 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Just Plain Text! Fuel Document-Level Relation Extraction with Explicit Syntax Refinement and Subsentence Modeling
Paper and Code


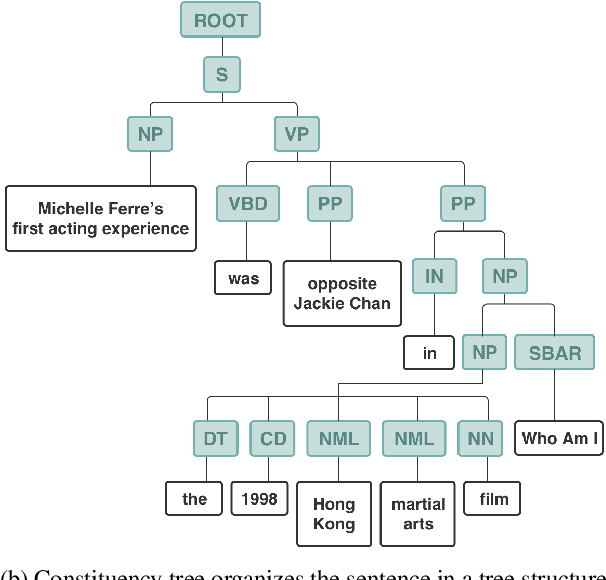
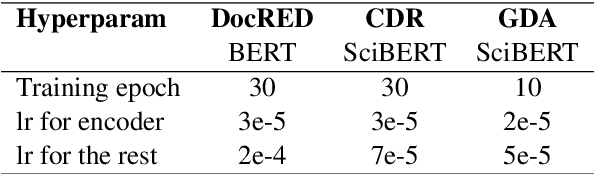
Document-level relation extraction (DocRE) aims to identify semantic labels among entities within a single document. One major challenge of DocRE is to dig decisive details regarding a specific entity pair from long text. However, in many cases, only a fraction of text carries required information, even in the manually labeled supporting evidence. To better capture and exploit instructive information, we propose a novel expLicit syntAx Refinement and Subsentence mOdeliNg based framework (LARSON). By introducing extra syntactic information, LARSON can model subsentences of arbitrary granularity and efficiently screen instructive ones. Moreover, we incorporate refined syntax into text representations which further improves the performance of LARSON. Experimental results on three benchmark datasets (DocRED, CDR, and GDA) demonstrate that LARSON significantly outperforms existing methods.