 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLEAM: A Multimodal Imaging Dataset and HAMM for Glaucoma Classification
Mar 13, 2026We propose glaucoma lesion evaluation and analysis with multimodal imaging (GLEAM), the first publicly available tri-modal glaucoma dataset comprising scanning laser ophthalmoscopy fundus images, circumpapillary OCT images, and visual field pattern deviation maps, annotated with four disease stages, enabling effective exploitation of multimodal complementary information and facilitating accurate diagnosis and treatment across disease stages. To effectively integrate cross-modal information, we propose hierarchical attentive masked modeling (HAMM) for multimodal glaucoma classification. Our framework employs hierarchical attentive encoders and light decoders to focus cross-modal representation learning on the encoder.
LEGATO: Good Identity Unlearning Is Continuous
Jan 07, 2026Machine unlearning has become a crucial role in enabling generative models trained on large datasets to remove sensitive, private, or copyright-protected data. However, existing machine unlearning methods face three challenges in learning to forget identity of generative models: 1) inefficient, where identity erasure requires fine-tuning all the model's parameters; 2) limited controllability, where forgetting intensity cannot be controlled and explainability is lacking; 3) catastrophic collapse, where the model's retention capability undergoes drastic degradation as forgetting progresses. Forgetting has typically been handled through discrete and unstable updates, often requiring full-model fine-tuning and leading to catastrophic collapse. In this work, we argue that identity forgetting should be modeled as a continuous trajectory, and introduce LEGATO - Learn to ForgEt Identity in GenerAtive Models via Trajectory-consistent Neural Ordinary Differential Equations. LEGATO augments pre-trained generators with fine-tunable lightweight Neural ODE adapters, enabling smooth, controllable forgetting while keeping the original model weights frozen. This formulation allows forgetting intensity to be precisely modulated via ODE step size, offering interpretability and robustness. To further ensure stability, we introduce trajectory consistency constraints that explicitly prevent catastrophic collapse during unlearning. Extensive experiments across in-domain and out-of-domain identity unlearning benchmarks show that LEGATO achieves state-of-the-art forgetting performance, avoids catastrophic collapse and reduces fine-tuned parameters.
DeCoP: Enhancing Self-Supervised Time Series Representation with Dependency Controlled Pre-training
Sep 18, 2025Modeling dynamic temporal dependencies is a critical challenge in time series pre-training, which evolve due to distribution shifts and multi-scale patterns. This temporal variability severely impairs the generalization of pre-trained models to downstream tasks. Existing frameworks fail to capture the complex interactions of short- and long-term dependencies, making them susceptible to spurious correlations that degrade generalization. To address these limitations, we propose DeCoP, a Dependency Controlled Pre-training framework that explicitly models dynamic, multi-scale dependencies by simulating evolving inter-patch dependencies. At the input level, DeCoP introduces Instance-wise Patch Normalization (IPN) to mitigate distributional shifts while preserving the unique characteristics of each patch, creating a robust foundation for representation learning. At the latent level, a hierarchical Dependency Controlled Learning (DCL) strategy explicitly models inter-patch dependencies across multiple temporal scales, with an Instance-level Contrastive Module (ICM) enhances global generalization by learning instance-discriminative representations from time-invariant positive pairs. DeCoP achieves state-of-the-art results on ten datasets with lower computing resources, improving MSE by 3% on ETTh1 over PatchTST using only 37% of the FLOPs.
MetaDD: Boosting Dataset Distillation with Neural Network Architecture-Invariant Generalization
Oct 07, 2024



Dataset distillation (DD) entails creating a refined, compact distilled dataset from a large-scale dataset to facilitate efficient training. A significant challenge in DD is the dependency between the distilled dataset and the neural network (NN) architecture used. Training a different NN architecture with a distilled dataset distilled using a specific architecture often results in diminished trainning performance for other architectures. This paper introduces MetaDD, designed to enhance the generalizability of DD across various NN architectures. Specifically, MetaDD partitions distilled data into meta features (i.e., the data's common characteristics that remain consistent across different NN architectures) and heterogeneous features (i.e., the data's unique feature to each NN architecture). Then, MetaDD employs an architecture-invariant loss function for multi-architecture feature alignment, which increases meta features and reduces heterogeneous features in distilled data. As a low-memory consumption component, MetaDD can be seamlessly integrated into any DD methodology. Experimental results demonstrate that MetaDD significantly improves performance across various DD methods. On the Distilled Tiny-Imagenet with Sre2L (50 IPC), MetaDD achieves cross-architecture NN accuracy of up to 30.1\%, surpassing the second-best method (GLaD) by 1.7\%.
Review-LLM: Harnessing Large Language Models for Personalized Review Generation
Jul 10, 2024
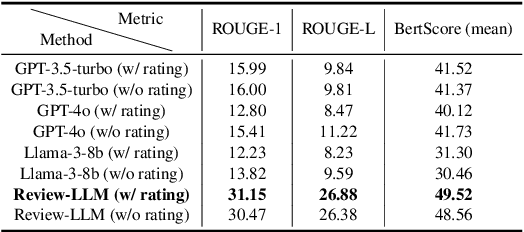
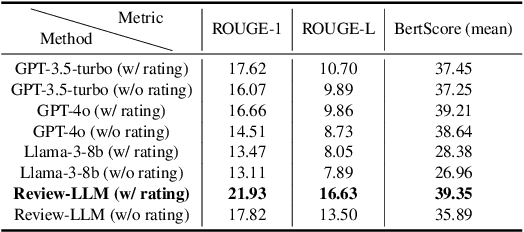
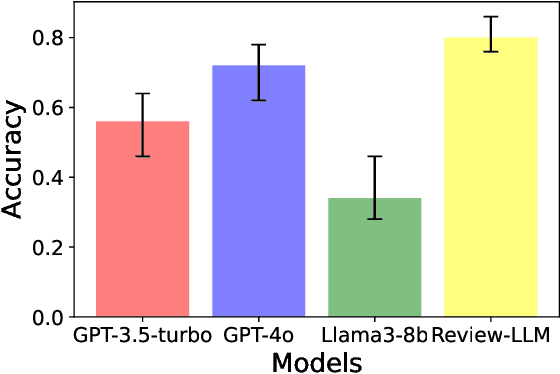
Product review generation is an important task in recommender systems, which could provide explanation and persuasiveness for the recommendation. Recently, Large Language Models (LLMs, e.g., ChatGPT) have shown superior text modeling and generating ability, which could be applied in review generation. However, directly applying the LLMs for generating reviews might be troubled by the ``polite'' phenomenon of the LLMs and could not generate personalized reviews (e.g., negative reviews). In this paper, we propose Review-LLM that customizes LLMs for personalized review generation. Firstly, we construct the prompt input by aggregating user historical behaviors, which include corresponding item titles and reviews. This enables the LLMs to capture user interest features and review writing style. Secondly, we incorporate ratings as indicators of satisfaction into the prompt, which could further improve the model's understanding of user preferences and the sentiment tendency control of generated reviews. Finally, we feed the prompt text into LLMs, and use Supervised Fine-Tuning (SFT) to make the model generate personalized reviews for the given user and target item. Experimental results on the real-world dataset show that our fine-tuned model could achieve better review generation performance than existing close-source LLMs.
Bucket Pre-training is All You Need
Jul 10, 2024


Large language models (LLMs) have demonstrated exceptional performance across various natural language processing tasks. However, the conventional fixed-length data composition strategy for pretraining, which involves concatenating and splitting documents, can introduce noise and limit the model's ability to capture long-range dependencies. To address this, we first introduce three metrics for evaluating data composition quality: padding ratio, truncation ratio, and concatenation ratio. We further propose a multi-bucket data composition method that moves beyond the fixed-length paradigm, offering a more flexible and efficient approach to pretraining. Extensive experiments demonstrate that our proposed method could significantly improving both the efficiency and efficacy of LLMs pretraining. Our approach not only reduces noise and preserves context but also accelerates training, making it a promising solution for LLMs pretraining.
PEPT: Expert Finding Meets Personalized Pre-training
Dec 19, 2023



Finding appropriate experts is essential in Community Question Answering (CQA) platforms as it enables the effective routing of questions to potential users who can provide relevant answers. The key is to personalized learning expert representations based on their historical answered questions, and accurately matching them with target questions. There have been some preliminary works exploring the usability of PLMs in expert finding, such as pre-training expert or question representations. However, these models usually learn pure text representations of experts from histories, disregarding personalized and fine-grained expert modeling. For alleviating this, we present a personalized pre-training and fine-tuning paradigm, which could effectively learn expert interest and expertise simultaneously. Specifically, in our pre-training framework, we integrate historical answered questions of one expert with one target question, and regard it as a candidate aware expert-level input unit. Then, we fuse expert IDs into the pre-training for guiding the model to model personalized expert representations, which can help capture the unique characteristics and expertise of each individual expert. Additionally, in our pre-training task, we design: 1) a question-level masked language model task to learn the relatedness between histories, enabling the modeling of question-level expert interest; 2) a vote-oriented task to capture question-level expert expertise by predicting the vote score the expert would receive. Through our pre-training framework and tasks, our approach could holistically learn expert representations including interests and expertise. Our method has been extensively evaluated on six real-world CQA datasets, and the experimental results consistently demonstrate the superiority of our approach over competitive baseline methods.
CNN-based Local Vision Transformer for COVID-19 Diagnosis
Jul 05, 2022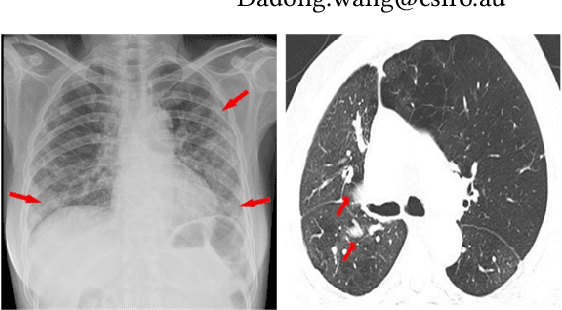

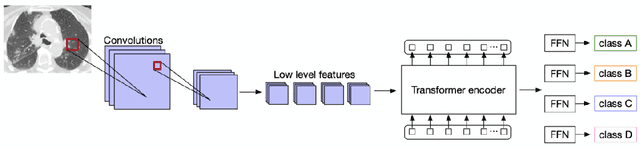

Deep learning technology can be used as an assistive technology to help doctors quickly and accurately identify COVID-19 infections. Recently, Vision Transformer (ViT) has shown great potential towards image classification due to its global receptive field. However, due to the lack of inductive biases inherent to CNNs, the ViT-based structure leads to limited feature richness and difficulty in model training. In this paper, we propose a new structure called Transformer for COVID-19 (COVT) to improve the performance of ViT-based architectures on small COVID-19 datasets. It uses CNN as a feature extractor to effectively extract local structural information, and introduces average pooling to ViT's Multilayer Perception(MLP) module for global information. Experiments show the effectiveness of our method on the two COVID-19 datasets and the ImageNet dataset.
Multi-scale alignment and Spatial ROI Module for COVID-19 Diagnosis
Jul 04, 2022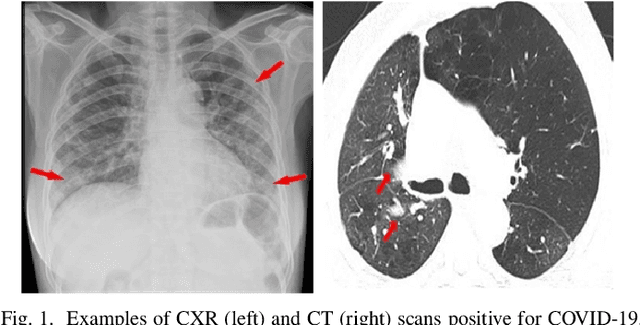
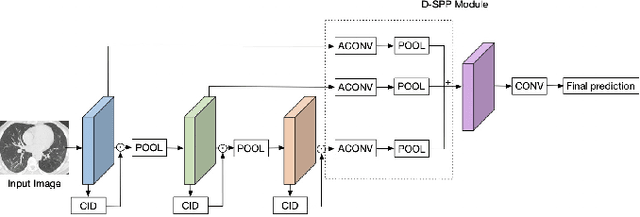
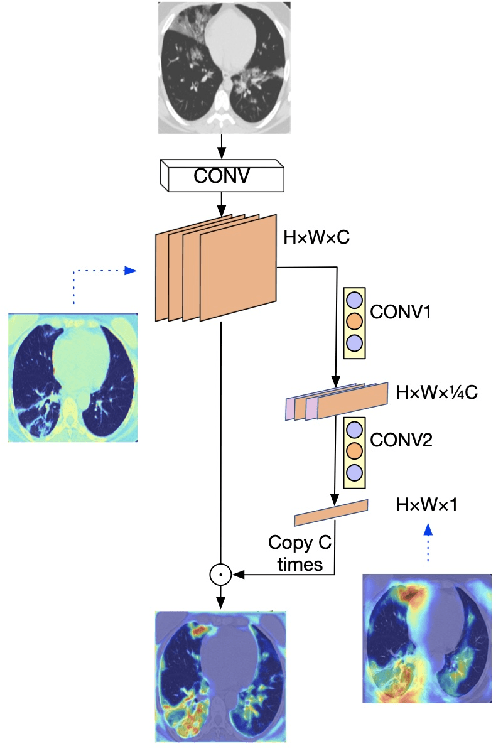
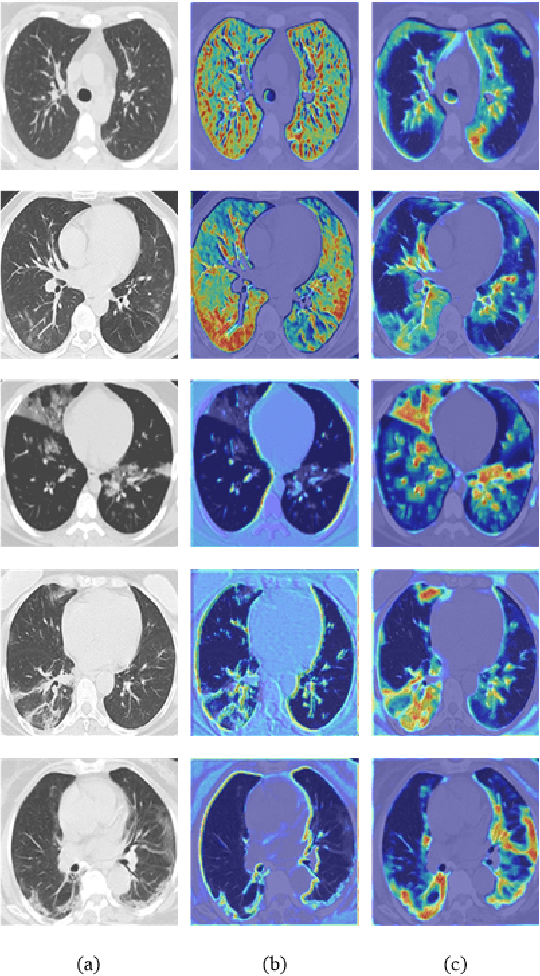
Coronavirus Disease 2019 (COVID-19) has spread globally and become a health crisis faced by humanity since first reported. Radiology imaging technologies such as computer tomography (CT) and chest X-ray imaging (CXR) are effective tools for diagnosing COVID-19. However, in CT and CXR images, the infected area occupies only a small part of the image. Some common deep learning methods that integrate large-scale receptive fields may cause the loss of image detail, resulting in the omission of the region of interest (ROI) in COVID-19 images and are therefore not suitable for further processing. To this end, we propose a deep spatial pyramid pooling (D-SPP) module to integrate contextual information over different resolutions, aiming to extract information under different scales of COVID-19 images effectively. Besides, we propose a COVID-19 infection detection (CID) module to draw attention to the lesion area and remove interference from irrelevant information. Extensive experiments on four CT and CXR datasets have shown that our method produces higher accuracy of detecting COVID-19 lesions in CT and CXR images. It can be used as a computer-aided diagnosis tool to help doctors effectively diagnose and screen for COVID-19.
Data Agnostic Filter Gating for Efficient Deep Networks
Oct 28, 2020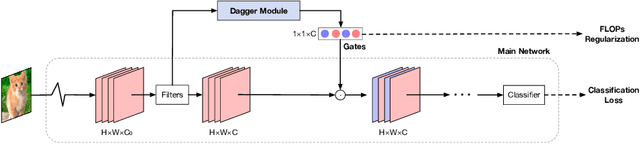
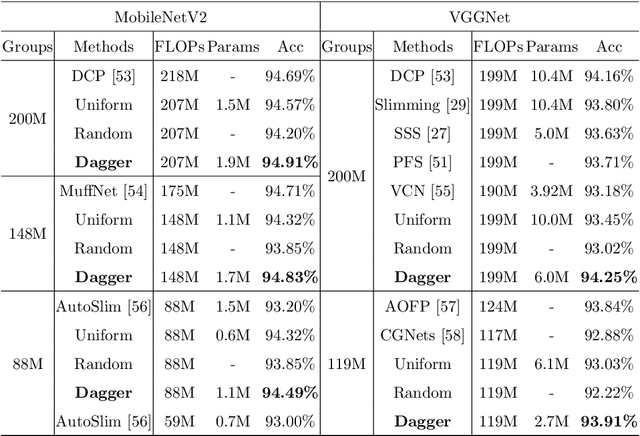
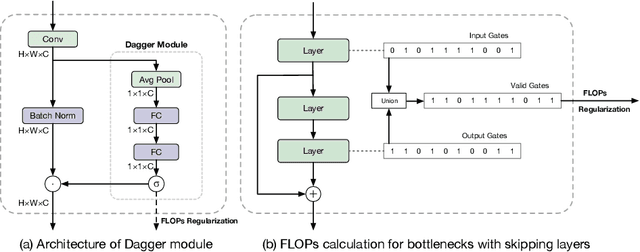
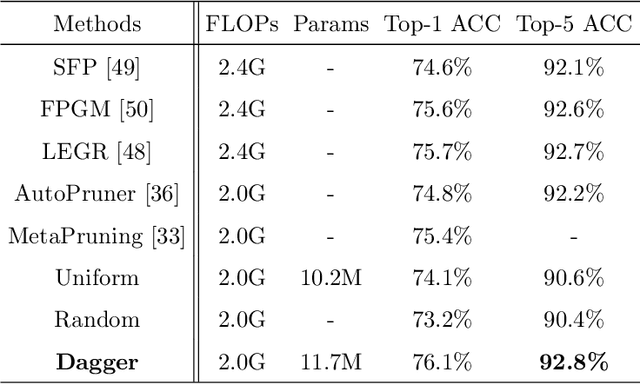
To deploy a well-trained CNN model on low-end computation edge devices, it is usually supposed to compress or prune the model under certain computation budget (e.g., FLOPs). Current filter pruning methods mainly leverage feature maps to generate important scores for filters and prune those with smaller scores, which ignores the variance of input batches to the difference in sparse structure over filters. In this paper, we propose a data agnostic filter pruning method that uses an auxiliary network named Dagger module to induce pruning and takes pretrained weights as input to learn the importance of each filter. In addition, to help prune filters with certain FLOPs constraints, we leverage an explicit FLOPs-aware regularization to directly promote pruning filters toward target FLOPs. Extensive experimental results on CIFAR-10 and ImageNet datasets indicate our superiority to other state-of-the-art filter pruning methods. For example, our 50\% FLOPs ResNet-50 can achieve 76.1\% Top-1 accuracy on ImageNet dataset, surpassing many other filter pruning methods.