resource-constrained embedded platforms. Proof of concept evaluations on CLEANN for the state-of-the-art Neural Trojan attacks on visual benchmarks demonstrate its competitive advantage in terms of attack resiliency and execution overhead.
GeneCAI: Genetic Evolution for Acquiring Compact AI
Apr 14, 2020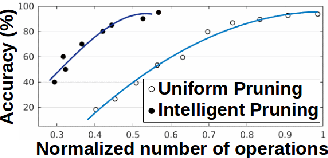
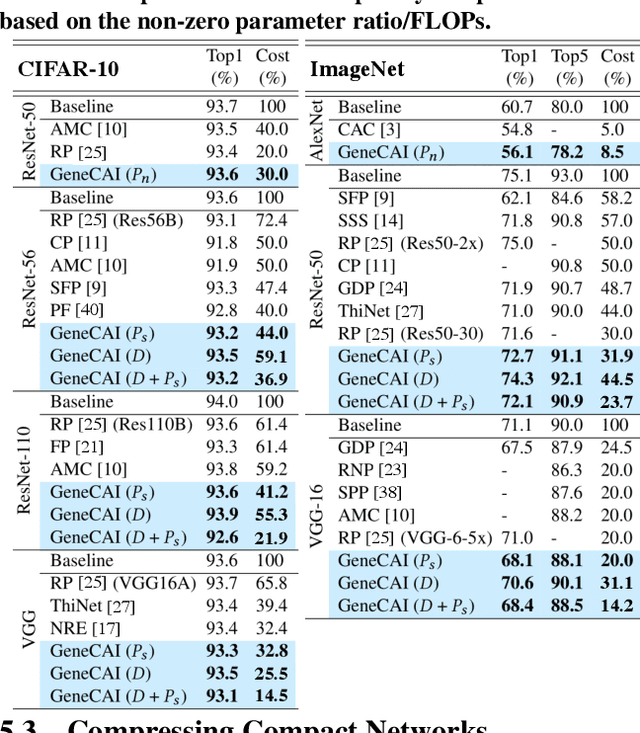


In the contemporary big data realm, Deep Neural Networks (DNNs) are evolving towards more complex architectures to achieve higher inference accuracy. Model compression techniques can be leveraged to efficiently deploy such compute-intensive architectures on resource-limited mobile devices. Such methods comprise various hyper-parameters that require per-layer customization to ensure high accuracy. Choosing such hyper-parameters is cumbersome as the pertinent search space grows exponentially with model layers. This paper introduces GeneCAI, a novel optimization method that automatically learns how to tune per-layer compression hyper-parameters. We devise a bijective translation scheme that encodes compressed DNNs to the genotype space. The optimality of each genotype is measured using a multi-objective score based on accuracy and number of floating point operations. We develop customized genetic operations to iteratively evolve the non-dominated solutions towards the optimal Pareto front, thus, capturing the optimal trade-off between model accuracy and complexity. GeneCAI optimization method is highly scalable and can achieve a near-linear performance boost on distributed multi-GPU platforms. Our extensive evaluations demonstrate that GeneCAI outperforms existing rule-based and reinforcement learning methods in DNN compression by finding models that lie on a better accuracy-complexity Pareto curve.