 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-reasoning Technical Report
Apr 30, 2025We introduce Phi-4-reasoning, a 14-billion parameter reasoning model that achieves strong performance on complex reasoning tasks. Trained via supervised fine-tuning of Phi-4 on carefully curated set of "teachable" prompts-selected for the right level of complexity and diversity-and reasoning demonstrations generated using o3-mini, Phi-4-reasoning generates detailed reasoning chains that effectively leverage inference-time compute. We further develop Phi-4-reasoning-plus, a variant enhanced through a short phase of outcome-based reinforcement learning that offers higher performance by generating longer reasoning traces. Across a wide range of reasoning tasks, both models outperform significantly larger open-weight models such as DeepSeek-R1-Distill-Llama-70B model and approach the performance levels of full DeepSeek-R1 model. Our comprehensive evaluations span benchmarks in math and scientific reasoning, coding, algorithmic problem solving, planning, and spatial understanding. Interestingly, we observe a non-trivial transfer of improvements to general-purpose benchmarks as well. In this report, we provide insights into our training data, our training methodologies, and our evaluations. We show that the benefit of careful data curation for supervised fine-tuning (SFT) extends to reasoning language models, and can be further amplified by reinforcement learning (RL). Finally, our evaluation points to opportunities for improving how we assess the performance and robustness of reasoning models.
Orca 2: Teaching Small Language Models How to Reason
Nov 21, 2023



Orca 1 learns from rich signals, such as explanation traces, allowing it to outperform conventional instruction-tuned models on benchmarks like BigBench Hard and AGIEval. In Orca 2, we continue exploring how improved training signals can enhance smaller LMs' reasoning abilities. Research on training small LMs has often relied on imitation learning to replicate the output of more capable models. We contend that excessive emphasis on imitation may restrict the potential of smaller models. We seek to teach small LMs to employ different solution strategies for different tasks, potentially different from the one used by the larger model. For example, while larger models might provide a direct answer to a complex task, smaller models may not have the same capacity. In Orca 2, we teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.). More crucially, we aim to help the model learn to determine the most effective solution strategy for each task. We evaluate Orca 2 using a comprehensive set of 15 diverse benchmarks (corresponding to approximately 100 tasks and over 36,000 unique prompts). Orca 2 significantly surpasses models of similar size and attains performance levels similar or better to those of models 5-10x larger, as assessed on complex tasks that test advanced reasoning abilities in zero-shot settings. make Orca 2 weights publicly available at aka.ms/orca-lm to support research on the development, evaluation, and alignment of smaller LMs
SkipDecode: Autoregressive Skip Decoding with Batching and Caching for Efficient LLM Inference
Jul 05, 2023Autoregressive large language models (LLMs) have made remarkable progress in various natural language generation tasks. However, they incur high computation cost and latency resulting from the autoregressive token-by-token generation. To address this issue, several approaches have been proposed to reduce computational cost using early-exit strategies. These strategies enable faster text generation using reduced computation without applying the full computation graph to each token. While existing token-level early exit methods show promising results for online inference, they cannot be readily applied for batch inferencing and Key-Value caching. This is because they have to wait until the last token in a batch exits before they can stop computing. This severely limits the practical application of such techniques. In this paper, we propose a simple and effective token-level early exit method, SkipDecode, designed to work seamlessly with batch inferencing and KV caching. It overcomes prior constraints by setting up a singular exit point for every token in a batch at each sequence position. It also guarantees a monotonic decrease in exit points, thereby eliminating the need to recompute KV Caches for preceding tokens. Rather than terminating computation prematurely as in prior works, our approach bypasses lower to middle layers, devoting most of the computational resources to upper layers, allowing later tokens to benefit from the compute expenditure by earlier tokens. Our experimental results show that SkipDecode can obtain 2x to 5x inference speedups with negligible regression across a variety of tasks. This is achieved using OPT models of 1.3 billion and 6.7 billion parameters, all the while being directly compatible with batching and KV caching optimization techniques.
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Jun 05, 2023
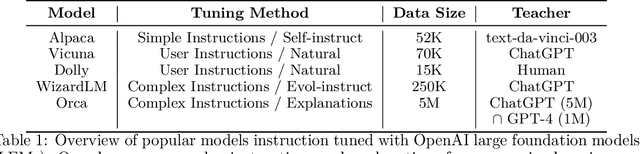


Recent research has focused on enhancing the capability of smaller models through imitation learning, drawing on the outputs generated by large foundation models (LFMs). A number of issues impact the quality of these models, ranging from limited imitation signals from shallow LFM outputs; small scale homogeneous training data; and most notably a lack of rigorous evaluation resulting in overestimating the small model's capability as they tend to learn to imitate the style, but not the reasoning process of LFMs. To address these challenges, we develop Orca (We are working with our legal team to publicly release a diff of the model weights in accordance with LLaMA's release policy to be published at https://aka.ms/orca-lm), a 13-billion parameter model that learns to imitate the reasoning process of LFMs. Orca learns from rich signals from GPT-4 including explanation traces; step-by-step thought processes; and other complex instructions, guided by teacher assistance from ChatGPT. To promote this progressive learning, we tap into large-scale and diverse imitation data with judicious sampling and selection. Orca surpasses conventional state-of-the-art instruction-tuned models such as Vicuna-13B by more than 100% in complex zero-shot reasoning benchmarks like Big-Bench Hard (BBH) and 42% on AGIEval. Moreover, Orca reaches parity with ChatGPT on the BBH benchmark and shows competitive performance (4 pts gap with optimized system message) in professional and academic examinations like the SAT, LSAT, GRE, and GMAT, both in zero-shot settings without CoT; while trailing behind GPT-4. Our research indicates that learning from step-by-step explanations, whether these are generated by humans or more advanced AI models, is a promising direction to improve model capabilities and skills.
AdaMix: Mixture-of-Adaptations for Parameter-efficient Model Tuning
Nov 02, 2022



Standard fine-tuning of large pre-trained language models (PLMs) for downstream tasks requires updating hundreds of millions to billions of parameters, and storing a large copy of the PLM weights for every task resulting in increased cost for storing, sharing and serving the models. To address this, parameter-efficient fine-tuning (PEFT) techniques were introduced where small trainable components are injected in the PLM and updated during fine-tuning. We propose AdaMix as a general PEFT method that tunes a mixture of adaptation modules -- given the underlying PEFT method of choice -- introduced in each Transformer layer while keeping most of the PLM weights frozen. For instance, AdaMix can leverage a mixture of adapters like Houlsby or a mixture of low rank decomposition matrices like LoRA to improve downstream task performance over the corresponding PEFT methods for fully supervised and few-shot NLU and NLG tasks. Further, we design AdaMix such that it matches the same computational cost and the number of tunable parameters as the underlying PEFT method. By only tuning 0.1-0.2% of PLM parameters, we show that AdaMix outperforms SOTA parameter-efficient fine-tuning and full model fine-tuning for both NLU and NLG tasks.