 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr Genre: Reinforcement Learning from Decoupled LLM Feedback for Generic Text Rewriting
Mar 09, 2025Generic text rewriting is a prevalent large language model (LLM) application that covers diverse real-world tasks, such as style transfer, fact correction, and email editing. These tasks vary in rewriting objectives (e.g., factual consistency vs. semantic preservation), making it challenging to develop a unified model that excels across all dimensions. Existing methods often specialize in either a single task or a specific objective, limiting their generalizability. In this work, we introduce a generic model proficient in factuality, stylistic, and conversational rewriting tasks. To simulate real-world user rewrite requests, we construct a conversational rewrite dataset, ChatRewrite, that presents ``natural''-sounding instructions, from raw emails using LLMs. Combined with other popular rewrite datasets, including LongFact for the factuality rewrite task and RewriteLM for the stylistic rewrite task, this forms a broad benchmark for training and evaluating generic rewrite models. To align with task-specific objectives, we propose Dr Genre, a Decoupled-reward learning framework for Generic rewriting, that utilizes objective-oriented reward models with a task-specific weighting. Evaluation shows that \approach delivers higher-quality rewrites across all targeted tasks, improving objectives including instruction following (agreement), internal consistency (coherence), and minimal unnecessary edits (conciseness).
LLM Performance Predictors are good initializers for Architecture Search
Oct 25, 2023Large language models (LLMs) have become an integral component in solving a wide range of NLP tasks. In this work, we explore a novel use case of using LLMs to build performance predictors (PP): models that, given a specific deep neural network architecture, predict its performance on a downstream task. We design PP prompts for LLMs consisting of: (i) role: description of the role assigned to the LLM, (ii) instructions: set of instructions to be followed by the LLM to carry out performance prediction, (iii) hyperparameters: a definition of each architecture-specific hyperparameter and (iv) demonstrations: sample architectures along with their efficiency metrics and 'training from scratch' performance. For machine translation (MT) tasks, we discover that GPT-4 with our PP prompts (LLM-PP) can predict the performance of architecture with a mean absolute error matching the SOTA and a marginal degradation in rank correlation coefficient compared to SOTA performance predictors. Further, we show that the predictions from LLM-PP can be distilled to a small regression model (LLM-Distill-PP). LLM-Distill-PP models surprisingly retain the performance of LLM-PP largely and can be a cost-effective alternative for heavy use cases of performance estimation. Specifically, for neural architecture search (NAS), we propose a Hybrid-Search algorithm for NAS (HS-NAS), which uses LLM-Distill-PP for the initial part of search, resorting to the baseline predictor for rest of the search. We show that HS-NAS performs very similar to SOTA NAS across benchmarks, reduces search hours by 50% roughly, and in some cases, improves latency, GFLOPs, and model size.
Mixture-of-Supernets: Improving Weight-Sharing Supernet Training with Architecture-Routed Mixture-of-Experts
Jun 08, 2023



Weight-sharing supernet has become a vital component for performance estimation in the state-of-the-art (SOTA) neural architecture search (NAS) frameworks. Although supernet can directly generate different subnetworks without retraining, there is no guarantee for the quality of these subnetworks because of weight sharing. In NLP tasks such as machine translation and pre-trained language modeling, we observe that given the same model architecture, there is a large performance gap between supernet and training from scratch. Hence, supernet cannot be directly used and retraining is necessary after finding the optimal architectures. In this work, we propose mixture-of-supernets, a generalized supernet formulation where mixture-of-experts (MoE) is adopted to enhance the expressive power of the supernet model, with negligible training overhead. In this way, different subnetworks do not share the model weights directly, but through an architecture-based routing mechanism. As a result, model weights of different subnetworks are customized towards their specific architectures and the weight generation is learned by gradient descent. Compared to existing weight-sharing supernet for NLP, our method can minimize the retraining time, greatly improving training efficiency. In addition, the proposed method achieves the SOTA performance in NAS for building fast machine translation models, yielding better latency-BLEU tradeoff compared to HAT, state-of-the-art NAS for MT. We also achieve the SOTA performance in NAS for building memory-efficient task-agnostic BERT models, outperforming NAS-BERT and AutoDistil in various model sizes.
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Jun 05, 2023
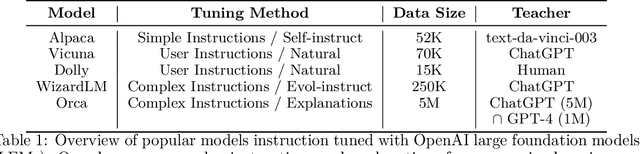


Recent research has focused on enhancing the capability of smaller models through imitation learning, drawing on the outputs generated by large foundation models (LFMs). A number of issues impact the quality of these models, ranging from limited imitation signals from shallow LFM outputs; small scale homogeneous training data; and most notably a lack of rigorous evaluation resulting in overestimating the small model's capability as they tend to learn to imitate the style, but not the reasoning process of LFMs. To address these challenges, we develop Orca (We are working with our legal team to publicly release a diff of the model weights in accordance with LLaMA's release policy to be published at https://aka.ms/orca-lm), a 13-billion parameter model that learns to imitate the reasoning process of LFMs. Orca learns from rich signals from GPT-4 including explanation traces; step-by-step thought processes; and other complex instructions, guided by teacher assistance from ChatGPT. To promote this progressive learning, we tap into large-scale and diverse imitation data with judicious sampling and selection. Orca surpasses conventional state-of-the-art instruction-tuned models such as Vicuna-13B by more than 100% in complex zero-shot reasoning benchmarks like Big-Bench Hard (BBH) and 42% on AGIEval. Moreover, Orca reaches parity with ChatGPT on the BBH benchmark and shows competitive performance (4 pts gap with optimized system message) in professional and academic examinations like the SAT, LSAT, GRE, and GMAT, both in zero-shot settings without CoT; while trailing behind GPT-4. Our research indicates that learning from step-by-step explanations, whether these are generated by humans or more advanced AI models, is a promising direction to improve model capabilities and skills.
AutoMoE: Neural Architecture Search for Efficient Sparsely Activated Transformers
Oct 14, 2022
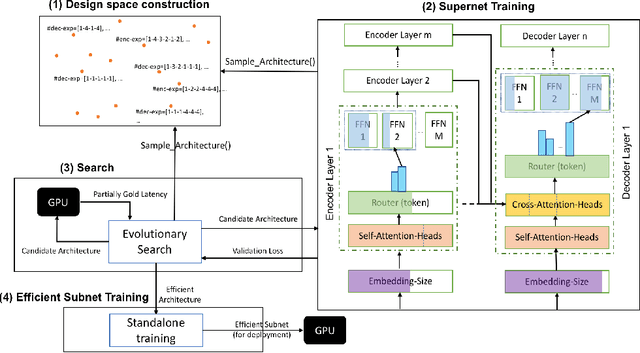


Neural architecture search (NAS) has demonstrated promising results on identifying efficient Transformer architectures which outperform manually designed ones for natural language tasks like neural machine translation (NMT). Existing NAS methods operate on a space of dense architectures, where all of the sub-architecture weights are activated for every input. Motivated by the recent advances in sparsely activated models like the Mixture-of-Experts (MoE) model, we introduce sparse architectures with conditional computation into the NAS search space. Given this expressive search space which subsumes prior densely activated architectures, we develop a new framework AutoMoE to search for efficient sparsely activated sub-Transformers. AutoMoE-generated sparse models obtain (i) 3x FLOPs reduction over manually designed dense Transformers and (ii) 23% FLOPs reduction over state-of-the-art NAS-generated dense sub-Transformers with parity in BLEU score on benchmark datasets for NMT. AutoMoE consists of three training phases: (a) Heterogeneous search space design with dense and sparsely activated Transformer modules (e.g., how many experts? where to place them? what should be their sizes?); (b) SuperNet training that jointly trains several subnetworks sampled from the large search space by weight-sharing; (c) Evolutionary search for the architecture with the optimal trade-off between task performance and computational constraint like FLOPs and latency. AutoMoE code, data and trained models are available at https://github.com/microsoft/AutoMoE.
Small Character Models Match Large Word Models for Autocomplete Under Memory Constraints
Oct 06, 2022



Autocomplete is a task where the user inputs a piece of text, termed prompt, which is conditioned by the model to generate semantically coherent continuation. Existing works for this task have primarily focused on datasets (e.g., email, chat) with high frequency user prompt patterns (or focused prompts) where word-based language models have been quite effective. In this work, we study the more challenging setting consisting of low frequency user prompt patterns (or broad prompts, e.g., prompt about 93rd academy awards) and demonstrate the effectiveness of character-based language models. We study this problem under memory-constrained settings (e.g., edge devices and smartphones), where character-based representation is effective in reducing the overall model size (in terms of parameters). We use WikiText-103 benchmark to simulate broad prompts and demonstrate that character models rival word models in exact match accuracy for the autocomplete task, when controlled for the model size. For instance, we show that a 20M parameter character model performs similar to an 80M parameter word model in the vanilla setting. We further propose novel methods to improve character models by incorporating inductive bias in the form of compositional information and representation transfer from large word models.
Automatic Detection of Entity-Manipulated Text using Factual Knowledge
Mar 19, 2022

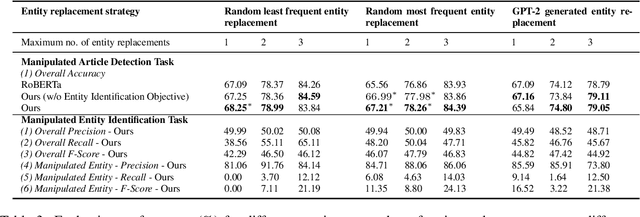
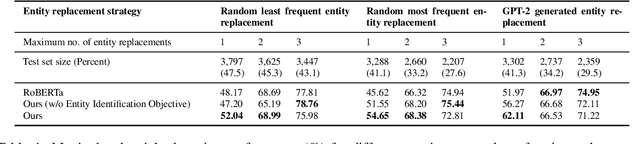
In this work, we focus on the problem of distinguishing a human written news article from a news article that is created by manipulating entities in a human written news article (e.g., replacing entities with factually incorrect entities). Such manipulated articles can mislead the reader by posing as a human written news article. We propose a neural network based detector that detects manipulated news articles by reasoning about the facts mentioned in the article. Our proposed detector exploits factual knowledge via graph convolutional neural network along with the textual information in the news article. We also create challenging datasets for this task by considering various strategies to generate the new replacement entity (e.g., entity generation from GPT-2). In all the settings, our proposed model either matches or outperforms the state-of-the-art detector in terms of accuracy. Our code and data are available at https://github.com/UBC-NLP/manipulated_entity_detection.
InfoDCL: A Distantly Supervised Contrastive Learning Framework for Social Meaning
Mar 15, 2022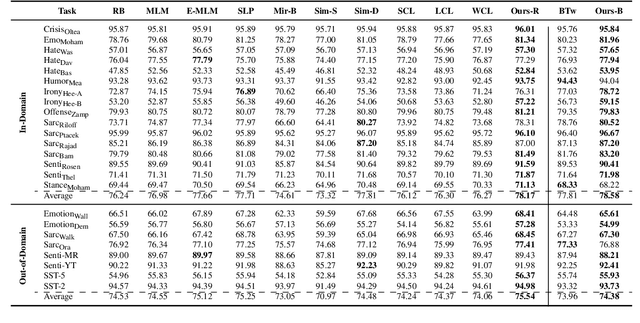

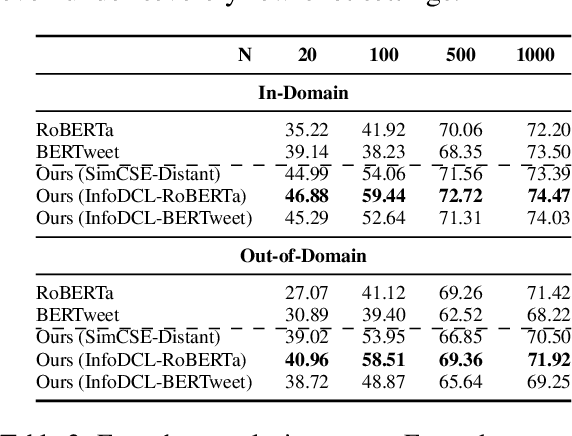

Existing supervised contrastive learning frameworks suffer from two major drawbacks: (i) they depend on labeled data, which is limited for the majority of tasks in real-world, and (ii) they incorporate inter-class relationships based on instance-level information, while ignoring corpus-level information, for weighting negative samples. To mitigate these challenges, we propose an effective distantly supervised contrastive learning framework (InfoDCL) that makes use of naturally occurring surrogate labels in the context of contrastive learning and employs pointwise mutual information to leverage corpus-level information. Our framework outperforms an extensive set of existing contrastive learning methods (self-supervised, supervised, and weakly supervised) on a wide range of social meaning tasks (in-domain and out-of-domain), in both the general and few-shot settings. Our method is also language-agnostic, as we demonstrate on three languages in addition to English.
Simple, Interpretable and Stable Method for Detecting Words with Usage Change across Corpora
Dec 28, 2021

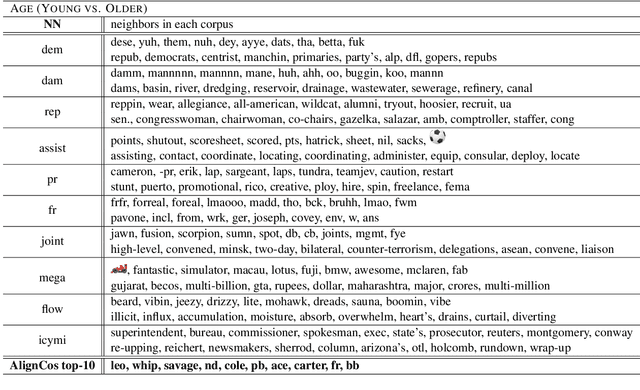

The problem of comparing two bodies of text and searching for words that differ in their usage between them arises often in digital humanities and computational social science. This is commonly approached by training word embeddings on each corpus, aligning the vector spaces, and looking for words whose cosine distance in the aligned space is large. However, these methods often require extensive filtering of the vocabulary to perform well, and - as we show in this work - result in unstable, and hence less reliable, results. We propose an alternative approach that does not use vector space alignment, and instead considers the neighbors of each word. The method is simple, interpretable and stable. We demonstrate its effectiveness in 9 different setups, considering different corpus splitting criteria (age, gender and profession of tweet authors, time of tweet) and different languages (English, French and Hebrew).
Exploring Text-to-Text Transformers for English to Hinglish Machine Translation with Synthetic Code-Mixing
May 18, 2021
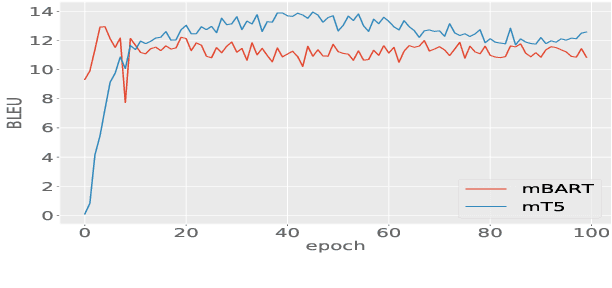
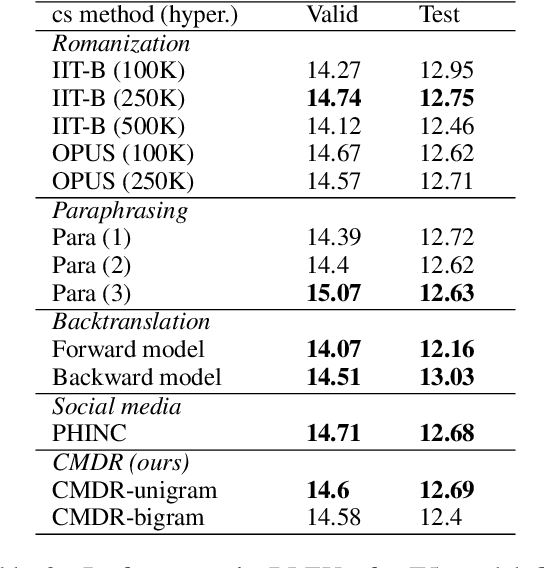
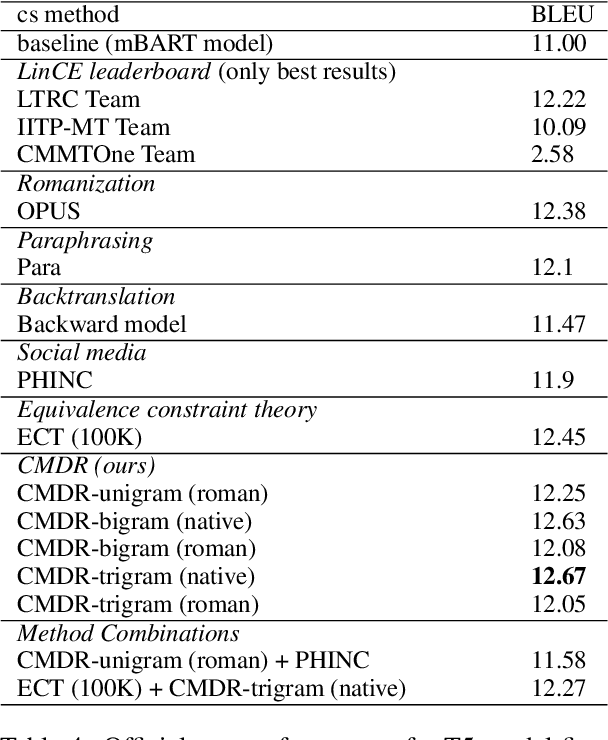
We describe models focused at the understudied problem of translating between monolingual and code-mixed language pairs. More specifically, we offer a wide range of models that convert monolingual English text into Hinglish (code-mixed Hindi and English). Given the recent success of pretrained language models, we also test the utility of two recent Transformer-based encoder-decoder models (i.e., mT5 and mBART) on the task finding both to work well. Given the paucity of training data for code-mixing, we also propose a dependency-free method for generating code-mixed texts from bilingual distributed representations that we exploit for improving language model performance. In particular, armed with this additional data, we adopt a curriculum learning approach where we first finetune the language models on synthetic data then on gold code-mixed data. We find that, although simple, our synthetic code-mixing method is competitive with (and in some cases is even superior to) several standard methods (backtranslation, method based on equivalence constraint theory) under a diverse set of conditions. Our work shows that the mT5 model, finetuned following the curriculum learning procedure, achieves best translation performance (12.67 BLEU). Our models place first in the overall ranking of the English-Hinglish official shared task.