 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Reasoning Abilities Under Non-Ideal Conditions After RL-Fine-Tuning
Aug 06, 2025Reinforcement learning (RL) has become a key technique for enhancing the reasoning abilities of large language models (LLMs), with policy-gradient algorithms dominating the post-training stage because of their efficiency and effectiveness. However, most existing benchmarks evaluate large-language-model reasoning under idealized settings, overlooking performance in realistic, non-ideal scenarios. We identify three representative non-ideal scenarios with practical relevance: summary inference, fine-grained noise suppression, and contextual filtering. We introduce a new research direction guided by brain-science findings that human reasoning remains reliable under imperfect inputs. We formally define and evaluate these challenging scenarios. We fine-tune three LLMs and a state-of-the-art large vision-language model (LVLM) using RL with a representative policy-gradient algorithm and then test their performance on eight public datasets. Our results reveal that while RL fine-tuning improves baseline reasoning under idealized settings, performance declines significantly across all three non-ideal scenarios, exposing critical limitations in advanced reasoning capabilities. Although we propose a scenario-specific remediation method, our results suggest current methods leave these reasoning deficits largely unresolved. This work highlights that the reasoning abilities of large models are often overstated and underscores the importance of evaluating models under non-ideal scenarios. The code and data will be released at XXXX.
COMM:Concentrated Margin Maximization for Robust Document-Level Relation Extraction
Mar 18, 2025
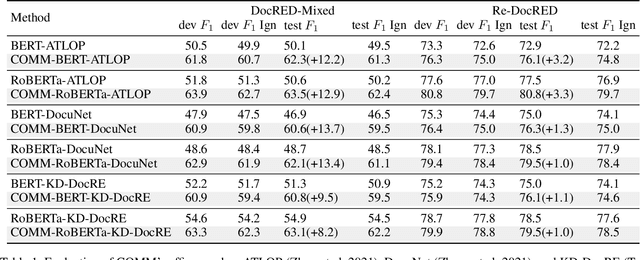
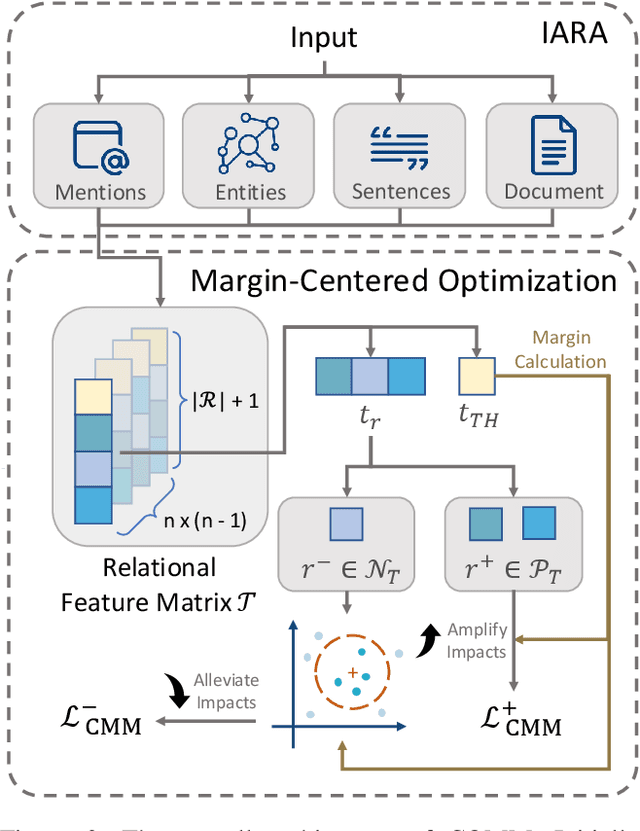

Document-level relation extraction (DocRE) is the process of identifying and extracting relations between entities that span multiple sentences within a document. Due to its realistic settings, DocRE has garnered increasing research attention in recent years. Previous research has mostly focused on developing sophisticated encoding models to better capture the intricate patterns between entity pairs. While these advancements are undoubtedly crucial, an even more foundational challenge lies in the data itself. The complexity inherent in DocRE makes the labeling process prone to errors, compounded by the extreme sparsity of positive relation samples, which is driven by both the limited availability of positive instances and the broad diversity of positive relation types. These factors can lead to biased optimization processes, further complicating the task of accurate relation extraction. Recognizing these challenges, we have developed a robust framework called \textit{\textbf{COMM}} to better solve DocRE. \textit{\textbf{COMM}} operates by initially employing an instance-aware reasoning method to dynamically capture pertinent information of entity pairs within the document and extract relational features. Following this, \textit{\textbf{COMM}} takes into account the distribution of relations and the difficulty of samples to dynamically adjust the margins between prediction logits and the decision threshold, a process we call Concentrated Margin Maximization. In this way, \textit{\textbf{COMM}} not only enhances the extraction of relevant relational features but also boosts DocRE performance by addressing the specific challenges posed by the data. Extensive experiments and analysis demonstrate the versatility and effectiveness of \textit{\textbf{COMM}}, especially its robustness when trained on low-quality data (achieves \textgreater 10\% performance gains).
Brain Inspired Adaptive Memory Dual-Net for Few-Shot Image Classification
Mar 10, 2025Few-shot image classification has become a popular research topic for its wide application in real-world scenarios, however the problem of supervision collapse induced by single image-level annotation remains a major challenge. Existing methods aim to tackle this problem by locating and aligning relevant local features. However, the high intra-class variability in real-world images poses significant challenges in locating semantically relevant local regions under few-shot settings. Drawing inspiration from the human's complementary learning system, which excels at rapidly capturing and integrating semantic features from limited examples, we propose the generalization-optimized Systems Consolidation Adaptive Memory Dual-Network, SCAM-Net. This approach simulates the systems consolidation of complementary learning system with an adaptive memory module, which successfully addresses the difficulty of identifying meaningful features in few-shot scenarios. Specifically, we construct a Hippocampus-Neocortex dual-network that consolidates structured representation of each category, the structured representation is then stored and adaptively regulated following the generalization optimization principle in a long-term memory inside Neocortex. Extensive experiments on benchmark datasets show that the proposed model has achieved state-of-the-art performance.
MetaDD: Boosting Dataset Distillation with Neural Network Architecture-Invariant Generalization
Oct 07, 2024



Dataset distillation (DD) entails creating a refined, compact distilled dataset from a large-scale dataset to facilitate efficient training. A significant challenge in DD is the dependency between the distilled dataset and the neural network (NN) architecture used. Training a different NN architecture with a distilled dataset distilled using a specific architecture often results in diminished trainning performance for other architectures. This paper introduces MetaDD, designed to enhance the generalizability of DD across various NN architectures. Specifically, MetaDD partitions distilled data into meta features (i.e., the data's common characteristics that remain consistent across different NN architectures) and heterogeneous features (i.e., the data's unique feature to each NN architecture). Then, MetaDD employs an architecture-invariant loss function for multi-architecture feature alignment, which increases meta features and reduces heterogeneous features in distilled data. As a low-memory consumption component, MetaDD can be seamlessly integrated into any DD methodology. Experimental results demonstrate that MetaDD significantly improves performance across various DD methods. On the Distilled Tiny-Imagenet with Sre2L (50 IPC), MetaDD achieves cross-architecture NN accuracy of up to 30.1\%, surpassing the second-best method (GLaD) by 1.7\%.
TA&AT: Enhancing Task-Oriented Dialog with Turn-Level Auxiliary Tasks and Action-Tree Based Scheduled Sampling
Jan 28, 2024



Task-oriented dialog systems have witnessed substantial progress due to conversational pre-training techniques. Yet, two significant challenges persist. First, most systems primarily utilize the latest turn's state label for the generator. This practice overlooks the comprehensive value of state labels in boosting the model's understanding for future generations. Second, an overreliance on generated policy often leads to error accumulation, resulting in suboptimal responses when adhering to incorrect actions. To combat these challenges, we propose turn-level multi-task objectives for the encoder. With the guidance of essential information from labeled intermediate states, we establish a more robust representation for both understanding and generation. For the decoder, we introduce an action tree-based scheduled sampling technique. Specifically, we model the hierarchical policy as trees and utilize the similarity between trees to sample negative policy based on scheduled sampling, hoping the model to generate invariant responses under perturbations. This method simulates potential pitfalls by sampling similar negative policy, bridging the gap between task-oriented dialog training and inference. Among methods without continual pre-training, our approach achieved state-of-the-art (SOTA) performance on the MultiWOZ dataset series and was also competitive with pre-trained SOTA methods.
FlexKBQA: A Flexible LLM-Powered Framework for Few-Shot Knowledge Base Question Answering
Aug 23, 2023



Knowledge base question answering (KBQA) is a critical yet challenging task due to the vast number of entities within knowledge bases and the diversity of natural language questions posed by users. Unfortunately, the performance of most KBQA models tends to decline significantly in real-world scenarios where high-quality annotated data is insufficient. To mitigate the burden associated with manual annotation, we introduce FlexKBQA by utilizing Large Language Models (LLMs) as program translators for addressing the challenges inherent in the few-shot KBQA task. Specifically, FlexKBQA leverages automated algorithms to sample diverse programs, such as SPARQL queries, from the knowledge base, which are subsequently converted into natural language questions via LLMs. This synthetic dataset facilitates training a specialized lightweight model for the KB. Additionally, to reduce the barriers of distribution shift between synthetic data and real user questions, FlexKBQA introduces an executionguided self-training method to iterative leverage unlabeled user questions. Furthermore, we explore harnessing the inherent reasoning capability of LLMs to enhance the entire framework. Consequently, FlexKBQA delivers substantial flexibility, encompassing data annotation, deployment, and being domain agnostic. Through extensive experiments on GrailQA, WebQSP, and KQA Pro, we observe that under the few-shot even the more challenging zero-shot scenarios, FlexKBQA achieves impressive results with a few annotations, surpassing all previous baselines and even approaching the performance of supervised models, achieving a remarkable 93% performance relative to the fully-supervised models. We posit that FlexKBQA represents a significant advancement towards exploring better integration of large and lightweight models. The code is open-sourced.
Can LLMs like GPT-4 outperform traditional AI tools in dementia diagnosis? Maybe, but not today
Jun 02, 2023



Recent investigations show that large language models (LLMs), specifically GPT-4, not only have remarkable capabilities in common Natural Language Processing (NLP) tasks but also exhibit human-level performance on various professional and academic benchmarks. However, whether GPT-4 can be directly used in practical applications and replace traditional artificial intelligence (AI) tools in specialized domains requires further experimental validation. In this paper, we explore the potential of LLMs such as GPT-4 to outperform traditional AI tools in dementia diagnosis. Comprehensive comparisons between GPT-4 and traditional AI tools are conducted to examine their diagnostic accuracy in a clinical setting. Experimental results on two real clinical datasets show that, although LLMs like GPT-4 demonstrate potential for future advancements in dementia diagnosis, they currently do not surpass the performance of traditional AI tools. The interpretability and faithfulness of GPT-4 are also evaluated by comparison with real doctors. We discuss the limitations of GPT-4 in its current state and propose future research directions to enhance GPT-4 in dementia diagnosis.
Bridging the Language Gap: Knowledge Injected Multilingual Question Answering
Apr 06, 2023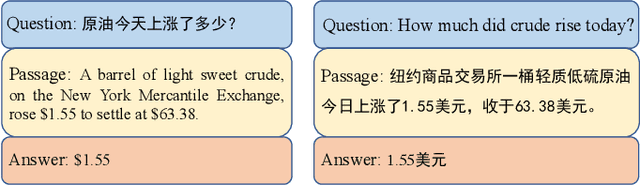
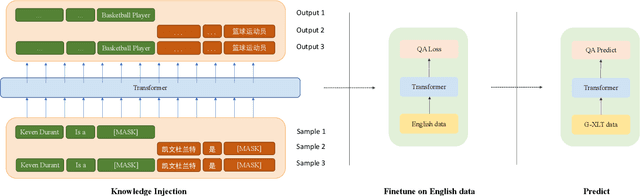
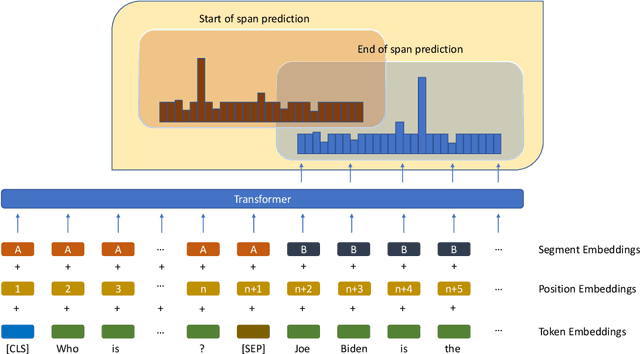

Question Answering (QA) is the task of automatically answering questions posed by humans in natural languages. There are different settings to answer a question, such as abstractive, extractive, boolean, and multiple-choice QA. As a popular topic in natural language processing tasks, extractive question answering task (extractive QA) has gained extensive attention in the past few years. With the continuous evolvement of the world, generalized cross-lingual transfer (G-XLT), where question and answer context are in different languages, poses some unique challenges over cross-lingual transfer (XLT), where question and answer context are in the same language. With the boost of corresponding development of related benchmarks, many works have been done to improve the performance of various language QA tasks. However, only a few works are dedicated to the G-XLT task. In this work, we propose a generalized cross-lingual transfer framework to enhance the model's ability to understand different languages. Specifically, we first assemble triples from different languages to form multilingual knowledge. Since the lack of knowledge between different languages greatly limits models' reasoning ability, we further design a knowledge injection strategy via leveraging link prediction techniques to enrich the model storage of multilingual knowledge. In this way, we can profoundly exploit rich semantic knowledge. Experiment results on real-world datasets MLQA demonstrate that the proposed method can improve the performance by a large margin, outperforming the baseline method by 13.18%/12.00% F1/EM on average.
Toward a Unified Framework for Unsupervised Complex Tabular Reasoning
Dec 20, 2022
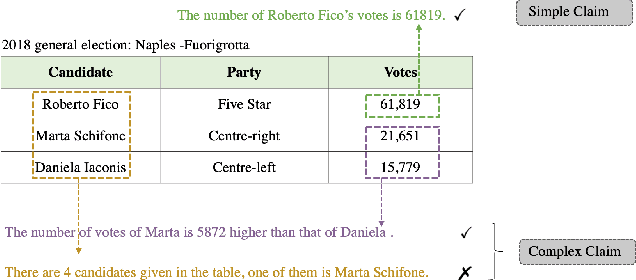

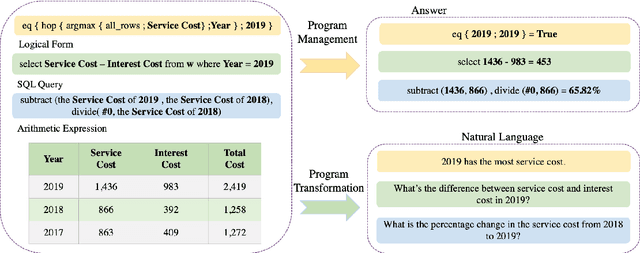
Structured tabular data exist across nearly all fields. Reasoning task over these data aims to answer questions or determine the truthiness of hypothesis sentences by understanding the semantic meaning of a table. While previous works have devoted significant efforts to the tabular reasoning task, they always assume there are sufficient labeled data. However, constructing reasoning samples over tables (and related text) is labor-intensive, especially when the reasoning process is complex. When labeled data is insufficient, the performance of models will suffer an unendurable decline. In this paper, we propose a unified framework for unsupervised complex tabular reasoning (UCTR), which generates sufficient and diverse synthetic data with complex logic for tabular reasoning tasks, assuming no human-annotated data at all. We first utilize a random sampling strategy to collect diverse programs of different types and execute them on tables based on a "Program-Executor" module. To bridge the gap between the programs and natural language sentences, we design a powerful "NL-Generator" module to generate natural language sentences with complex logic from these programs. Since a table often occurs with its surrounding texts, we further propose novel "Table-to-Text" and "Text-to-Table" operators to handle joint table-text reasoning scenarios. This way, we can adequately exploit the unlabeled table resources to obtain a well-performed reasoning model under an unsupervised setting. Our experiments cover different tasks (question answering and fact verification) and different domains (general and specific), showing that our unsupervised methods can achieve at most 93% performance compared to supervised models. We also find that it can substantially boost the supervised performance in low-resourced domains as a data augmentation technique. Our code is available at https://github.com/leezythu/UCTR.
Not Just Plain Text! Fuel Document-Level Relation Extraction with Explicit Syntax Refinement and Subsentence Modeling
Nov 10, 2022

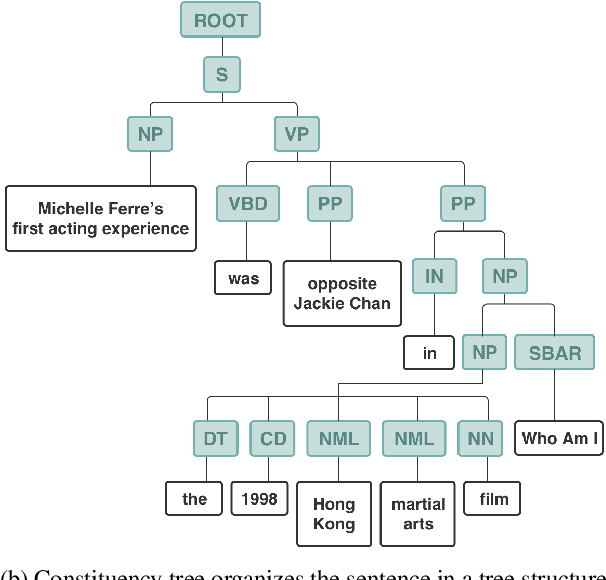
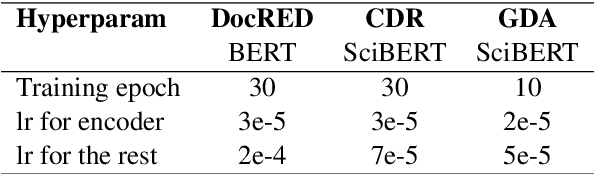
Document-level relation extraction (DocRE) aims to identify semantic labels among entities within a single document. One major challenge of DocRE is to dig decisive details regarding a specific entity pair from long text. However, in many cases, only a fraction of text carries required information, even in the manually labeled supporting evidence. To better capture and exploit instructive information, we propose a novel expLicit syntAx Refinement and Subsentence mOdeliNg based framework (LARSON). By introducing extra syntactic information, LARSON can model subsentences of arbitrary granularity and efficiently screen instructive ones. Moreover, we incorporate refined syntax into text representations which further improves the performance of LARSON. Experimental results on three benchmark datasets (DocRED, CDR, and GDA) demonstrate that LARSON significantly outperforms existing methods.