 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Procedural Graph Extraction with Structural and Logical Refinement
Jan 27, 2026Automatically extracting workflows as procedural graphs from natural language is promising yet underexplored, demanding both structural validity and logical alignment. While recent large language models (LLMs) show potential for procedural graph extraction, they often produce ill-formed structures or misinterpret logical flows. We present \model{}, a multi-agent framework that formulates procedural graph extraction as a multi-round reasoning process with dedicated structural and logical refinement. The framework iterates through three stages: (1) a graph extraction phase with the graph builder agent, (2) a structural feedback phase in which a simulation agent diagnoses and explains structural defects, and (3) a logical feedback phase in which a semantic agent aligns semantics between flow logic and linguistic cues in the source text. Important feedback is prioritized and expressed in natural language, which is injected into subsequent prompts, enabling interpretable and controllable refinement. This modular design allows agents to target distinct error types without supervision or parameter updates. Experiments demonstrate that \model{} achieves substantial improvements in both structural correctness and logical consistency over strong baselines.
Out-of-Distribution Detection with Positive and Negative Prompt Supervision Using Large Language Models
Nov 14, 2025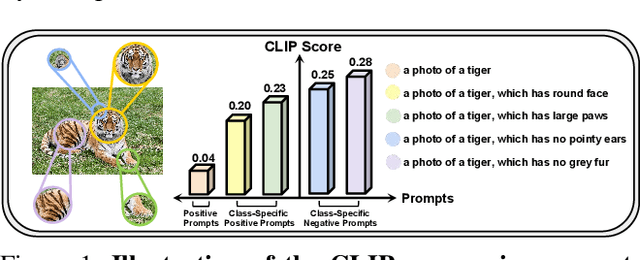
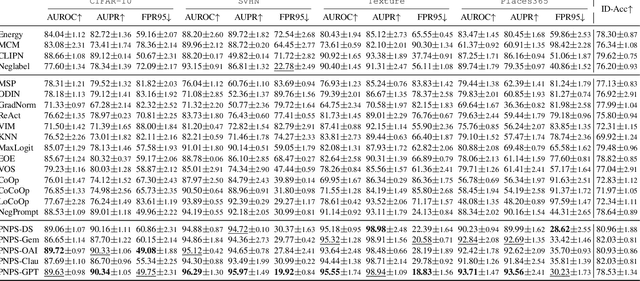
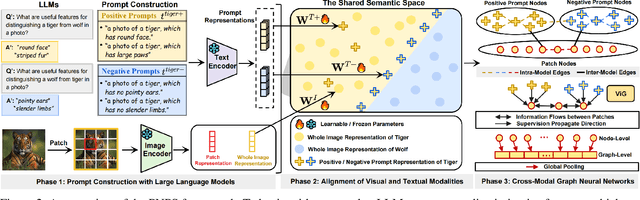
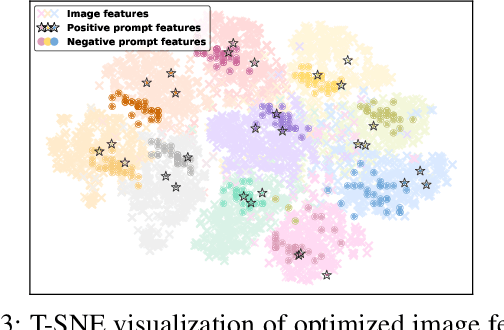
Out-of-distribution (OOD) detection is committed to delineating the classification boundaries between in-distribution (ID) and OOD images. Recent advances in vision-language models (VLMs) have demonstrated remarkable OOD detection performance by integrating both visual and textual modalities. In this context, negative prompts are introduced to emphasize the dissimilarity between image features and prompt content. However, these prompts often include a broad range of non-ID features, which may result in suboptimal outcomes due to the capture of overlapping or misleading information. To address this issue, we propose Positive and Negative Prompt Supervision, which encourages negative prompts to capture inter-class features and transfers this semantic knowledge to the visual modality to enhance OOD detection performance. Our method begins with class-specific positive and negative prompts initialized by large language models (LLMs). These prompts are subsequently optimized, with positive prompts focusing on features within each class, while negative prompts highlight features around category boundaries. Additionally, a graph-based architecture is employed to aggregate semantic-aware supervision from the optimized prompt representations and propagate it to the visual branch, thereby enhancing the performance of the energy-based OOD detector. Extensive experiments on two benchmarks, CIFAR-100 and ImageNet-1K, across eight OOD datasets and five different LLMs, demonstrate that our method outperforms state-of-the-art baselines.
DeepSieve: Information Sieving via LLM-as-a-Knowledge-Router
Jul 30, 2025Large Language Models (LLMs) excel at many reasoning tasks but struggle with knowledge-intensive queries due to their inability to dynamically access up-to-date or domain-specific information. Retrieval-Augmented Generation (RAG) has emerged as a promising solution, enabling LLMs to ground their responses in external sources. However, existing RAG methods lack fine-grained control over both the query and source sides, often resulting in noisy retrieval and shallow reasoning. In this work, we introduce DeepSieve, an agentic RAG framework that incorporates information sieving via LLM-as-a-knowledge-router. DeepSieve decomposes complex queries into structured sub-questions and recursively routes each to the most suitable knowledge source, filtering irrelevant information through a multi-stage distillation process. Our design emphasizes modularity, transparency, and adaptability, leveraging recent advances in agentic system design. Experiments on multi-hop QA tasks across heterogeneous sources demonstrate improved reasoning depth, retrieval precision, and interpretability over conventional RAG approaches. Our codes are available at https://github.com/MinghoKwok/DeepSieve.
SAUP: Situation Awareness Uncertainty Propagation on LLM Agent
Dec 02, 2024



Large language models (LLMs) integrated into multistep agent systems enable complex decision-making processes across various applications. However, their outputs often lack reliability, making uncertainty estimation crucial. Existing uncertainty estimation methods primarily focus on final-step outputs, which fail to account for cumulative uncertainty over the multistep decision-making process and the dynamic interactions between agents and their environments. To address these limitations, we propose SAUP (Situation Awareness Uncertainty Propagation), a novel framework that propagates uncertainty through each step of an LLM-based agent's reasoning process. SAUP incorporates situational awareness by assigning situational weights to each step's uncertainty during the propagation. Our method, compatible with various one-step uncertainty estimation techniques, provides a comprehensive and accurate uncertainty measure. Extensive experiments on benchmark datasets demonstrate that SAUP significantly outperforms existing state-of-the-art methods, achieving up to 20% improvement in AUROC.
Decoding Time Series with LLMs: A Multi-Agent Framework for Cross-Domain Annotation
Oct 22, 2024



Time series data is ubiquitous across various domains, including manufacturing, finance, and healthcare. High-quality annotations are essential for effectively understanding time series and facilitating downstream tasks; however, obtaining such annotations is challenging, particularly in mission-critical domains. In this paper, we propose TESSA, a multi-agent system designed to automatically generate both general and domain-specific annotations for time series data. TESSA introduces two agents: a general annotation agent and a domain-specific annotation agent. The general agent captures common patterns and knowledge across multiple source domains, leveraging both time-series-wise and text-wise features to generate general annotations. Meanwhile, the domain-specific agent utilizes limited annotations from the target domain to learn domain-specific terminology and generate targeted annotations. Extensive experiments on multiple synthetic and real-world datasets demonstrate that TESSA effectively generates high-quality annotations, outperforming existing methods.
RIO-CPD: A Riemannian Geometric Method for Correlation-aware Online Change Point Detection
Jul 12, 2024



The objective of change point detection is to identify abrupt changes at potentially multiple points within a data sequence. This task is particularly challenging in the online setting where various types of changes can occur, including shifts in both the marginal and joint distributions of the data. This paper tackles these challenges by sequentially tracking correlation matrices on the Riemannian geometry, where the geodesic distances accurately capture the development of correlations. We propose Rio-CPD, a non-parametric correlation-aware online change point detection framework that combines the Riemannian geometry of the manifold of symmetric positive definite matrices and the cumulative sum statistic (CUSUM) for detecting change points. Rio-CPD enhances CUSUM by computing the geodesic distance from present observations to the Fr\'echet mean of previous observations. With careful choice of metrics equipped to the Riemannian geometry, Rio-CPD is simple and computationally efficient. Experimental results on both synthetic and real-world datasets demonstrate that Rio-CPD outperforms existing methods in detection accuracy and efficiency.
Pruning as a Domain-specific LLM Extractor
May 10, 2024



Large Language Models (LLMs) have exhibited remarkable proficiency across a wide array of NLP tasks. However, the escalation in model size also engenders substantial deployment costs. While few efforts have explored model pruning techniques to reduce the size of LLMs, they mainly center on general or task-specific weights. This leads to suboptimal performance due to lacking specificity on the target domain or generality on different tasks when applied to domain-specific challenges. This work introduces an innovative unstructured dual-pruning methodology, D-Pruner, for domain-specific compression on LLM. It extracts a compressed, domain-specific, and task-agnostic LLM by identifying LLM weights that are pivotal for general capabilities, like linguistic capability and multi-task solving, and domain-specific knowledge. More specifically, we first assess general weight importance by quantifying the error incurred upon their removal with the help of an open-domain calibration dataset. Then, we utilize this general weight importance to refine the training loss, so that it preserves generality when fitting into a specific domain. Moreover, by efficiently approximating weight importance with the refined training loss on a domain-specific calibration dataset, we obtain a pruned model emphasizing generality and specificity. Our comprehensive experiments across various tasks in healthcare and legal domains show the effectiveness of D-Pruner in domain-specific compression. Our code is available at https://github.com/psunlpgroup/D-Pruner.
Uncertainty Decomposition and Quantification for In-Context Learning of Large Language Models
Feb 15, 2024
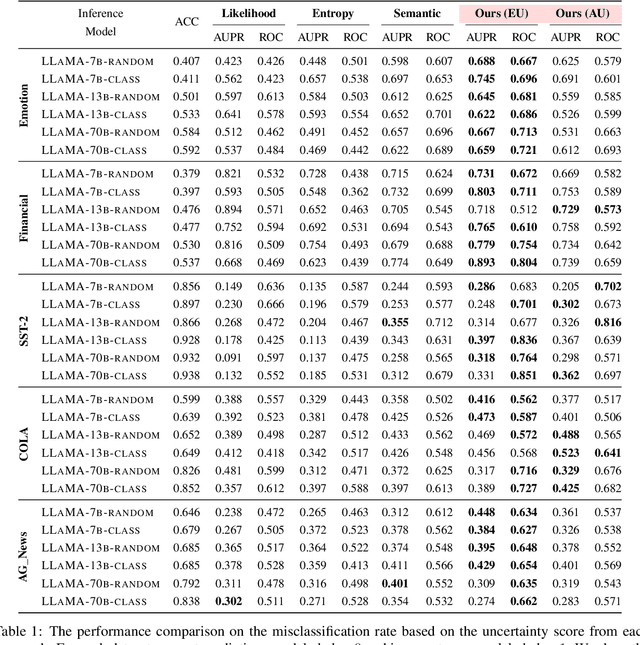
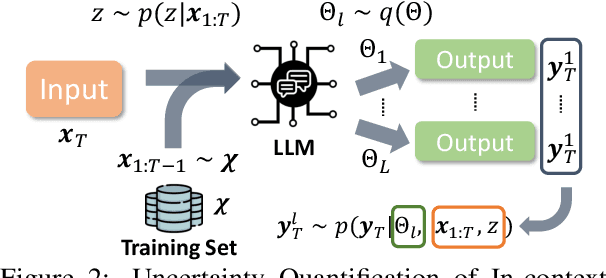
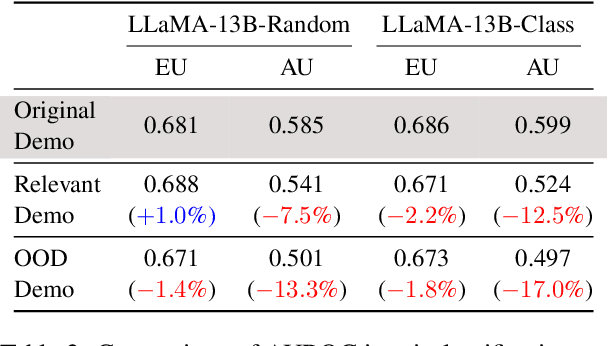
In-context learning has emerged as a groundbreaking ability of Large Language Models (LLMs) and revolutionized various fields by providing a few task-relevant demonstrations in the prompt. However, trustworthy issues with LLM's response, such as hallucination, have also been actively discussed. Existing works have been devoted to quantifying the uncertainty in LLM's response, but they often overlook the complex nature of LLMs and the uniqueness of in-context learning. In this work, we delve into the predictive uncertainty of LLMs associated with in-context learning, highlighting that such uncertainties may stem from both the provided demonstrations (aleatoric uncertainty) and ambiguities tied to the model's configurations (epistemic uncertainty). We propose a novel formulation and corresponding estimation method to quantify both types of uncertainties. The proposed method offers an unsupervised way to understand the prediction of in-context learning in a plug-and-play fashion. Extensive experiments are conducted to demonstrate the effectiveness of the decomposition. The code and data are available at: \url{https://github.com/lingchen0331/UQ_ICL}.
Open-ended Commonsense Reasoning with Unrestricted Answer Scope
Oct 27, 2023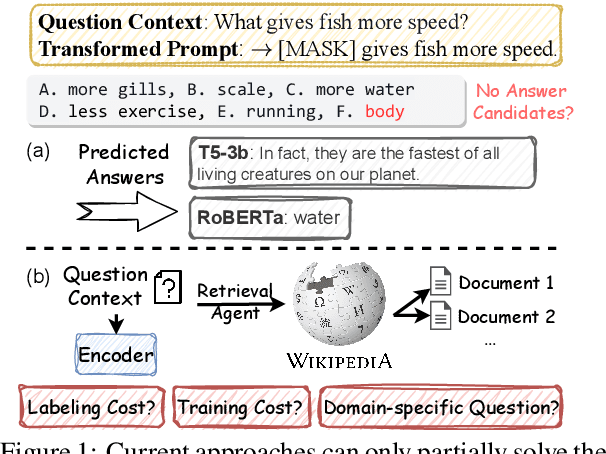
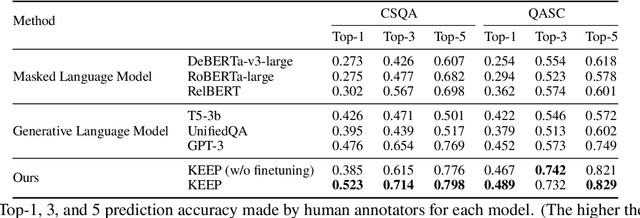
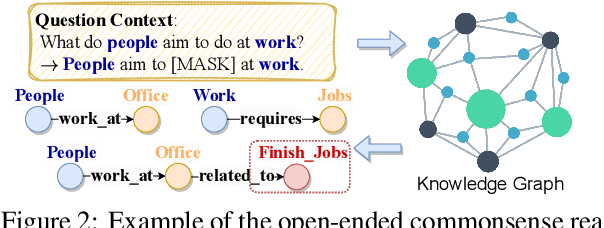
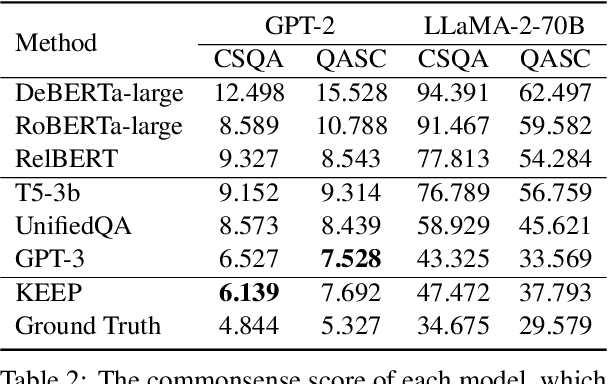
Open-ended Commonsense Reasoning is defined as solving a commonsense question without providing 1) a short list of answer candidates and 2) a pre-defined answer scope. Conventional ways of formulating the commonsense question into a question-answering form or utilizing external knowledge to learn retrieval-based methods are less applicable in the open-ended setting due to an inherent challenge. Without pre-defining an answer scope or a few candidates, open-ended commonsense reasoning entails predicting answers by searching over an extremely large searching space. Moreover, most questions require implicit multi-hop reasoning, which presents even more challenges to our problem. In this work, we leverage pre-trained language models to iteratively retrieve reasoning paths on the external knowledge base, which does not require task-specific supervision. The reasoning paths can help to identify the most precise answer to the commonsense question. We conduct experiments on two commonsense benchmark datasets. Compared to other approaches, our proposed method achieves better performance both quantitatively and qualitatively.
Large Language Models Can Be Good Privacy Protection Learners
Oct 03, 2023



The proliferation of Large Language Models (LLMs) has driven considerable interest in fine-tuning them with domain-specific data to create specialized language models. Nevertheless, such domain-specific fine-tuning data often contains sensitive personally identifiable information (PII). Direct fine-tuning LLMs on this data without privacy protection poses a risk of leakage. To address this challenge, we introduce Privacy Protection Language Models (PPLM), a novel paradigm for fine-tuning LLMs that effectively injects domain-specific knowledge while safeguarding data privacy. Our work offers a theoretical analysis for model design and delves into various techniques such as corpus curation, penalty-based unlikelihood in training loss, and instruction-based tuning, etc. Extensive experiments across diverse datasets and scenarios demonstrate the effectiveness of our approaches. In particular, instruction tuning with both positive and negative examples, stands out as a promising method, effectively protecting private data while enhancing the model's knowledge. Our work underscores the potential for Large Language Models as robust privacy protection learners.