 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Inference for Micro-Gesture Recognition: EFE-Guided Temporal Sampling and Adaptive Learning
Mar 08, 2026Micro-gestures are subtle and transient movements triggered by unconscious neural and emotional activities, holding great potential for human-computer interaction and clinical monitoring. However, their low amplitude, short duration, and strong inter-subject variability make existing deep models prone to degradation under low-sample, noisy, and cross-subject conditions. This paper presents an active inference-based framework for micro-gesture recognition, featuring Expected Free Energy (EFE)-guided temporal sampling and uncertainty-aware adaptive learning. The model actively selects the most discriminative temporal segments under EFE guidance, enabling dynamic observation and information gain maximization. Meanwhile, sample weighting driven by predictive uncertainty mitigates the effects of label noise and distribution shift. Experiments on the SMG dataset demonstrate the effectiveness of the proposed method, achieving consistent improvements across multiple mainstream backbones. Ablation studies confirm that both the EFE-guided observation and the adaptive learning mechanism are crucial to the performance gains. This work offers an interpretable and scalable paradigm for temporal behavior modeling under low-resource and noisy conditions, with broad applicability to wearable sensing, HCI, and clinical emotion monitoring.
LLMTM: Benchmarking and Optimizing LLMs for Temporal Motif Analysis in Dynamic Graphs
Dec 24, 2025The widespread application of Large Language Models (LLMs) has motivated a growing interest in their capacity for processing dynamic graphs. Temporal motifs, as an elementary unit and important local property of dynamic graphs which can directly reflect anomalies and unique phenomena, are essential for understanding their evolutionary dynamics and structural features. However, leveraging LLMs for temporal motif analysis on dynamic graphs remains relatively unexplored. In this paper, we systematically study LLM performance on temporal motif-related tasks. Specifically, we propose a comprehensive benchmark, LLMTM (Large Language Models in Temporal Motifs), which includes six tailored tasks across nine temporal motif types. We then conduct extensive experiments to analyze the impacts of different prompting techniques and LLMs (including nine models: openPangu-7B, the DeepSeek-R1-Distill-Qwen series, Qwen2.5-32B-Instruct, GPT-4o-mini, DeepSeek-R1, and o3) on model performance. Informed by our benchmark findings, we develop a tool-augmented LLM agent that leverages precisely engineered prompts to solve these tasks with high accuracy. Nevertheless, the high accuracy of the agent incurs a substantial cost. To address this trade-off, we propose a simple yet effective structure-aware dispatcher that considers both the dynamic graph's structural properties and the LLM's cognitive load to intelligently dispatch queries between the standard LLM prompting and the more powerful agent. Our experiments demonstrate that the structure-aware dispatcher effectively maintains high accuracy while reducing cost.
SkillGen: Learning Domain Skills for In-Context Sequential Decision Making
Nov 18, 2025Large language models (LLMs) are increasingly applied to sequential decision-making through in-context learning (ICL), yet their effectiveness is highly sensitive to prompt quality. Effective prompts should meet three principles: focus on decision-critical information, provide step-level granularity, and minimize reliance on expert annotations through label efficiency. However, existing ICL methods often fail to satisfy all three criteria simultaneously. Motivated by these challenges, we introduce SkillGen, a skill-based ICL framework for structured sequential reasoning. It constructs an action-centric, domain-level graph from sampled trajectories, identifies high-utility actions via temporal-difference credit assignment, and retrieves step-wise skills to generate fine-grained, context-aware prompts. We further present a theoretical analysis showing that focusing on high-utility segments supports task identifiability and informs more effective ICL prompt design. Experiments on ALFWorld, BabyAI, and ScienceWorld, using both open-source and proprietary LLMs, show that SkillGen achieves consistent gains, improving progress rate by 5.9%-16.5% on average across models.
Out-of-Distribution Detection with Positive and Negative Prompt Supervision Using Large Language Models
Nov 14, 2025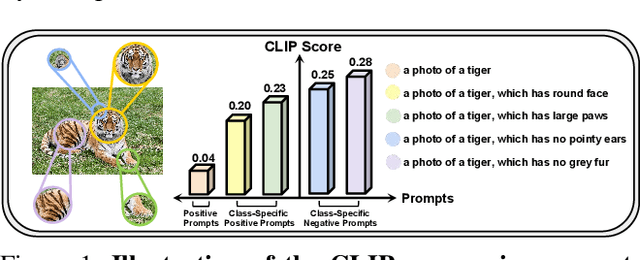
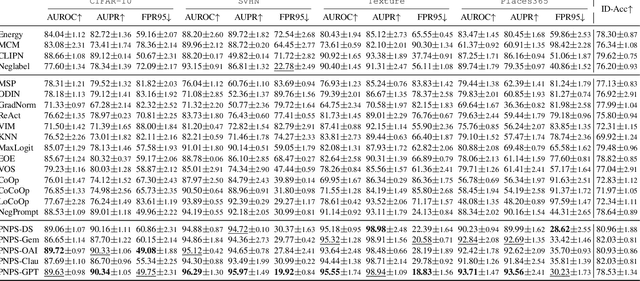
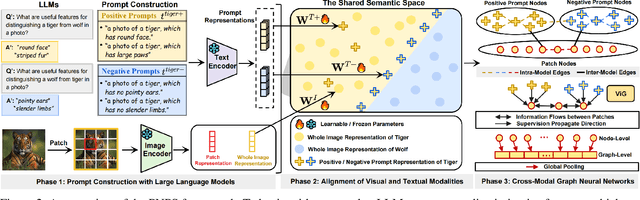
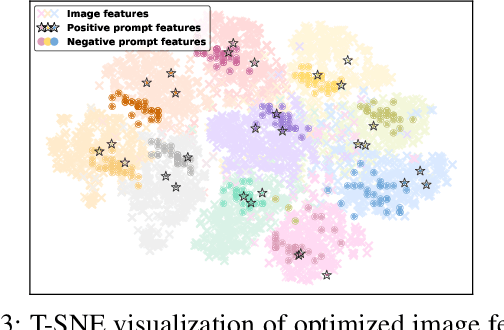
Out-of-distribution (OOD) detection is committed to delineating the classification boundaries between in-distribution (ID) and OOD images. Recent advances in vision-language models (VLMs) have demonstrated remarkable OOD detection performance by integrating both visual and textual modalities. In this context, negative prompts are introduced to emphasize the dissimilarity between image features and prompt content. However, these prompts often include a broad range of non-ID features, which may result in suboptimal outcomes due to the capture of overlapping or misleading information. To address this issue, we propose Positive and Negative Prompt Supervision, which encourages negative prompts to capture inter-class features and transfers this semantic knowledge to the visual modality to enhance OOD detection performance. Our method begins with class-specific positive and negative prompts initialized by large language models (LLMs). These prompts are subsequently optimized, with positive prompts focusing on features within each class, while negative prompts highlight features around category boundaries. Additionally, a graph-based architecture is employed to aggregate semantic-aware supervision from the optimized prompt representations and propagate it to the visual branch, thereby enhancing the performance of the energy-based OOD detector. Extensive experiments on two benchmarks, CIFAR-100 and ImageNet-1K, across eight OOD datasets and five different LLMs, demonstrate that our method outperforms state-of-the-art baselines.
Addressing Graph Anomaly Detection via Causal Edge Separation and Spectrum
Aug 20, 2025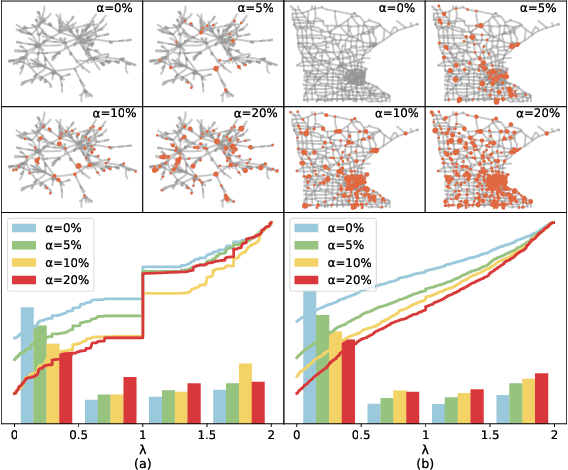
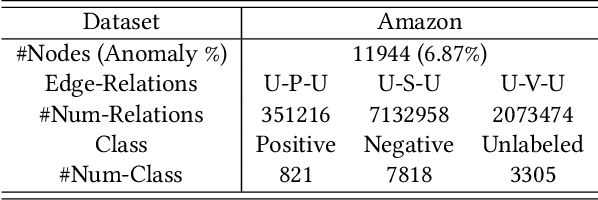
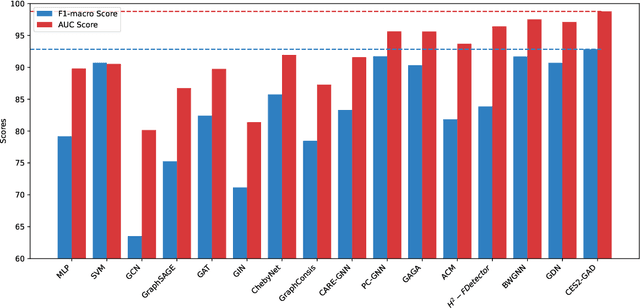
In the real world, anomalous entities often add more legitimate connections while hiding direct links with other anomalous entities, leading to heterophilic structures in anomalous networks that most GNN-based techniques fail to address. Several works have been proposed to tackle this issue in the spatial domain. However, these methods overlook the complex relationships between node structure encoding, node features, and their contextual environment and rely on principled guidance, research on solving spectral domain heterophilic problems remains limited. This study analyzes the spectral distribution of nodes with different heterophilic degrees and discovers that the heterophily of anomalous nodes causes the spectral energy to shift from low to high frequencies. To address the above challenges, we propose a spectral neural network CES2-GAD based on causal edge separation for anomaly detection on heterophilic graphs. Firstly, CES2-GAD will separate the original graph into homophilic and heterophilic edges using causal interventions. Subsequently, various hybrid-spectrum filters are used to capture signals from the segmented graphs. Finally, representations from multiple signals are concatenated and input into a classifier to predict anomalies. Extensive experiments with real-world datasets have proven the effectiveness of the method we proposed.
Mitigating Message Imbalance in Fraud Detection with Dual-View Graph Representation Learning
Jul 09, 2025Graph representation learning has become a mainstream method for fraud detection due to its strong expressive power, which focuses on enhancing node representations through improved neighborhood knowledge capture. However, the focus on local interactions leads to imbalanced transmission of global topological information and increased risk of node-specific information being overwhelmed during aggregation due to the imbalance between fraud and benign nodes. In this paper, we first summarize the impact of topology and class imbalance on downstream tasks in GNN-based fraud detection, as the problem of imbalanced supervisory messages is caused by fraudsters' topological behavior obfuscation and identity feature concealment. Based on statistical validation, we propose a novel dual-view graph representation learning method to mitigate Message imbalance in Fraud Detection(MimbFD). Specifically, we design a topological message reachability module for high-quality node representation learning to penetrate fraudsters' camouflage and alleviate insufficient propagation. Then, we introduce a local confounding debiasing module to adjust node representations, enhancing the stable association between node representations and labels to balance the influence of different classes. Finally, we conducted experiments on three public fraud datasets, and the results demonstrate that MimbFD exhibits outstanding performance in fraud detection.
Out-of-Distribution Detection in Heterogeneous Graphs via Energy Propagation
Apr 29, 2025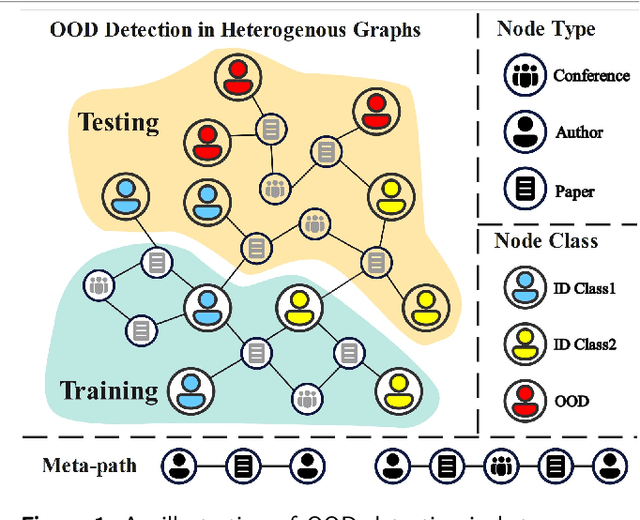
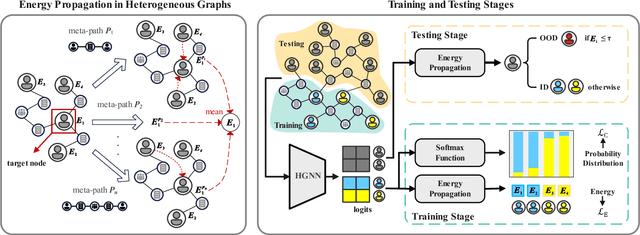
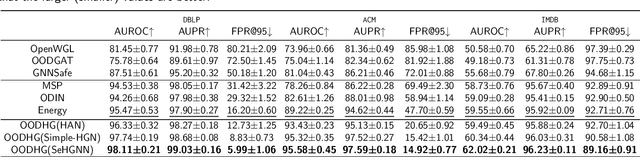
Graph neural networks (GNNs) are proven effective in extracting complex node and structural information from graph data. While current GNNs perform well in node classification tasks within in-distribution (ID) settings, real-world scenarios often present distribution shifts, leading to the presence of out-of-distribution (OOD) nodes. OOD detection in graphs is a crucial and challenging task. Most existing research focuses on homogeneous graphs, but real-world graphs are often heterogeneous, consisting of diverse node and edge types. This heterogeneity adds complexity and enriches the informational content. To the best of our knowledge, OOD detection in heterogeneous graphs remains an underexplored area. In this context, we propose a novel methodology for OOD detection in heterogeneous graphs (OODHG) that aims to achieve two main objectives: 1) detecting OOD nodes and 2) classifying all ID nodes based on the first task's results. Specifically, we learn representations for each node in the heterogeneous graph, calculate energy values to determine whether nodes are OOD, and then classify ID nodes. To leverage the structural information of heterogeneous graphs, we introduce a meta-path-based energy propagation mechanism and an energy constraint to enhance the distinction between ID and OOD nodes. Extensive experimental findings substantiate the simplicity and effectiveness of OODHG, demonstrating its superiority over baseline models in OOD detection tasks and its accuracy in ID node classification.
Hypergraph-Based Dynamic Graph Node Classification
Dec 29, 2024



Node classification on static graphs has achieved significant success, but achieving accurate node classification on dynamic graphs where node topology, attributes, and labels change over time has not been well addressed. Existing methods based on RNNs and self-attention only aggregate features of the same node across different time slices, which cannot adequately address and capture the diverse dynamic changes in dynamic graphs. Therefore, we propose a novel model named Hypergraph-Based Multi-granularity Dynamic Graph Node Classification (HYDG). After obtaining basic node representations for each slice through a GNN backbone, HYDG models the representations of each node in the dynamic graph through two modules. The individual-level hypergraph captures the spatio-temporal node representations between individual nodes, while the group-level hypergraph captures the multi-granularity group temporal representations among nodes of the same class. Each hyperedge captures different temporal dependencies of varying lengths by connecting multiple nodes within specific time ranges. More accurate representations are obtained through weighted information propagation and aggregation by the hypergraph neural network. Extensive experiments on five real dynamic graph datasets using two GNN backbones demonstrate the superiority of our proposed framework.
ULMRec: User-centric Large Language Model for Sequential Recommendation
Dec 07, 2024Recent advances in Large Language Models (LLMs) have demonstrated promising performance in sequential recommendation tasks, leveraging their superior language understanding capabilities. However, existing LLM-based recommendation approaches predominantly focus on modeling item-level co-occurrence patterns while failing to adequately capture user-level personalized preferences. This is problematic since even users who display similar behavioral patterns (e.g., clicking or purchasing similar items) may have fundamentally different underlying interests. To alleviate this problem, in this paper, we propose ULMRec, a framework that effectively integrates user personalized preferences into LLMs for sequential recommendation. Considering there has the semantic gap between item IDs and LLMs, we replace item IDs with their corresponding titles in user historical behaviors, enabling the model to capture the item semantics. For integrating the user personalized preference, we design two key components: (1) user indexing: a personalized user indexing mechanism that leverages vector quantization on user reviews and user IDs to generate meaningful and unique user representations, and (2) alignment tuning: an alignment-based tuning stage that employs comprehensive preference alignment tasks to enhance the model's capability in capturing personalized information. Through this design, ULMRec achieves deep integration of language semantics with user personalized preferences, facilitating effective adaptation to recommendation. Extensive experiments on two public datasets demonstrate that ULMRec significantly outperforms existing methods, validating the effectiveness of our approach.
MLDGG: Meta-Learning for Domain Generalization on Graphs
Nov 19, 2024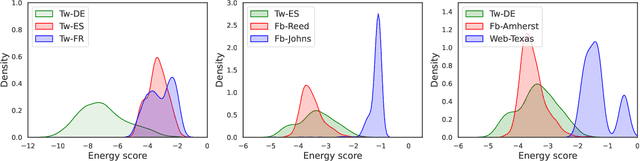

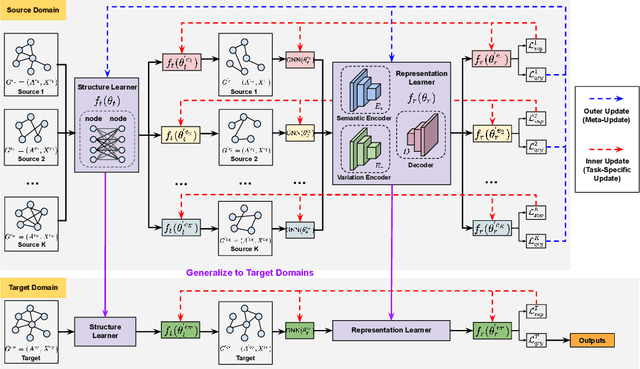
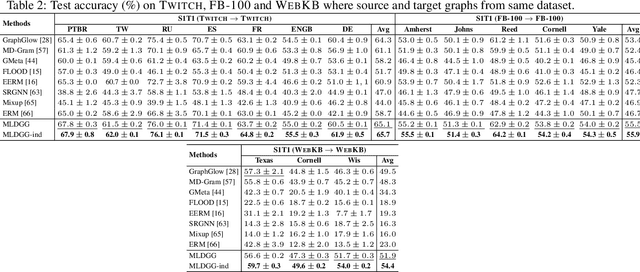
Domain generalization on graphs aims to develop models with robust generalization capabilities, ensuring effective performance on the testing set despite disparities between testing and training distributions. However, existing methods often rely on static encoders directly applied to the target domain, constraining its flexible adaptability. In contrast to conventional methodologies, which concentrate on developing specific generalized models, our framework, MLDGG, endeavors to achieve adaptable generalization across diverse domains by integrating cross-multi-domain meta-learning with structure learning and semantic identification. Initially, it introduces a generalized structure learner to mitigate the adverse effects of task-unrelated edges, enhancing the comprehensiveness of representations learned by Graph Neural Networks (GNNs) while capturing shared structural information across domains. Subsequently, a representation learner is designed to disentangle domain-invariant semantic and domain-specific variation information in node embedding by leveraging causal reasoning for semantic identification, further enhancing generalization. In the context of meta-learning, meta-parameters for both learners are optimized to facilitate knowledge transfer and enable effective adaptation to graphs through fine-tuning within the target domains, where target graphs are inaccessible during training. Our empirical results demonstrate that MLDGG surpasses baseline methods, showcasing its effectiveness in three different distribution shift settings.