 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuningIQA: Fine-Grained Blind Image Quality Assessment for Livestreaming Camera Tuning
Aug 25, 2025



Livestreaming has become increasingly prevalent in modern visual communication, where automatic camera quality tuning is essential for delivering superior user Quality of Experience (QoE). Such tuning requires accurate blind image quality assessment (BIQA) to guide parameter optimization decisions. Unfortunately, the existing BIQA models typically only predict an overall coarse-grained quality score, which cannot provide fine-grained perceptual guidance for precise camera parameter tuning. To bridge this gap, we first establish FGLive-10K, a comprehensive fine-grained BIQA database containing 10,185 high-resolution images captured under varying camera parameter configurations across diverse livestreaming scenarios. The dataset features 50,925 multi-attribute quality annotations and 19,234 fine-grained pairwise preference annotations. Based on FGLive-10K, we further develop TuningIQA, a fine-grained BIQA metric for livestreaming camera tuning, which integrates human-aware feature extraction and graph-based camera parameter fusion. Extensive experiments and comparisons demonstrate that TuningIQA significantly outperforms state-of-the-art BIQA methods in both score regression and fine-grained quality ranking, achieving superior performance when deployed for livestreaming camera tuning.
COMM:Concentrated Margin Maximization for Robust Document-Level Relation Extraction
Mar 18, 2025
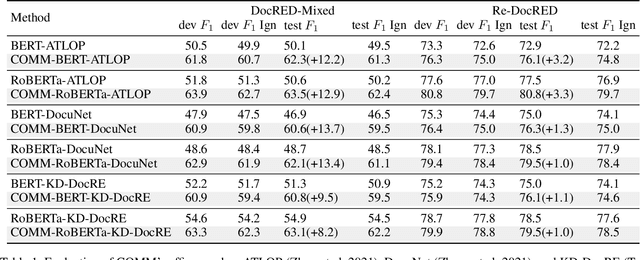
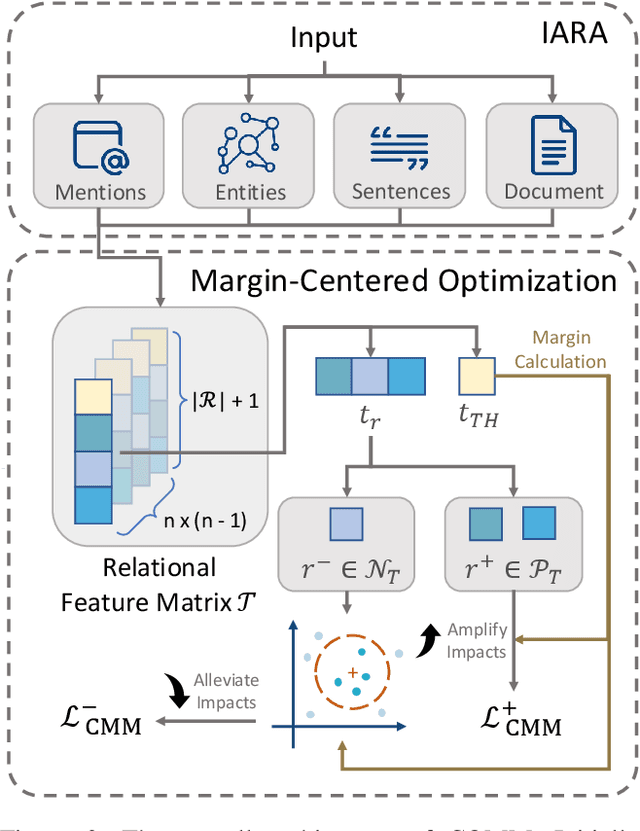

Document-level relation extraction (DocRE) is the process of identifying and extracting relations between entities that span multiple sentences within a document. Due to its realistic settings, DocRE has garnered increasing research attention in recent years. Previous research has mostly focused on developing sophisticated encoding models to better capture the intricate patterns between entity pairs. While these advancements are undoubtedly crucial, an even more foundational challenge lies in the data itself. The complexity inherent in DocRE makes the labeling process prone to errors, compounded by the extreme sparsity of positive relation samples, which is driven by both the limited availability of positive instances and the broad diversity of positive relation types. These factors can lead to biased optimization processes, further complicating the task of accurate relation extraction. Recognizing these challenges, we have developed a robust framework called \textit{\textbf{COMM}} to better solve DocRE. \textit{\textbf{COMM}} operates by initially employing an instance-aware reasoning method to dynamically capture pertinent information of entity pairs within the document and extract relational features. Following this, \textit{\textbf{COMM}} takes into account the distribution of relations and the difficulty of samples to dynamically adjust the margins between prediction logits and the decision threshold, a process we call Concentrated Margin Maximization. In this way, \textit{\textbf{COMM}} not only enhances the extraction of relevant relational features but also boosts DocRE performance by addressing the specific challenges posed by the data. Extensive experiments and analysis demonstrate the versatility and effectiveness of \textit{\textbf{COMM}}, especially its robustness when trained on low-quality data (achieves \textgreater 10\% performance gains).
FocusLLM: Scaling LLM's Context by Parallel Decoding
Aug 21, 2024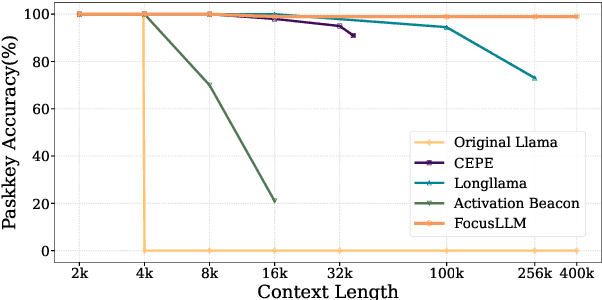

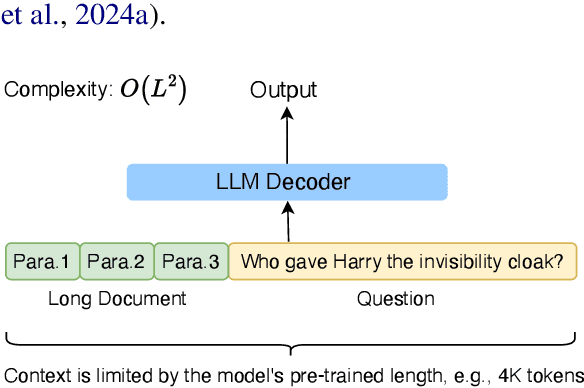

Empowering LLMs with the ability to utilize useful information from a long context is crucial for many downstream applications. However, achieving long context lengths with the conventional transformer architecture requires substantial training and inference resources. In this paper, we present FocusLLM, a framework designed to extend the context length of any decoder-only LLM, enabling the model to focus on relevant information from very long sequences. FocusLLM processes long text inputs by dividing them into chunks based on the model's original context length to alleviate the issue of attention distraction. Then, it appends the local context to each chunk as a prompt to extract essential information from each chunk based on a novel parallel decoding mechanism, and ultimately integrates the extracted information into the local context. FocusLLM stands out for great training efficiency and versatility: trained with an 8K input length with much less training cost than previous methods, FocusLLM exhibits superior performance across downstream long-context tasks and maintains strong language modeling ability when handling extensive long texts, even up to 400K tokens. Our code is available at https://github.com/leezythu/FocusLLM.
AesExpert: Towards Multi-modality Foundation Model for Image Aesthetics Perception
Apr 15, 2024



The highly abstract nature of image aesthetics perception (IAP) poses significant challenge for current multimodal large language models (MLLMs). The lack of human-annotated multi-modality aesthetic data further exacerbates this dilemma, resulting in MLLMs falling short of aesthetics perception capabilities. To address the above challenge, we first introduce a comprehensively annotated Aesthetic Multi-Modality Instruction Tuning (AesMMIT) dataset, which serves as the footstone for building multi-modality aesthetics foundation models. Specifically, to align MLLMs with human aesthetics perception, we construct a corpus-rich aesthetic critique database with 21,904 diverse-sourced images and 88K human natural language feedbacks, which are collected via progressive questions, ranging from coarse-grained aesthetic grades to fine-grained aesthetic descriptions. To ensure that MLLMs can handle diverse queries, we further prompt GPT to refine the aesthetic critiques and assemble the large-scale aesthetic instruction tuning dataset, i.e. AesMMIT, which consists of 409K multi-typed instructions to activate stronger aesthetic capabilities. Based on the AesMMIT database, we fine-tune the open-sourced general foundation models, achieving multi-modality Aesthetic Expert models, dubbed AesExpert. Extensive experiments demonstrate that the proposed AesExpert models deliver significantly better aesthetic perception performances than the state-of-the-art MLLMs, including the most advanced GPT-4V and Gemini-Pro-Vision. Source data will be available at https://github.com/yipoh/AesExpert.
FlexKBQA: A Flexible LLM-Powered Framework for Few-Shot Knowledge Base Question Answering
Aug 23, 2023



Knowledge base question answering (KBQA) is a critical yet challenging task due to the vast number of entities within knowledge bases and the diversity of natural language questions posed by users. Unfortunately, the performance of most KBQA models tends to decline significantly in real-world scenarios where high-quality annotated data is insufficient. To mitigate the burden associated with manual annotation, we introduce FlexKBQA by utilizing Large Language Models (LLMs) as program translators for addressing the challenges inherent in the few-shot KBQA task. Specifically, FlexKBQA leverages automated algorithms to sample diverse programs, such as SPARQL queries, from the knowledge base, which are subsequently converted into natural language questions via LLMs. This synthetic dataset facilitates training a specialized lightweight model for the KB. Additionally, to reduce the barriers of distribution shift between synthetic data and real user questions, FlexKBQA introduces an executionguided self-training method to iterative leverage unlabeled user questions. Furthermore, we explore harnessing the inherent reasoning capability of LLMs to enhance the entire framework. Consequently, FlexKBQA delivers substantial flexibility, encompassing data annotation, deployment, and being domain agnostic. Through extensive experiments on GrailQA, WebQSP, and KQA Pro, we observe that under the few-shot even the more challenging zero-shot scenarios, FlexKBQA achieves impressive results with a few annotations, surpassing all previous baselines and even approaching the performance of supervised models, achieving a remarkable 93% performance relative to the fully-supervised models. We posit that FlexKBQA represents a significant advancement towards exploring better integration of large and lightweight models. The code is open-sourced.
Bridging the Language Gap: Knowledge Injected Multilingual Question Answering
Apr 06, 2023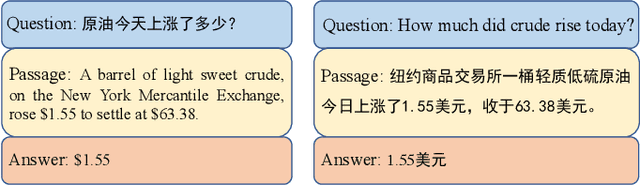
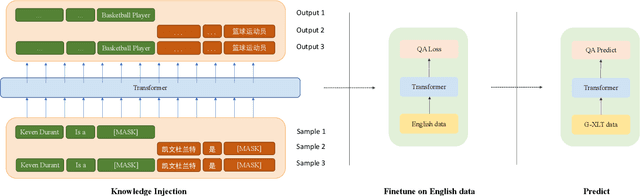
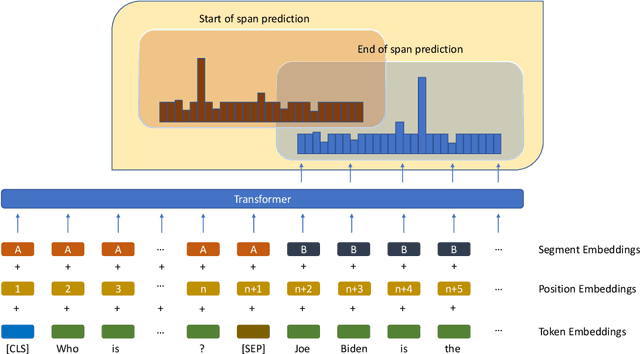

Question Answering (QA) is the task of automatically answering questions posed by humans in natural languages. There are different settings to answer a question, such as abstractive, extractive, boolean, and multiple-choice QA. As a popular topic in natural language processing tasks, extractive question answering task (extractive QA) has gained extensive attention in the past few years. With the continuous evolvement of the world, generalized cross-lingual transfer (G-XLT), where question and answer context are in different languages, poses some unique challenges over cross-lingual transfer (XLT), where question and answer context are in the same language. With the boost of corresponding development of related benchmarks, many works have been done to improve the performance of various language QA tasks. However, only a few works are dedicated to the G-XLT task. In this work, we propose a generalized cross-lingual transfer framework to enhance the model's ability to understand different languages. Specifically, we first assemble triples from different languages to form multilingual knowledge. Since the lack of knowledge between different languages greatly limits models' reasoning ability, we further design a knowledge injection strategy via leveraging link prediction techniques to enrich the model storage of multilingual knowledge. In this way, we can profoundly exploit rich semantic knowledge. Experiment results on real-world datasets MLQA demonstrate that the proposed method can improve the performance by a large margin, outperforming the baseline method by 13.18%/12.00% F1/EM on average.
Toward a Unified Framework for Unsupervised Complex Tabular Reasoning
Dec 20, 2022
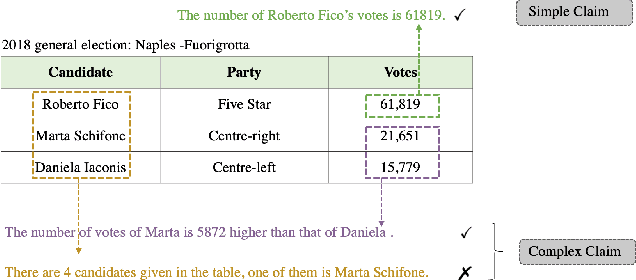

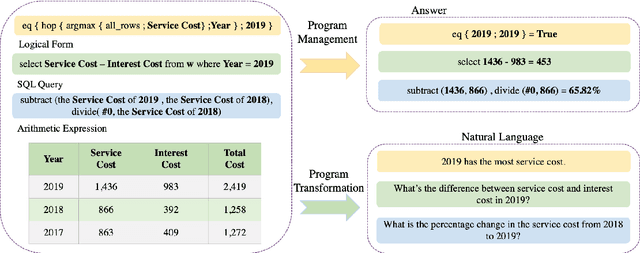
Structured tabular data exist across nearly all fields. Reasoning task over these data aims to answer questions or determine the truthiness of hypothesis sentences by understanding the semantic meaning of a table. While previous works have devoted significant efforts to the tabular reasoning task, they always assume there are sufficient labeled data. However, constructing reasoning samples over tables (and related text) is labor-intensive, especially when the reasoning process is complex. When labeled data is insufficient, the performance of models will suffer an unendurable decline. In this paper, we propose a unified framework for unsupervised complex tabular reasoning (UCTR), which generates sufficient and diverse synthetic data with complex logic for tabular reasoning tasks, assuming no human-annotated data at all. We first utilize a random sampling strategy to collect diverse programs of different types and execute them on tables based on a "Program-Executor" module. To bridge the gap between the programs and natural language sentences, we design a powerful "NL-Generator" module to generate natural language sentences with complex logic from these programs. Since a table often occurs with its surrounding texts, we further propose novel "Table-to-Text" and "Text-to-Table" operators to handle joint table-text reasoning scenarios. This way, we can adequately exploit the unlabeled table resources to obtain a well-performed reasoning model under an unsupervised setting. Our experiments cover different tasks (question answering and fact verification) and different domains (general and specific), showing that our unsupervised methods can achieve at most 93% performance compared to supervised models. We also find that it can substantially boost the supervised performance in low-resourced domains as a data augmentation technique. Our code is available at https://github.com/leezythu/UCTR.
Not Just Plain Text! Fuel Document-Level Relation Extraction with Explicit Syntax Refinement and Subsentence Modeling
Nov 10, 2022

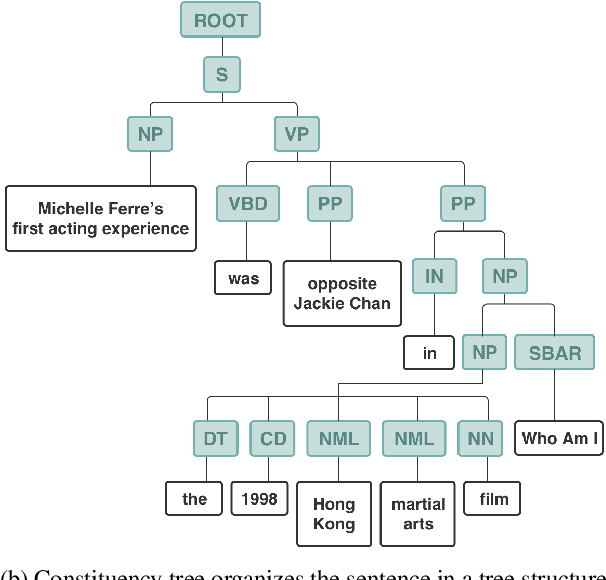
Document-level relation extraction (DocRE) aims to identify semantic labels among entities within a single document. One major challenge of DocRE is to dig decisive details regarding a specific entity pair from long text. However, in many cases, only a fraction of text carries required information, even in the manually labeled supporting evidence. To better capture and exploit instructive information, we propose a novel expLicit syntAx Refinement and Subsentence mOdeliNg based framework (LARSON). By introducing extra syntactic information, LARSON can model subsentences of arbitrary granularity and efficiently screen instructive ones. Moreover, we incorporate refined syntax into text representations which further improves the performance of LARSON. Experimental results on three benchmark datasets (DocRED, CDR, and GDA) demonstrate that LARSON significantly outperforms existing methods.