 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Textbooks Are All You Need II: phi-1.5 technical report
Sep 11, 2023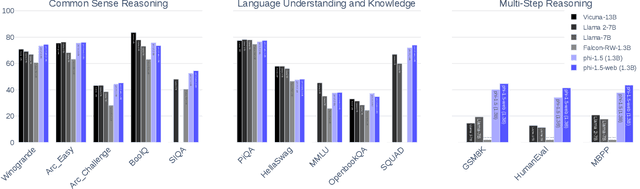

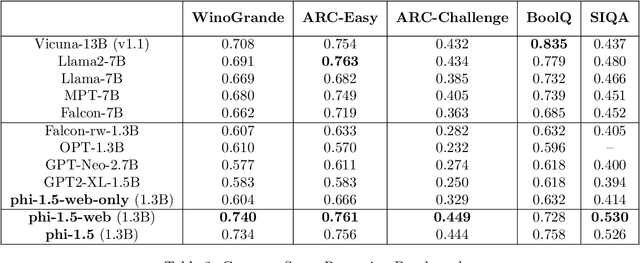
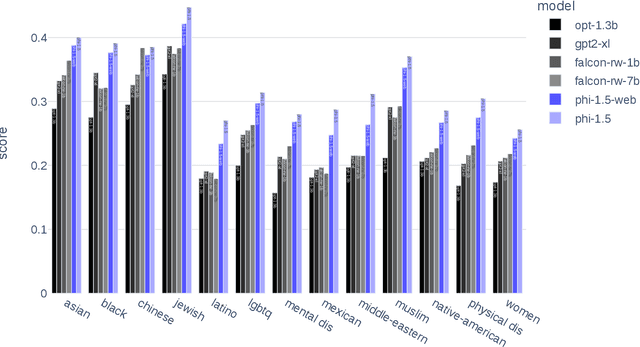
We continue the investigation into the power of smaller Transformer-based language models as initiated by \textbf{TinyStories} -- a 10 million parameter model that can produce coherent English -- and the follow-up work on \textbf{phi-1}, a 1.3 billion parameter model with Python coding performance close to the state-of-the-art. The latter work proposed to use existing Large Language Models (LLMs) to generate ``textbook quality" data as a way to enhance the learning process compared to traditional web data. We follow the ``Textbooks Are All You Need" approach, focusing this time on common sense reasoning in natural language, and create a new 1.3 billion parameter model named \textbf{phi-1.5}, with performance on natural language tasks comparable to models 5x larger, and surpassing most non-frontier LLMs on more complex reasoning tasks such as grade-school mathematics and basic coding. More generally, \textbf{phi-1.5} exhibits many of the traits of much larger LLMs, both good -- such as the ability to ``think step by step" or perform some rudimentary in-context learning -- and bad, including hallucinations and the potential for toxic and biased generations -- encouragingly though, we are seeing improvement on that front thanks to the absence of web data. We open-source \textbf{phi-1.5} to promote further research on these urgent topics.
SkipDecode: Autoregressive Skip Decoding with Batching and Caching for Efficient LLM Inference
Jul 05, 2023Autoregressive large language models (LLMs) have made remarkable progress in various natural language generation tasks. However, they incur high computation cost and latency resulting from the autoregressive token-by-token generation. To address this issue, several approaches have been proposed to reduce computational cost using early-exit strategies. These strategies enable faster text generation using reduced computation without applying the full computation graph to each token. While existing token-level early exit methods show promising results for online inference, they cannot be readily applied for batch inferencing and Key-Value caching. This is because they have to wait until the last token in a batch exits before they can stop computing. This severely limits the practical application of such techniques. In this paper, we propose a simple and effective token-level early exit method, SkipDecode, designed to work seamlessly with batch inferencing and KV caching. It overcomes prior constraints by setting up a singular exit point for every token in a batch at each sequence position. It also guarantees a monotonic decrease in exit points, thereby eliminating the need to recompute KV Caches for preceding tokens. Rather than terminating computation prematurely as in prior works, our approach bypasses lower to middle layers, devoting most of the computational resources to upper layers, allowing later tokens to benefit from the compute expenditure by earlier tokens. Our experimental results show that SkipDecode can obtain 2x to 5x inference speedups with negligible regression across a variety of tasks. This is achieved using OPT models of 1.3 billion and 6.7 billion parameters, all the while being directly compatible with batching and KV caching optimization techniques.
Textbooks Are All You Need
Jun 20, 2023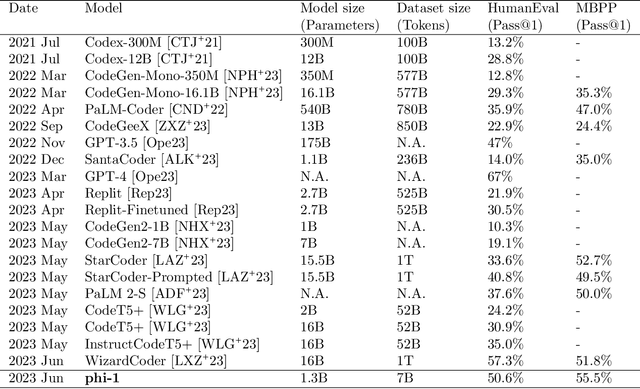
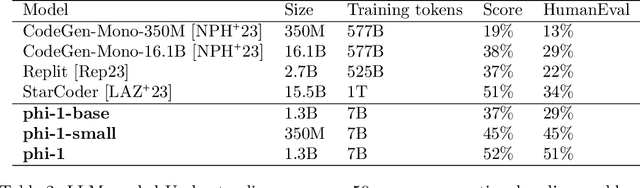
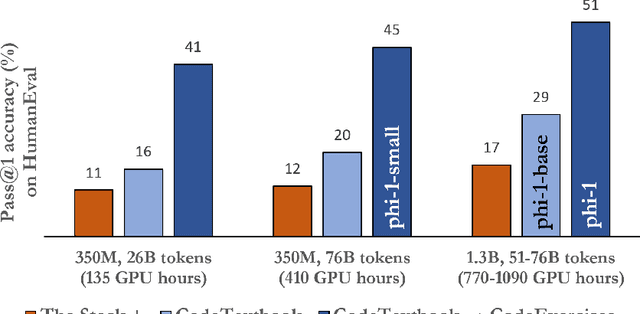
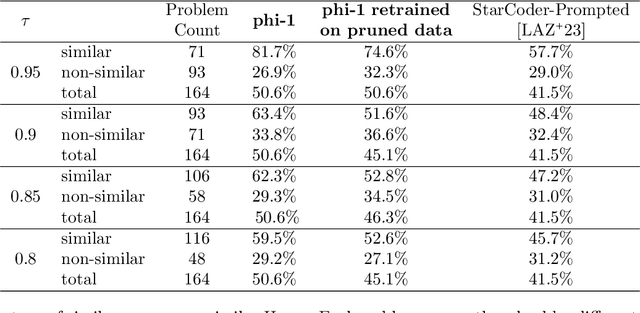
We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of ``textbook quality" data from the web (6B tokens) and synthetically generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as phi-1 that still achieves 45% on HumanEval.