 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic DAG Discovery for Interpretable Imitation Learning
Oct 12, 2023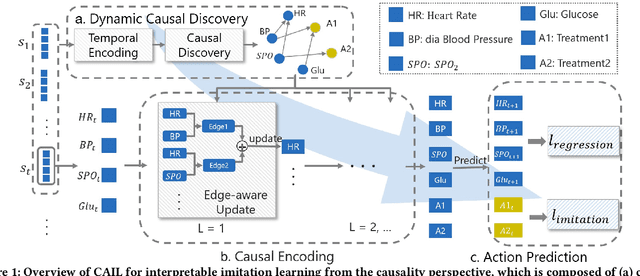

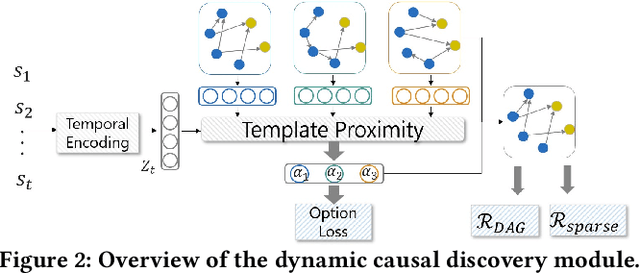
Imitation learning, which learns agent policy by mimicking expert demonstration, has shown promising results in many applications such as medical treatment regimes and self-driving vehicles. However, it remains a difficult task to interpret control policies learned by the agent. Difficulties mainly come from two aspects: 1) agents in imitation learning are usually implemented as deep neural networks, which are black-box models and lack interpretability; 2) the latent causal mechanism behind agents' decisions may vary along the trajectory, rather than staying static throughout time steps. To increase transparency and offer better interpretability of the neural agent, we propose to expose its captured knowledge in the form of a directed acyclic causal graph, with nodes being action and state variables and edges denoting the causal relations behind predictions. Furthermore, we design this causal discovery process to be state-dependent, enabling it to model the dynamics in latent causal graphs. Concretely, we conduct causal discovery from the perspective of Granger causality and propose a self-explainable imitation learning framework, {\method}. The proposed framework is composed of three parts: a dynamic causal discovery module, a causality encoding module, and a prediction module, and is trained in an end-to-end manner. After the model is learned, we can obtain causal relations among states and action variables behind its decisions, exposing policies learned by it. Experimental results on both synthetic and real-world datasets demonstrate the effectiveness of the proposed {\method} in learning the dynamic causal graphs for understanding the decision-making of imitation learning meanwhile maintaining high prediction accuracy.
GLAD: Content-aware Dynamic Graphs For Log Anomaly Detection
Sep 12, 2023


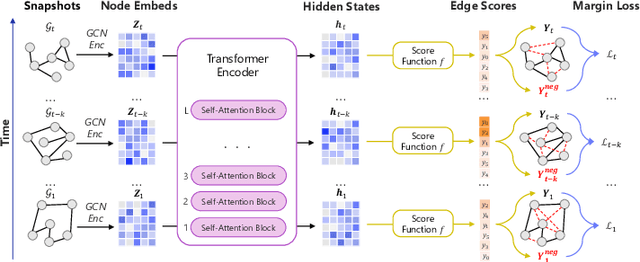
Logs play a crucial role in system monitoring and debugging by recording valuable system information, including events and states. Although various methods have been proposed to detect anomalies in log sequences, they often overlook the significance of considering relations among system components, such as services and users, which can be identified from log contents. Understanding these relations is vital for detecting anomalies and their underlying causes. To address this issue, we introduce GLAD, a Graph-based Log Anomaly Detection framework designed to detect relational anomalies in system logs. GLAD incorporates log semantics, relational patterns, and sequential patterns into a unified framework for anomaly detection. Specifically, GLAD first introduces a field extraction module that utilizes prompt-based few-shot learning to identify essential fields from log contents. Then GLAD constructs dynamic log graphs for sliding windows by interconnecting extracted fields and log events parsed from the log parser. These graphs represent events and fields as nodes and their relations as edges. Subsequently, GLAD utilizes a temporal-attentive graph edge anomaly detection model for identifying anomalous relations in these dynamic log graphs. This model employs a Graph Neural Network (GNN)-based encoder enhanced with transformers to capture content, structural and temporal features. We evaluate our proposed method on three datasets, and the results demonstrate the effectiveness of GLAD in detecting anomalies indicated by varying relational patterns.
Skill Disentanglement for Imitation Learning from Suboptimal Demonstrations
Jun 13, 2023


Imitation learning has achieved great success in many sequential decision-making tasks, in which a neural agent is learned by imitating collected human demonstrations. However, existing algorithms typically require a large number of high-quality demonstrations that are difficult and expensive to collect. Usually, a trade-off needs to be made between demonstration quality and quantity in practice. Targeting this problem, in this work we consider the imitation of sub-optimal demonstrations, with both a small clean demonstration set and a large noisy set. Some pioneering works have been proposed, but they suffer from many limitations, e.g., assuming a demonstration to be of the same optimality throughout time steps and failing to provide any interpretation w.r.t knowledge learned from the noisy set. Addressing these problems, we propose {\method} by evaluating and imitating at the sub-demonstration level, encoding action primitives of varying quality into different skills. Concretely, {\method} consists of a high-level controller to discover skills and a skill-conditioned module to capture action-taking policies, and is trained following a two-phase pipeline by first discovering skills with all demonstrations and then adapting the controller to only the clean set. A mutual-information-based regularization and a dynamic sub-demonstration optimality estimator are designed to promote disentanglement in the skill space. Extensive experiments are conducted over two gym environments and a real-world healthcare dataset to demonstrate the superiority of {\method} in learning from sub-optimal demonstrations and its improved interpretability by examining learned skills.
Time Series Contrastive Learning with Information-Aware Augmentations
Mar 21, 2023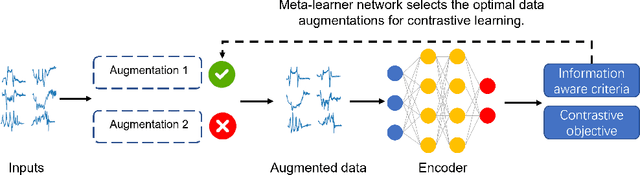
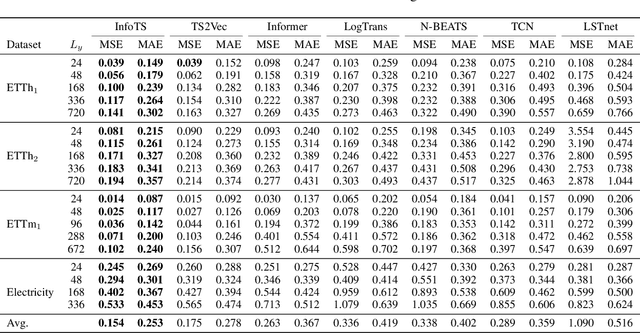
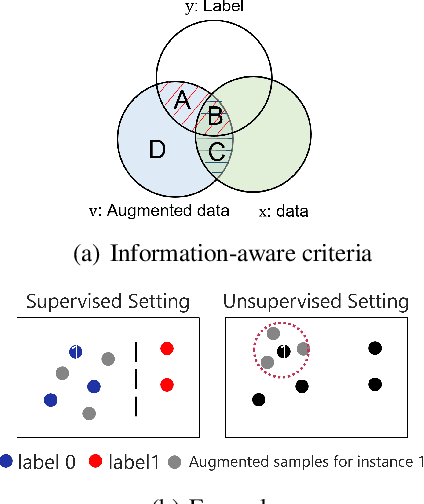

Various contrastive learning approaches have been proposed in recent years and achieve significant empirical success. While effective and prevalent, contrastive learning has been less explored for time series data. A key component of contrastive learning is to select appropriate augmentations imposing some priors to construct feasible positive samples, such that an encoder can be trained to learn robust and discriminative representations. Unlike image and language domains where ``desired'' augmented samples can be generated with the rule of thumb guided by prefabricated human priors, the ad-hoc manual selection of time series augmentations is hindered by their diverse and human-unrecognizable temporal structures. How to find the desired augmentations of time series data that are meaningful for given contrastive learning tasks and datasets remains an open question. In this work, we address the problem by encouraging both high \textit{fidelity} and \textit{variety} based upon information theory. A theoretical analysis leads to the criteria for selecting feasible data augmentations. On top of that, we propose a new contrastive learning approach with information-aware augmentations, InfoTS, that adaptively selects optimal augmentations for time series representation learning. Experiments on various datasets show highly competitive performance with up to 12.0\% reduction in MSE on forecasting tasks and up to 3.7\% relative improvement in accuracy on classification tasks over the leading baselines.
Deep Federated Anomaly Detection for Multivariate Time Series Data
May 09, 2022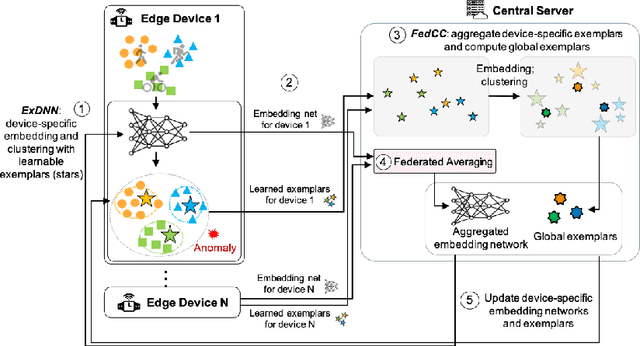
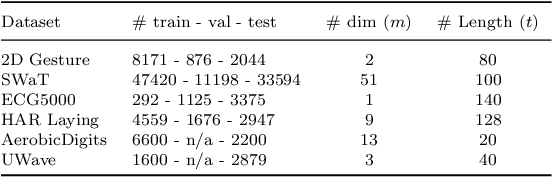
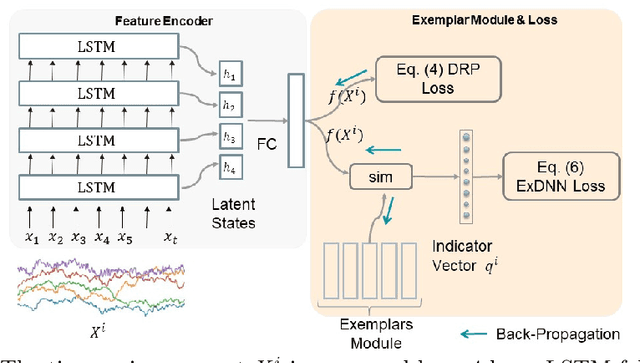
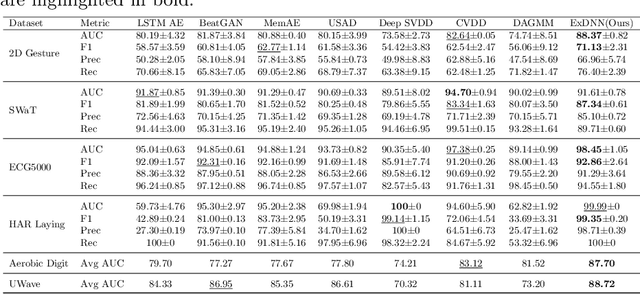
Despite the fact that many anomaly detection approaches have been developed for multivariate time series data, limited effort has been made on federated settings in which multivariate time series data are heterogeneously distributed among different edge devices while data sharing is prohibited. In this paper, we investigate the problem of federated unsupervised anomaly detection and present a Federated Exemplar-based Deep Neural Network (Fed-ExDNN) to conduct anomaly detection for multivariate time series data on different edge devices. Specifically, we first design an Exemplar-based Deep Neural network (ExDNN) to learn local time series representations based on their compatibility with an exemplar module which consists of hidden parameters learned to capture varieties of normal patterns on each edge device. Next, a constrained clustering mechanism (FedCC) is employed on the centralized server to align and aggregate the parameters of different local exemplar modules to obtain a unified global exemplar module. Finally, the global exemplar module is deployed together with a shared feature encoder to each edge device and anomaly detection is conducted by examining the compatibility of testing data to the exemplar module. Fed-ExDNN captures local normal time series patterns with ExDNN and aggregates these patterns by FedCC, and thus can handle the heterogeneous data distributed over different edge devices simultaneously. Thoroughly empirical studies on six public datasets show that ExDNN and Fed-ExDNN can outperform state-of-the-art anomaly detection algorithms and federated learning techniques.
SEED: Sound Event Early Detection via Evidential Uncertainty
Feb 13, 2022

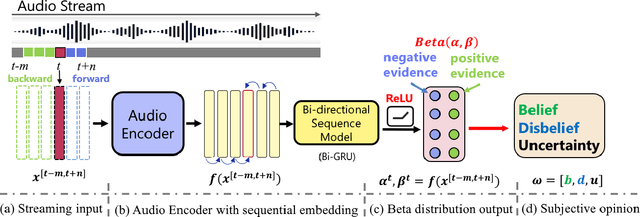
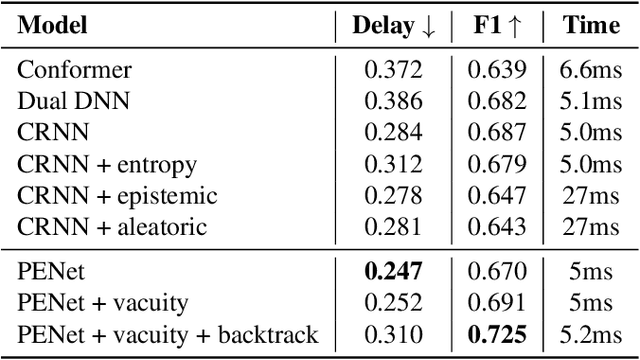
Sound Event Early Detection (SEED) is an essential task in recognizing the acoustic environments and soundscapes. However, most of the existing methods focus on the offline sound event detection, which suffers from the over-confidence issue of early-stage event detection and usually yield unreliable results. To solve the problem, we propose a novel Polyphonic Evidential Neural Network (PENet) to model the evidential uncertainty of the class probability with Beta distribution. Specifically, we use a Beta distribution to model the distribution of class probabilities, and the evidential uncertainty enriches uncertainty representation with evidence information, which plays a central role in reliable prediction. To further improve the event detection performance, we design the backtrack inference method that utilizes both the forward and backward audio features of an ongoing event. Experiments on the DESED database show that the proposed method can simultaneously improve 13.0\% and 3.8\% in time delay and detection F1 score compared to the state-of-the-art methods.
Ordinal-Quadruplet: Retrieval of Missing Classes in Ordinal Time Series
Jan 24, 2022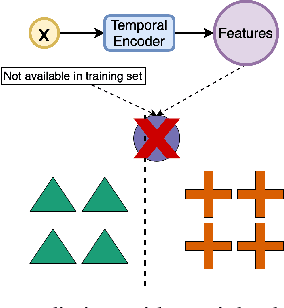

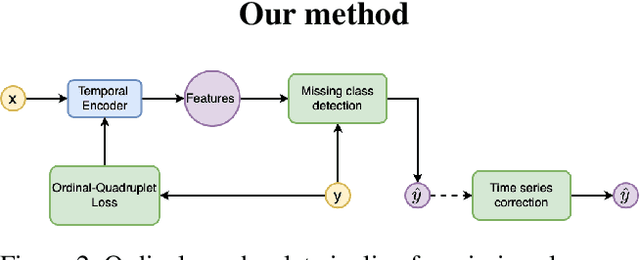
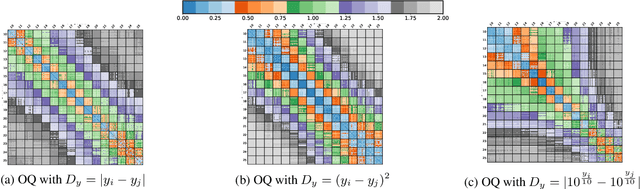
In this paper, we propose an ordered time series classification framework that is robust against missing classes in the training data, i.e., during testing we can prescribe classes that are missing during training. This framework relies on two main components: (1) our newly proposed ordinal-quadruplet loss, which forces the model to learn latent representation while preserving the ordinal relation among labels, (2) testing procedure, which utilizes the property of latent representation (order preservation). We conduct experiments based on real world multivariate time series data and show the significant improvement in the prediction of missing labels even with 40% of the classes are missing from training. Compared with the well-known triplet loss optimization augmented with interpolation for missing information, in some cases, we nearly double the accuracy.
Convolutional Transformer based Dual Discriminator Generative Adversarial Networks for Video Anomaly Detection
Jul 29, 2021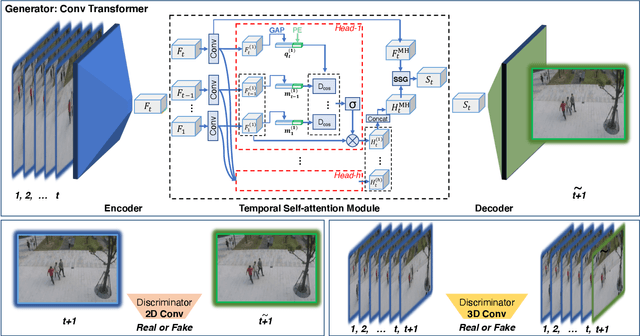

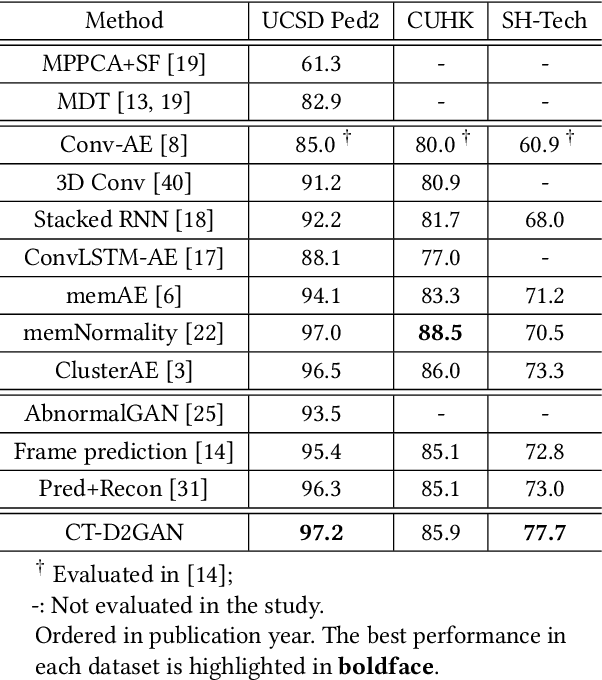
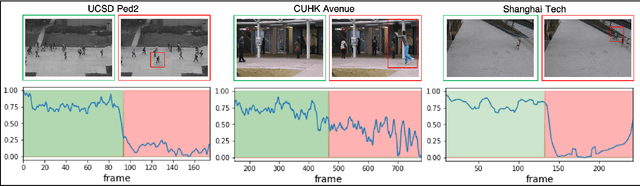
Detecting abnormal activities in real-world surveillance videos is an important yet challenging task as the prior knowledge about video anomalies is usually limited or unavailable. Despite that many approaches have been developed to resolve this problem, few of them can capture the normal spatio-temporal patterns effectively and efficiently. Moreover, existing works seldom explicitly consider the local consistency at frame level and global coherence of temporal dynamics in video sequences. To this end, we propose Convolutional Transformer based Dual Discriminator Generative Adversarial Networks (CT-D2GAN) to perform unsupervised video anomaly detection. Specifically, we first present a convolutional transformer to perform future frame prediction. It contains three key components, i.e., a convolutional encoder to capture the spatial information of the input video clips, a temporal self-attention module to encode the temporal dynamics, and a convolutional decoder to integrate spatio-temporal features and predict the future frame. Next, a dual discriminator based adversarial training procedure, which jointly considers an image discriminator that can maintain the local consistency at frame-level and a video discriminator that can enforce the global coherence of temporal dynamics, is employed to enhance the future frame prediction. Finally, the prediction error is used to identify abnormal video frames. Thoroughly empirical studies on three public video anomaly detection datasets, i.e., UCSD Ped2, CUHK Avenue, and Shanghai Tech Campus, demonstrate the effectiveness of the proposed adversarial spatio-temporal modeling framework.
3D Fusion of Infrared Images with Dense RGB Reconstruction from Multiple Views -- with Application to Fire-fighting Robots
Jul 29, 2020



This project integrates infrared and RGB imagery to produce dense 3D environment models reconstructed from multiple views. The resulting 3D map contains both thermal and RGB information which can be used in robotic fire-fighting applications to identify victims and active fire areas.
A Deep Neural Network for Unsupervised Anomaly Detection and Diagnosis in Multivariate Time Series Data
Nov 20, 2018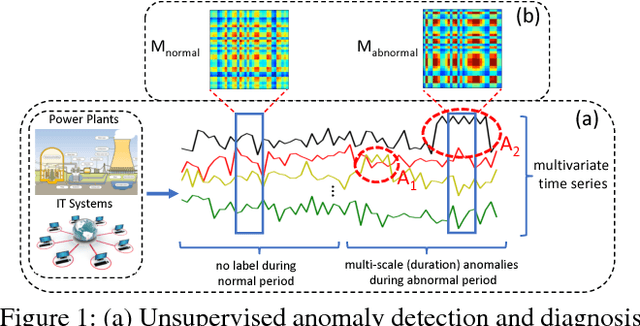
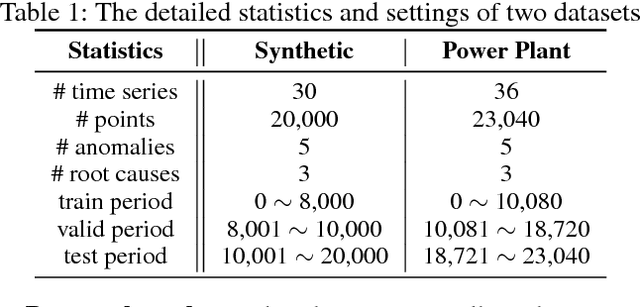

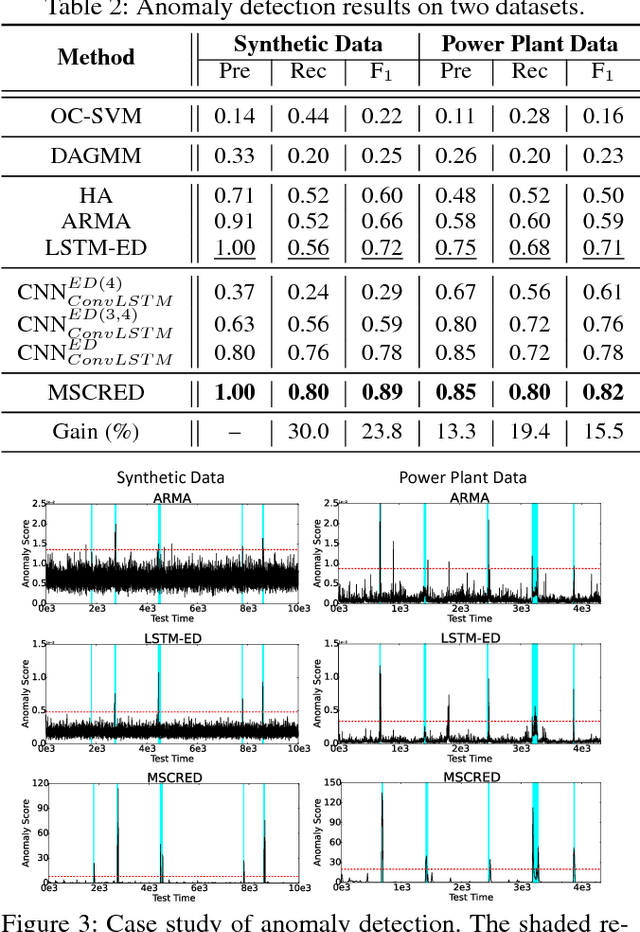
Nowadays, multivariate time series data are increasingly collected in various real world systems, e.g., power plants, wearable devices, etc. Anomaly detection and diagnosis in multivariate time series refer to identifying abnormal status in certain time steps and pinpointing the root causes. Building such a system, however, is challenging since it not only requires to capture the temporal dependency in each time series, but also need encode the inter-correlations between different pairs of time series. In addition, the system should be robust to noise and provide operators with different levels of anomaly scores based upon the severity of different incidents. Despite the fact that a number of unsupervised anomaly detection algorithms have been developed, few of them can jointly address these challenges. In this paper, we propose a Multi-Scale Convolutional Recurrent Encoder-Decoder (MSCRED), to perform anomaly detection and diagnosis in multivariate time series data. Specifically, MSCRED first constructs multi-scale (resolution) signature matrices to characterize multiple levels of the system statuses in different time steps. Subsequently, given the signature matrices, a convolutional encoder is employed to encode the inter-sensor (time series) correlations and an attention based Convolutional Long-Short Term Memory (ConvLSTM) network is developed to capture the temporal patterns. Finally, based upon the feature maps which encode the inter-sensor correlations and temporal information, a convolutional decoder is used to reconstruct the input signature matrices and the residual signature matrices are further utilized to detect and diagnose anomalies. Extensive empirical studies based on a synthetic dataset and a real power plant dataset demonstrate that MSCRED can outperform state-of-the-art baseline methods.