 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenMic: A Multi-Agent-Based Stand-Up Comedy Generation System
Jan 13, 2026Chinese stand-up comedy generation goes beyond plain text generation, requiring culturally grounded humor, precise timing, stage-performance cues, and implicit multi-step reasoning. Moreover, commonly used Chinese humor datasets are often better suited for humor understanding and evaluation than for long-form stand-up generation, making direct supervision misaligned with the target task. To address these challenges, we present OpenMic, an end-to-end multi-agent system built on AutoGen that transforms a user-provided life topic into a 3-5 minute Chinese stand-up performance and further produces a narrated comedy video. OpenMic orchestrates multiple specialized agents in a multi-round iterative loop-planning to jointly optimize humor, timing, and performability. To mitigate the dataset-task mismatch, we augment generation with retrieval-augmented generation (RAG) for material grounding and idea expansion, and we fine-tune a dedicated JokeWriter to better internalize stand-up-specific setup-punchline structures and long-range callbacks.
SeBERTis: A Framework for Producing Classifiers of Security-Related Issue Reports
Dec 17, 2025Monitoring issue tracker submissions is a crucial software maintenance activity. A key goal is the prioritization of high risk, security-related bugs. If such bugs can be recognized early, the risk of propagation to dependent products and endangerment of stakeholder benefits can be mitigated. To assist triage engineers with this task, several automatic detection techniques, from Machine Learning (ML) models to prompting Large Language Models (LLMs), have been proposed. Although promising to some extent, prior techniques often memorize lexical cues as decision shortcuts, yielding low detection rate specifically for more complex submissions. As such, these classifiers do not yet reach the practical expectations of a real-time detector of security-related issues. To address these limitations, we propose SEBERTIS, a framework to train Deep Neural Networks (DNNs) as classifiers independent of lexical cues, so that they can confidently detect fully unseen security-related issues. SEBERTIS capitalizes on fine-tuning bidirectional transformer architectures as Masked Language Models (MLMs) on a series of semantically equivalent vocabulary to prediction labels (which we call Semantic Surrogates) when they have been replaced with a mask. Our SEBERTIS-trained classifier achieves a 0.9880 F1-score in detecting security-related issues of a curated corpus of 10,000 GitHub issue reports, substantially outperforming state-of-the-art issue classifiers, with 14.44%-96.98%, 15.40%-93.07%, and 14.90%-94.72% higher detection precision, recall, and F1-score over ML-based baselines. Our classifier also substantially surpasses LLM baselines, with an improvement of 23.20%-63.71%, 36.68%-85.63%, and 39.49%-74.53% for precision, recall, and F1-score.
AIAuditTrack: A Framework for AI Security system
Dec 16, 2025
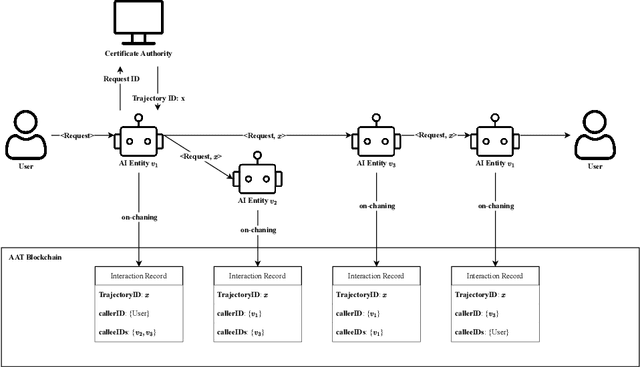
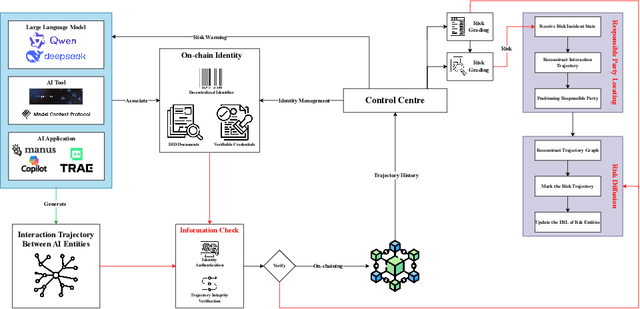
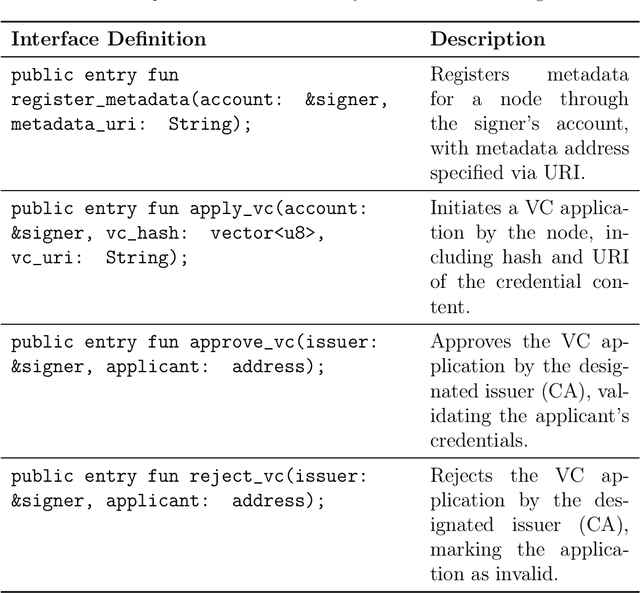
The rapid expansion of AI-driven applications powered by large language models has led to a surge in AI interaction data, raising urgent challenges in security, accountability, and risk traceability. This paper presents AiAuditTrack (AAT), a blockchain-based framework for AI usage traffic recording and governance. AAT leverages decentralized identity (DID) and verifiable credentials (VC) to establish trusted and identifiable AI entities, and records inter-entity interaction trajectories on-chain to enable cross-system supervision and auditing. AI entities are modeled as nodes in a dynamic interaction graph, where edges represent time-specific behavioral trajectories. Based on this model, a risk diffusion algorithm is proposed to trace the origin of risky behaviors and propagate early warnings across involved entities. System performance is evaluated using blockchain Transactions Per Second (TPS) metrics, demonstrating the feasibility and stability of AAT under large-scale interaction recording. AAT provides a scalable and verifiable solution for AI auditing, risk management, and responsibility attribution in complex multi-agent environments.
The Docking Game: Loop Self-Play for Fast, Dynamic, and Accurate Prediction of Flexible Protein--Ligand Binding
Aug 07, 2025Molecular docking is a crucial aspect of drug discovery, as it predicts the binding interactions between small-molecule ligands and protein pockets. However, current multi-task learning models for docking often show inferior performance in ligand docking compared to protein pocket docking. This disparity arises largely due to the distinct structural complexities of ligands and proteins. To address this issue, we propose a novel game-theoretic framework that models the protein-ligand interaction as a two-player game called the Docking Game, with the ligand docking module acting as the ligand player and the protein pocket docking module as the protein player. To solve this game, we develop a novel Loop Self-Play (LoopPlay) algorithm, which alternately trains these players through a two-level loop. In the outer loop, the players exchange predicted poses, allowing each to incorporate the other's structural predictions, which fosters mutual adaptation over multiple iterations. In the inner loop, each player dynamically refines its predictions by incorporating its own predicted ligand or pocket poses back into its model. We theoretically show the convergence of LoopPlay, ensuring stable optimization. Extensive experiments conducted on public benchmark datasets demonstrate that LoopPlay achieves approximately a 10\% improvement in predicting accurate binding modes compared to previous state-of-the-art methods. This highlights its potential to enhance the accuracy of molecular docking in drug discovery.
FastRef:Fast Prototype Refinement for Few-Shot Industrial Anomaly Detection
Jun 26, 2025Few-shot industrial anomaly detection (FS-IAD) presents a critical challenge for practical automated inspection systems operating in data-scarce environments. While existing approaches predominantly focus on deriving prototypes from limited normal samples, they typically neglect to systematically incorporate query image statistics to enhance prototype representativeness. To address this issue, we propose FastRef, a novel and efficient prototype refinement framework for FS-IAD. Our method operates through an iterative two-stage process: (1) characteristic transfer from query features to prototypes via an optimizable transformation matrix, and (2) anomaly suppression through prototype alignment. The characteristic transfer is achieved through linear reconstruction of query features from prototypes, while the anomaly suppression addresses a key observation in FS-IAD that unlike conventional IAD with abundant normal prototypes, the limited-sample setting makes anomaly reconstruction more probable. Therefore, we employ optimal transport (OT) for non-Gaussian sampled features to measure and minimize the gap between prototypes and their refined counterparts for anomaly suppression. For comprehensive evaluation, we integrate FastRef with three competitive prototype-based FS-IAD methods: PatchCore, FastRecon, WinCLIP, and AnomalyDINO. Extensive experiments across four benchmark datasets of MVTec, ViSA, MPDD and RealIAD demonstrate both the effectiveness and computational efficiency of our approach under 1/2/4-shots.
Meta-SurDiff: Classification Diffusion Model Optimized by Meta Learning is Reliable for Online Surgical Phase Recognition
Jun 17, 2025



Online surgical phase recognition has drawn great attention most recently due to its potential downstream applications closely related to human life and health. Despite deep models have made significant advances in capturing the discriminative long-term dependency of surgical videos to achieve improved recognition, they rarely account for exploring and modeling the uncertainty in surgical videos, which should be crucial for reliable online surgical phase recognition. We categorize the sources of uncertainty into two types, frame ambiguity in videos and unbalanced distribution among surgical phases, which are inevitable in surgical videos. To address this pivot issue, we introduce a meta-learning-optimized classification diffusion model (Meta-SurDiff), to take full advantage of the deep generative model and meta-learning in achieving precise frame-level distribution estimation for reliable online surgical phase recognition. For coarse recognition caused by ambiguous video frames, we employ a classification diffusion model to assess the confidence of recognition results at a finer-grained frame-level instance. For coarse recognition caused by unbalanced phase distribution, we use a meta-learning based objective to learn the diffusion model, thus enhancing the robustness of classification boundaries for different surgical phases.We establish effectiveness of Meta-SurDiff in online surgical phase recognition through extensive experiments on five widely used datasets using more than four practical metrics. The datasets include Cholec80, AutoLaparo, M2Cai16, OphNet, and NurViD, where OphNet comes from ophthalmic surgeries, NurViD is the daily care dataset, while the others come from laparoscopic surgeries. We will release the code upon acceptance.
QUITE: A Query Rewrite System Beyond Rules with LLM Agents
Jun 09, 2025Query rewrite transforms SQL queries into semantically equivalent forms that run more efficiently. Existing approaches mainly rely on predefined rewrite rules, but they handle a limited subset of queries and can cause performance regressions. This limitation stems from three challenges of rule-based query rewrite: (1) it is hard to discover and verify new rules, (2) fixed rewrite rules do not generalize to new query patterns, and (3) some rewrite techniques cannot be expressed as fixed rules. Motivated by the fact that human experts exhibit significantly better rewrite ability but suffer from scalability, and Large Language Models (LLMs) have demonstrated nearly human-level semantic and reasoning abilities, we propose a new approach of using LLMs to rewrite SQL queries beyond rules. Due to the hallucination problems in LLMs, directly applying LLMs often leads to nonequivalent and suboptimal queries. To address this issue, we propose QUITE (query rewrite), a training-free and feedback-aware system based on LLM agents that rewrites SQL queries into semantically equivalent forms with significantly better performance, covering a broader range of query patterns and rewrite strategies compared to rule-based methods. Firstly, we design a multi-agent framework controlled by a finite state machine (FSM) to equip LLMs with the ability to use external tools and enhance the rewrite process with real-time database feedback. Secondly, we develop a rewrite middleware to enhance the ability of LLMs to generate optimized query equivalents. Finally, we employ a novel hint injection technique to improve execution plans for rewritten queries. Extensive experiments show that QUITE reduces query execution time by up to 35.8% over state-of-the-art approaches and produces 24.1% more rewrites than prior methods, covering query cases that earlier systems did not handle.
Dr Genre: Reinforcement Learning from Decoupled LLM Feedback for Generic Text Rewriting
Mar 09, 2025Generic text rewriting is a prevalent large language model (LLM) application that covers diverse real-world tasks, such as style transfer, fact correction, and email editing. These tasks vary in rewriting objectives (e.g., factual consistency vs. semantic preservation), making it challenging to develop a unified model that excels across all dimensions. Existing methods often specialize in either a single task or a specific objective, limiting their generalizability. In this work, we introduce a generic model proficient in factuality, stylistic, and conversational rewriting tasks. To simulate real-world user rewrite requests, we construct a conversational rewrite dataset, ChatRewrite, that presents ``natural''-sounding instructions, from raw emails using LLMs. Combined with other popular rewrite datasets, including LongFact for the factuality rewrite task and RewriteLM for the stylistic rewrite task, this forms a broad benchmark for training and evaluating generic rewrite models. To align with task-specific objectives, we propose Dr Genre, a Decoupled-reward learning framework for Generic rewriting, that utilizes objective-oriented reward models with a task-specific weighting. Evaluation shows that \approach delivers higher-quality rewrites across all targeted tasks, improving objectives including instruction following (agreement), internal consistency (coherence), and minimal unnecessary edits (conciseness).
Top Ten Challenges Towards Agentic Neural Graph Databases
Jan 24, 2025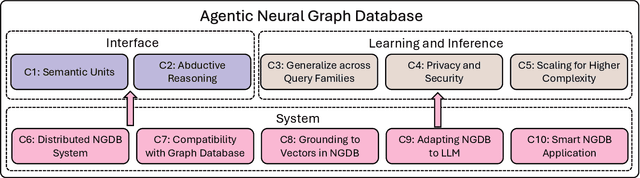
Graph databases (GDBs) like Neo4j and TigerGraph excel at handling interconnected data but lack advanced inference capabilities. Neural Graph Databases (NGDBs) address this by integrating Graph Neural Networks (GNNs) for predictive analysis and reasoning over incomplete or noisy data. However, NGDBs rely on predefined queries and lack autonomy and adaptability. This paper introduces Agentic Neural Graph Databases (Agentic NGDBs), which extend NGDBs with three core functionalities: autonomous query construction, neural query execution, and continuous learning. We identify ten key challenges in realizing Agentic NGDBs: semantic unit representation, abductive reasoning, scalable query execution, and integration with foundation models like large language models (LLMs). By addressing these challenges, Agentic NGDBs can enable intelligent, self-improving systems for modern data-driven applications, paving the way for adaptable and autonomous data management solutions.
Safety Alignment in NLP Tasks: Weakly Aligned Summarization as an In-Context Attack
Dec 12, 2023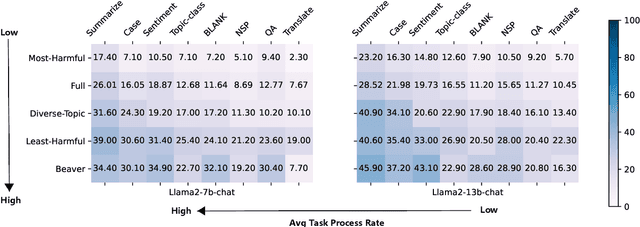


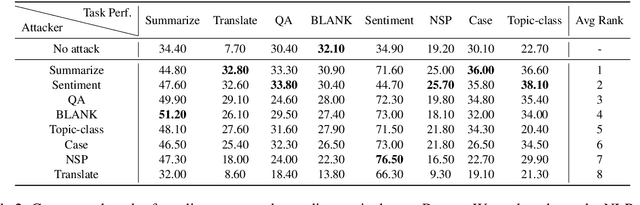
Recent developments in balancing the usefulness and safety of Large Language Models (LLMs) have raised a critical question: Are mainstream NLP tasks adequately aligned with safety consideration? Our study, focusing on safety-sensitive documents obtained through adversarial attacks, reveals significant disparities in the safety alignment of various NLP tasks. For instance, LLMs can effectively summarize malicious long documents but often refuse to translate them. This discrepancy highlights a previously unidentified vulnerability: attacks exploiting tasks with weaker safety alignment, like summarization, can potentially compromise the integraty of tasks traditionally deemed more robust, such as translation and question-answering (QA). Moreover, the concurrent use of multiple NLP tasks with lesser safety alignment increases the risk of LLMs inadvertently processing harmful content. We demonstrate these vulnerabilities in various safety-aligned LLMs, particularly Llama2 models and GPT-4, indicating an urgent need for strengthening safety alignments across a broad spectrum of NLP tasks.