 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-reasoning Technical Report
Apr 30, 2025We introduce Phi-4-reasoning, a 14-billion parameter reasoning model that achieves strong performance on complex reasoning tasks. Trained via supervised fine-tuning of Phi-4 on carefully curated set of "teachable" prompts-selected for the right level of complexity and diversity-and reasoning demonstrations generated using o3-mini, Phi-4-reasoning generates detailed reasoning chains that effectively leverage inference-time compute. We further develop Phi-4-reasoning-plus, a variant enhanced through a short phase of outcome-based reinforcement learning that offers higher performance by generating longer reasoning traces. Across a wide range of reasoning tasks, both models outperform significantly larger open-weight models such as DeepSeek-R1-Distill-Llama-70B model and approach the performance levels of full DeepSeek-R1 model. Our comprehensive evaluations span benchmarks in math and scientific reasoning, coding, algorithmic problem solving, planning, and spatial understanding. Interestingly, we observe a non-trivial transfer of improvements to general-purpose benchmarks as well. In this report, we provide insights into our training data, our training methodologies, and our evaluations. We show that the benefit of careful data curation for supervised fine-tuning (SFT) extends to reasoning language models, and can be further amplified by reinforcement learning (RL). Finally, our evaluation points to opportunities for improving how we assess the performance and robustness of reasoning models.
Phi-4 Technical Report
Dec 12, 2024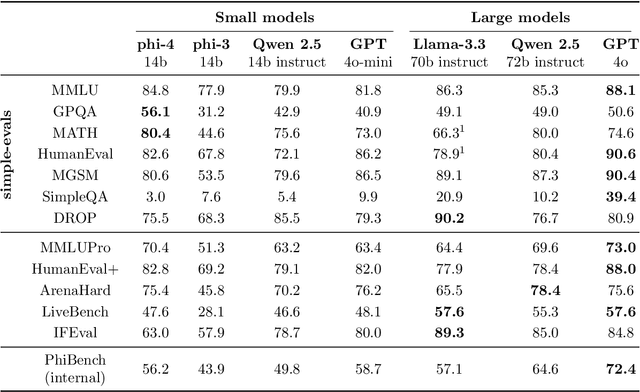
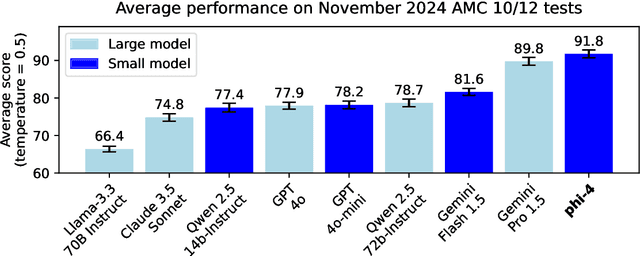

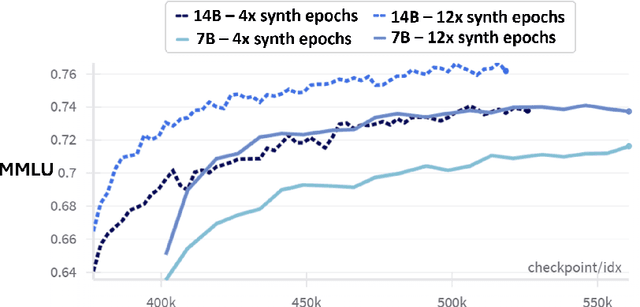
We present phi-4, a 14-billion parameter language model developed with a training recipe that is centrally focused on data quality. Unlike most language models, where pre-training is based primarily on organic data sources such as web content or code, phi-4 strategically incorporates synthetic data throughout the training process. While previous models in the Phi family largely distill the capabilities of a teacher model (specifically GPT-4), phi-4 substantially surpasses its teacher model on STEM-focused QA capabilities, giving evidence that our data-generation and post-training techniques go beyond distillation. Despite minimal changes to the phi-3 architecture, phi-4 achieves strong performance relative to its size -- especially on reasoning-focused benchmarks -- due to improved data, training curriculum, and innovations in the post-training scheme.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Textbooks Are All You Need
Jun 20, 2023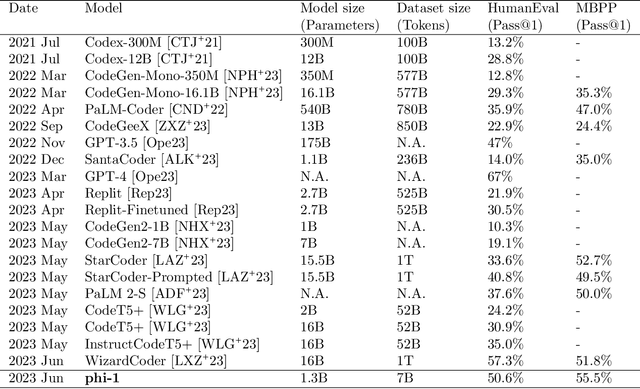
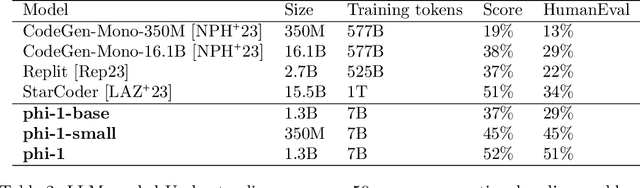
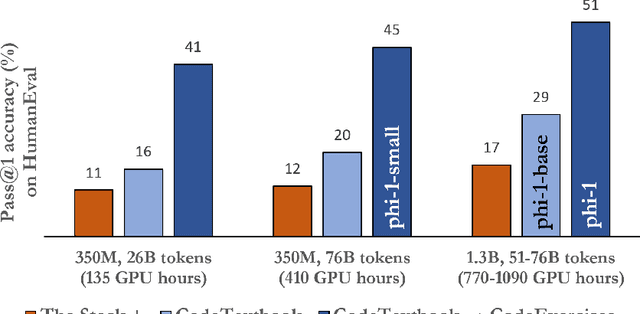
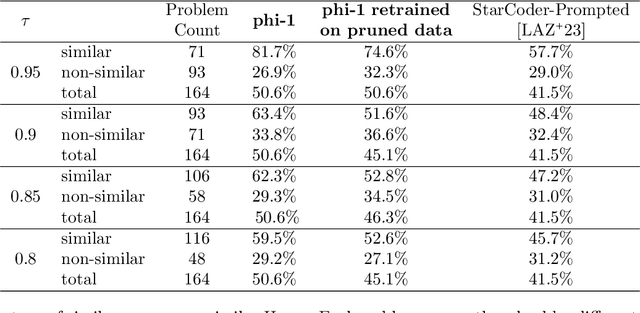
We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of ``textbook quality" data from the web (6B tokens) and synthetically generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as phi-1 that still achieves 45% on HumanEval.
NetFlick: Adversarial Flickering Attacks on Deep Learning Based Video Compression
Apr 04, 2023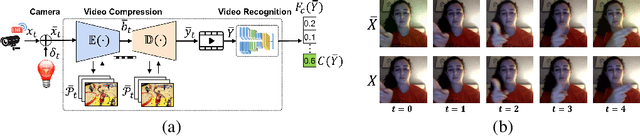
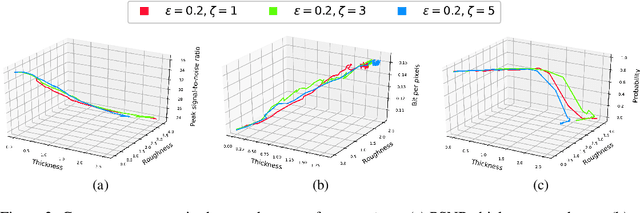
Video compression plays a significant role in IoT devices for the efficient transport of visual data while satisfying all underlying bandwidth constraints. Deep learning-based video compression methods are rapidly replacing traditional algorithms and providing state-of-the-art results on edge devices. However, recently developed adversarial attacks demonstrate that digitally crafted perturbations can break the Rate-Distortion relationship of video compression. In this work, we present a real-world LED attack to target video compression frameworks. Our physically realizable attack, dubbed NetFlick, can degrade the spatio-temporal correlation between successive frames by injecting flickering temporal perturbations. In addition, we propose universal perturbations that can downgrade performance of incoming video without prior knowledge of the contents. Experimental results demonstrate that NetFlick can successfully deteriorate the performance of video compression frameworks in both digital- and physical-settings and can be further extended to attack downstream video classification networks.
zPROBE: Zero Peek Robustness Checks for Federated Learning
Jun 24, 2022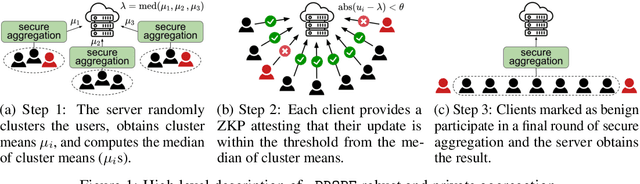
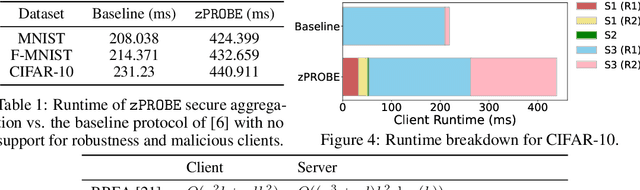
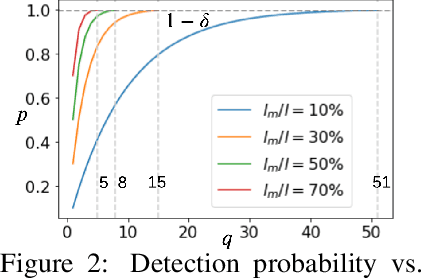
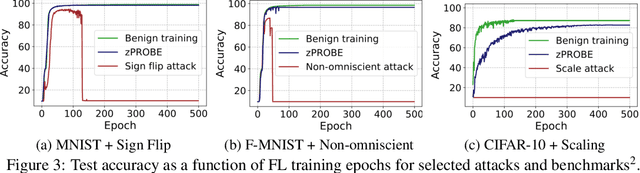
Privacy-preserving federated learning allows multiple users to jointly train a model with coordination of a central server. The server only learns the final aggregation result, thereby preventing leakage of the users' (private) training data from the individual model updates. However, keeping the individual updates private allows malicious users to perform Byzantine attacks and degrade the model accuracy without being detected. Best existing defenses against Byzantine workers rely on robust rank-based statistics, e.g., the median, to find malicious updates. However, implementing privacy-preserving rank-based statistics is nontrivial and unscalable in the secure domain, as it requires sorting of all individual updates. We establish the first private robustness check that uses high break point rank-based statistics on aggregated model updates. By exploiting randomized clustering, we significantly improve the scalability of our defense without compromising privacy. We leverage the derived statistical bounds in zero-knowledge proofs to detect and remove malicious updates without revealing the private user updates. Our novel framework, zPROBE, enables Byzantine resilient and secure federated learning. Empirical evaluations demonstrate that zPROBE provides a low overhead solution to defend against state-of-the-art Byzantine attacks while preserving privacy.
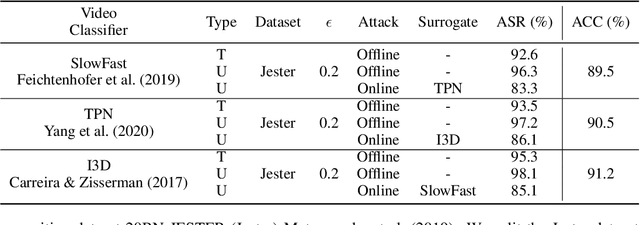
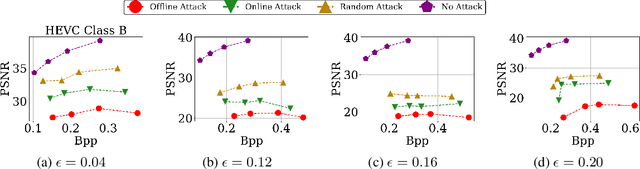
Adversarial Attacks on Deep Learning-based Video Compression and Classification Systems
Mar 18, 2022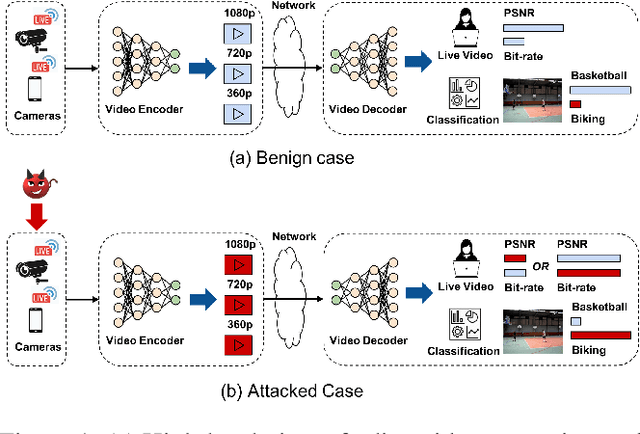
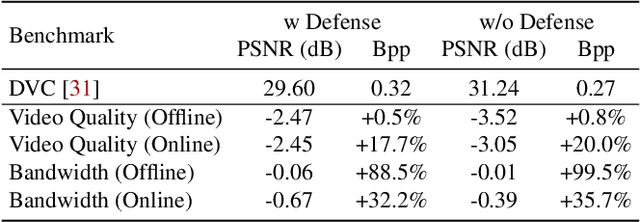
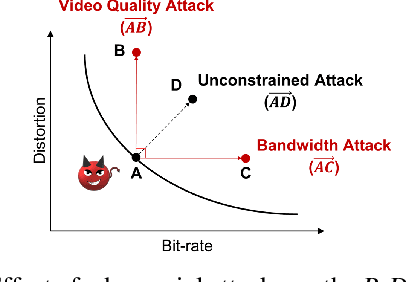
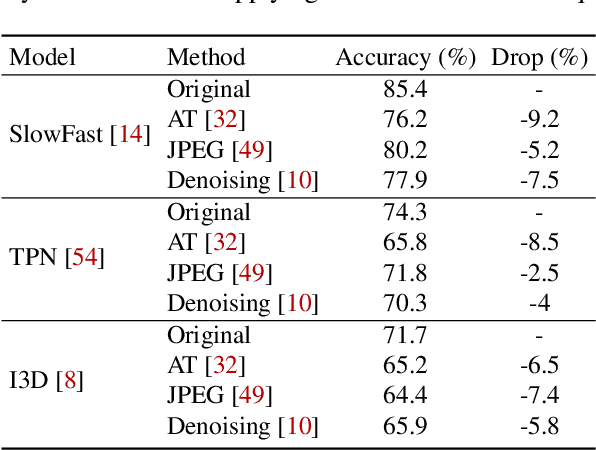
Video compression plays a crucial role in enabling video streaming and classification systems and maximizing the end-user quality of experience (QoE) at a given bandwidth budget. In this paper, we conduct the first systematic study for adversarial attacks on deep learning based video compression and downstream classification systems. We propose an adaptive adversarial attack that can manipulate the Rate-Distortion (R-D) relationship of a video compression model to achieve two adversarial goals: (1) increasing the network bandwidth or (2) degrading the video quality for end-users. We further devise novel objectives for targeted and untargeted attacks to a downstream video classification service. Finally, we design an input-invariant perturbation that universally disrupts video compression and classification systems in real time. Unlike previously proposed attacks on video classification, our adversarial perturbations are the first to withstand compression. We empirically show the resilience of our attacks against various defenses, i.e., adversarial training, video denoising, and JPEG compression. Our extensive experimental results on various video datasets demonstrate the effectiveness of our attacks. Our video quality and bandwidth attacks deteriorate peak signal-to-noise ratio by up to 5.4dB and the bit-rate by up to 2.4 times on the standard video compression datasets while achieving over 90% attack success rate on a downstream classifier.
LiteTransformerSearch: Training-free On-device Search for Efficient Autoregressive Language Models
Mar 04, 2022



The transformer architecture is ubiquitously used as the building block of most large-scale language models. However, it remains a painstaking guessing game of trial and error to set its myriad of architectural hyperparameters, e.g., number of layers, number of attention heads, and inner size of the feed forward network, and find architectures with the optimal trade-off between task performance like perplexity and compute constraints like memory and latency. This challenge is further exacerbated by the proliferation of various hardware. In this work, we leverage the somewhat surprising empirical observation that the number of non-embedding parameters in autoregressive transformers has a high rank correlation with task performance, irrespective of the architectural hyperparameters. Since architectural hyperparameters affect the latency and memory footprint in a hardware-dependent manner, the above observation organically induces a simple search algorithm that can be directly run on target devices. We rigorously show that the latency and perplexity pareto-frontier can be found without need for any model training, using non-embedding parameters as a proxy for perplexity. We evaluate our method, dubbed Lightweight Transformer Search (LTS), on diverse devices from ARM CPUs to Nvidia GPUs and show that the perplexity of Transformer-XL can be achieved with up to 2x lower latency. LTS extracts the pareto-frontier in less than 3 hours while running on a commodity laptop. We effectively remove the carbon footprint of training for hundreds of GPU hours, offering a strong simple baseline for future NAS methods in autoregressive language modeling.
Machine Learning-Assisted E-jet Printing of Organic Flexible Biosensors
Nov 07, 2021


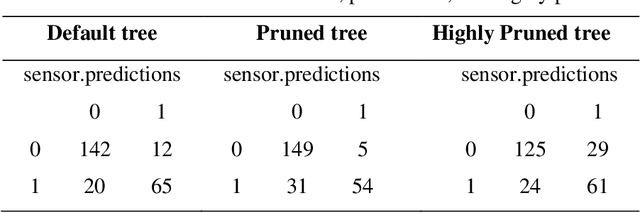
Electrohydrodynamic-jet (e-jet) printing technique enables the high-resolution printing of complex soft electronic devices. As such, it has an unmatched potential for becoming the conventional technique for printing soft electronic devices. In this study, the electrical conductivity of the e-jet printed circuits was studied as a function of key printing parameters (nozzle speed, ink flow rate, and voltage). The collected experimental dataset was then used to train a machine learning algorithm to establish models capable of predicting the characteristics of the printed circuits in real-time. Precision parameters were compared to evaluate the supervised classification models. Since decision tree methods could not increase the accuracy higher than 71%, more advanced algorithms are performed on our dataset to improve the precision of model. According to F-measure values, the K-NN model (k=10) and random forest are the best methods to classify the conductivity of electrodes. The highest accuracy of AdaBoost ensemble learning has resulted in the range of 10-15 trees (87%).
HASHTAG: Hash Signatures for Online Detection of Fault-Injection Attacks on Deep Neural Networks
Nov 02, 2021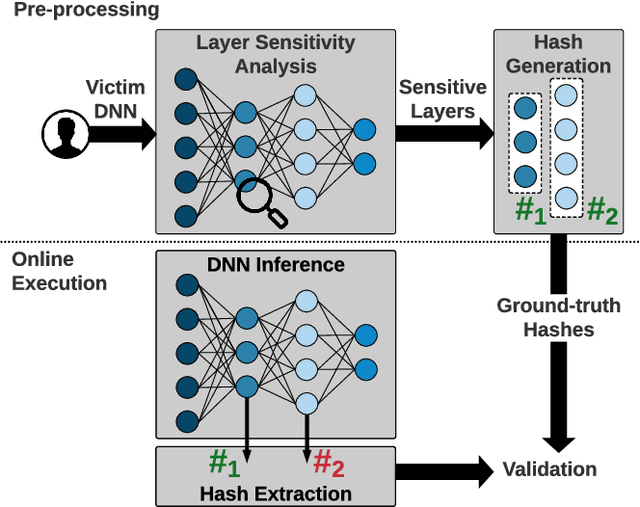
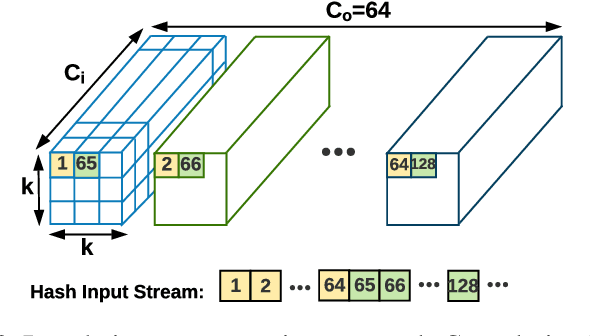
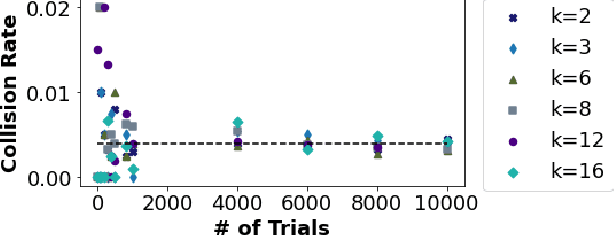
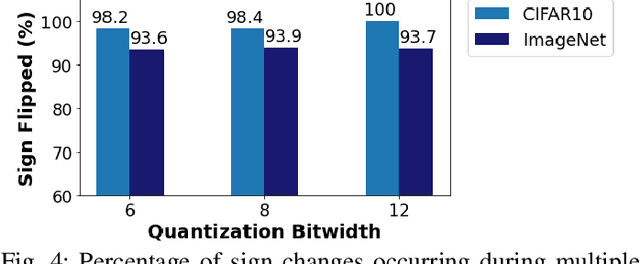
We propose HASHTAG, the first framework that enables high-accuracy detection of fault-injection attacks on Deep Neural Networks (DNNs) with provable bounds on detection performance. Recent literature in fault-injection attacks shows the severe DNN accuracy degradation caused by bit flips. In this scenario, the attacker changes a few weight bits during DNN execution by tampering with the program's DRAM memory. To detect runtime bit flips, HASHTAG extracts a unique signature from the benign DNN prior to deployment. The signature is later used to validate the integrity of the DNN and verify the inference output on the fly. We propose a novel sensitivity analysis scheme that accurately identifies the most vulnerable DNN layers to the fault-injection attack. The DNN signature is then constructed by encoding the underlying weights in the vulnerable layers using a low-collision hash function. When the DNN is deployed, new hashes are extracted from the target layers during inference and compared against the ground-truth signatures. HASHTAG incorporates a lightweight methodology that ensures a low-overhead and real-time fault detection on embedded platforms. Extensive evaluations with the state-of-the-art bit-flip attack on various DNNs demonstrate the competitive advantage of HASHTAG in terms of both attack detection and execution overhead.