 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Yesterday's Error: An Efficient Online Learning Method for Traffic Demand Prediction
Feb 25, 2026Accurately predicting short-term traffic demand is critical for intelligent transportation systems. While deep learning models achieve strong performance under stationary conditions, their accuracy often degrades significantly when faced with distribution shifts caused by external events or evolving urban dynamics. Frequent model retraining to adapt to such changes incurs prohibitive computational costs, especially for large-scale or foundation models. To address this challenge, we propose FORESEE (Forecasting Online with Residual Smoothing and Ensemble Experts), a lightweight online adaptation framework that is accurate, robust, and computationally efficient. FORESEE operates without any parameter updates to the base model. Instead, it corrects today's forecast in each region using yesterday's prediction error, stabilized through exponential smoothing guided by a mixture-of-experts mechanism that adapts to recent error dynamics. Moreover, an adaptive spatiotemporal smoothing component propagates error signals across neighboring regions and time slots, capturing coherent shifts in demand patterns. Extensive experiments on seven real-world datasets with three backbone models demonstrate that FORESEE consistently improves prediction accuracy, maintains robustness even when distribution shifts are minimal (avoiding performance degradation), and achieves the lowest computational overhead among existing online methods. By enabling real-time adaptation of traffic forecasting models with negligible computational cost, FORESEE paves the way for deploying reliable, up-to-date prediction systems in dynamic urban environments. Code and data are available at https://github.com/xiannanhuang/FORESEE
AKG kernel Agent: A Multi-Agent Framework for Cross-Platform Kernel Synthesis
Dec 29, 2025Modern AI models demand high-performance computation kernels. The growing complexity of LLMs, multimodal architectures, and recommendation systems, combined with techniques like sparsity and quantization, creates significant computational challenges. Moreover, frequent hardware updates and diverse chip architectures further complicate this landscape, requiring tailored kernel implementations for each platform. However, manual optimization cannot keep pace with these demands, creating a critical bottleneck in AI system development. Recent advances in LLM code generation capabilities have opened new possibilities for automating kernel development. In this work, we propose AKG kernel agent (AI-driven Kernel Generator), a multi-agent system that automates kernel generation, migration, and performance tuning. AKG kernel agent is designed to support multiple domain-specific languages (DSLs), including Triton, TileLang, CPP, and CUDA-C, enabling it to target different hardware backends while maintaining correctness and portability. The system's modular design allows rapid integration of new DSLs and hardware targets. When evaluated on KernelBench using Triton DSL across GPU and NPU backends, AKG kernel agent achieves an average speedup of 1.46$\times$ over PyTorch Eager baselines implementations, demonstrating its effectiveness in accelerating kernel development for modern AI workloads.
P-FABRIK: A General Intuitive and Robust Inverse Kinematics Method for Parallel Mechanisms Using FABRIK Approach
Dec 28, 2025Traditional geometric inverse kinematics methods for parallel mechanisms rely on specific spatial geometry constraints. However, their application to redundant parallel mechanisms is challenged due to the increased constraint complexity. Moreover, it will output no solutions and cause unpredictable control problems when the target pose lies outside its workspace. To tackle these challenging issues, this work proposes P-FABRIK, a general, intuitive, and robust inverse kinematics method to find one feasible solution for diverse parallel mechanisms based on the FABRIK algorithm. By decomposing the general parallel mechanism into multiple serial sub-chains using a new topological decomposition strategy, the end targets of each sub-chain can be subsequently revised to calculate the inverse kinematics solutions iteratively. Multiple case studies involving planar, standard, and redundant parallel mechanisms demonstrated the proposed method's generality across diverse parallel mechanisms. Furthermore, numerical simulation studies verified its efficacy and computational efficiency, as well as its robustness ability to handle out-of-workspace targets.
VICTOR: Dataset Copyright Auditing in Video Recognition Systems
Dec 16, 2025Video recognition systems are increasingly being deployed in daily life, such as content recommendation and security monitoring. To enhance video recognition development, many institutions have released high-quality public datasets with open-source licenses for training advanced models. At the same time, these datasets are also susceptible to misuse and infringement. Dataset copyright auditing is an effective solution to identify such unauthorized use. However, existing dataset copyright solutions primarily focus on the image domain; the complex nature of video data leaves dataset copyright auditing in the video domain unexplored. Specifically, video data introduces an additional temporal dimension, which poses significant challenges to the effectiveness and stealthiness of existing methods. In this paper, we propose VICTOR, the first dataset copyright auditing approach for video recognition systems. We develop a general and stealthy sample modification strategy that enhances the output discrepancy of the target model. By modifying only a small proportion of samples (e.g., 1%), VICTOR amplifies the impact of published modified samples on the prediction behavior of the target models. Then, the difference in the model's behavior for published modified and unpublished original samples can serve as a key basis for dataset auditing. Extensive experiments on multiple models and datasets highlight the superiority of VICTOR. Finally, we show that VICTOR is robust in the presence of several perturbation mechanisms to the training videos or the target models.
Geometric Parameter Optimization of a Novel 3-(PP(2-(UPS))) Redundant Parallel Mechanism based on Workspace Determination
Dec 16, 2025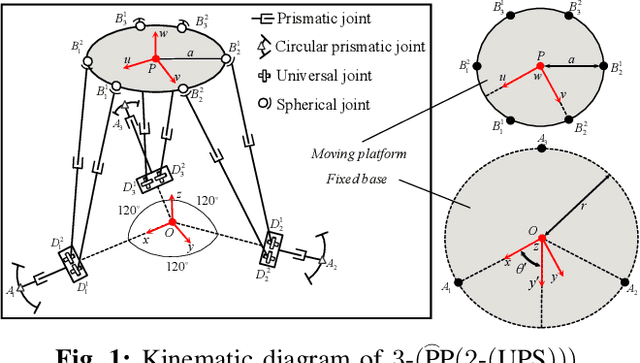
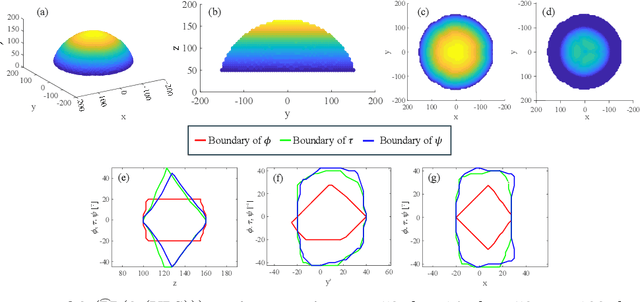
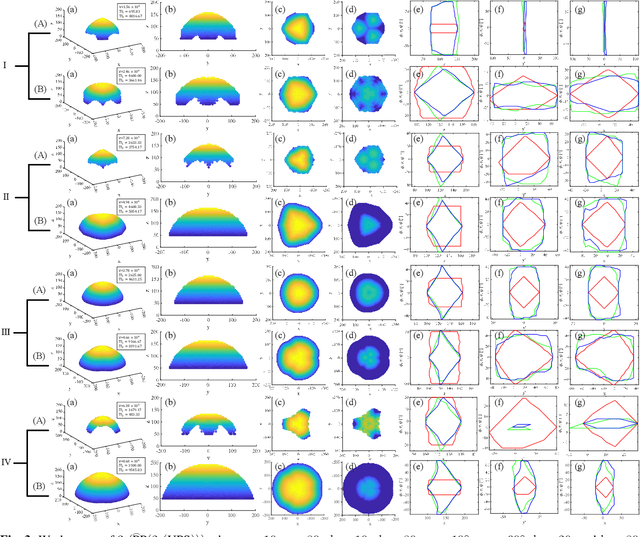
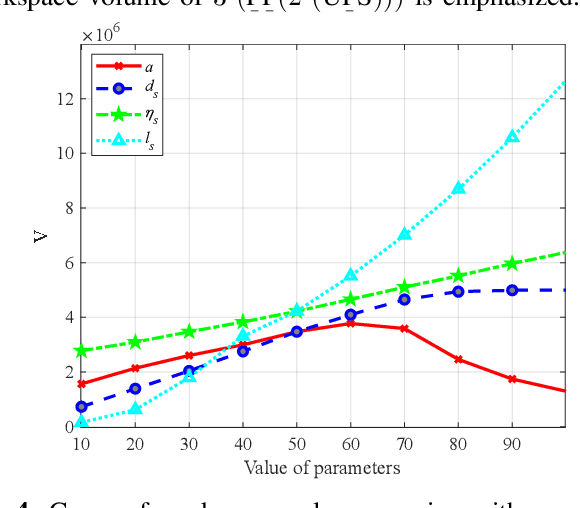
Redundant parallel robots are normally employed in scenarios requiring good precision, high load capability, and large workspace compared to traditional parallel mechanisms. However, the elementary robotic configuration and geometric parameter optimization are still quite challenging. This paper proposes a novel 3-(PP(2-(UPS))) redundant parallel mechanism, with good generalizability first, and further investigates the kinematic optimization issue by analyzing and investigating how its key geometric parameters influence the volume, shape, boundary completeness, and orientation capabilities of its workspace. The torsional capability index TI_1 and tilting capability index TI_2 are defined to evaluate the orientation performance of the mechanism. Numerical simulation studies are completed to indicate the analysis, providing reasonable but essential references for the parameter optimization of 3-(PP(2-(UPS))) and other similar redundant parallel mechanisms.
Design and Validation of an Under-actuated Robotic Finger with Synchronous Tendon Routing
Dec 11, 2025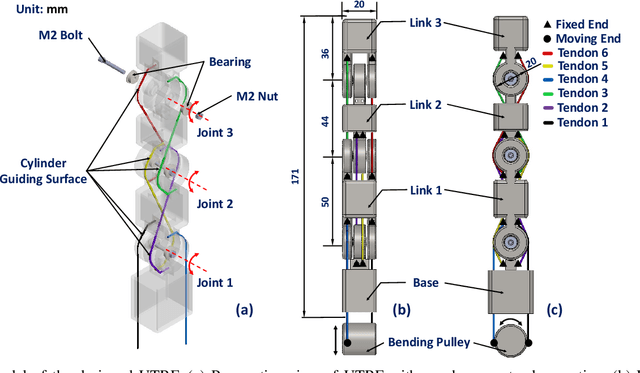
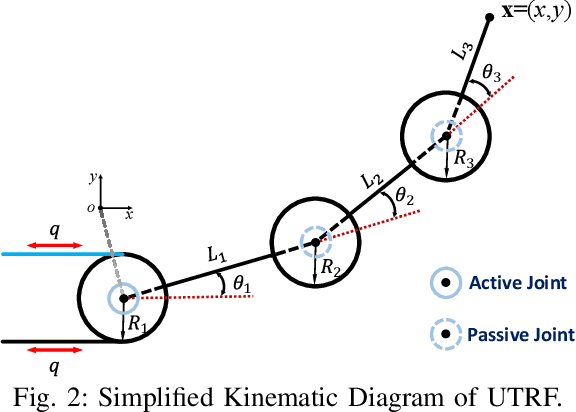
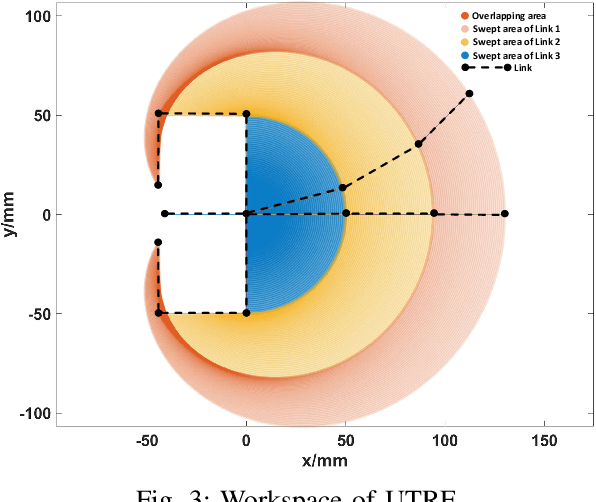
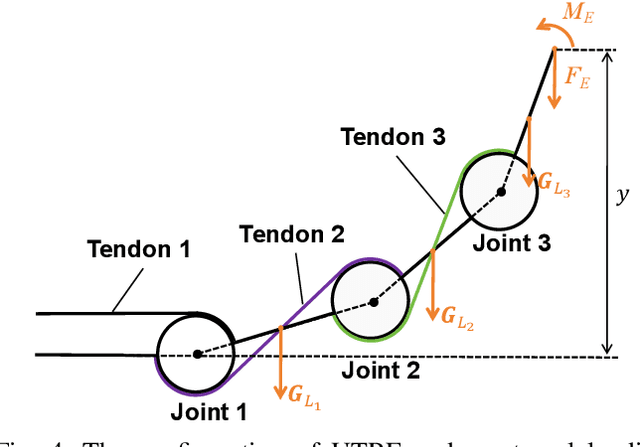
Tendon-driven under-actuated robotic fingers provide advantages for dexterous manipulation through reduced actuator requirements and simplified mechanical design. However, achieving both high load capacity and adaptive compliance in a compact form remains challenging. This paper presents an under-actuated tendon-driven robotic finger (UTRF) featuring a synchronous tendon routing that mechanically couples all joints with fixed angular velocity ratios, enabling the entire finger to be actuated by a single actuator. This approach significantly reduces the number of actuators required in multi-finger hands, resulting in a lighter and more compact structure without sacrificing stiffness or compliance. The kinematic and static models of the finger are derived, incorporating tendon elasticity to predict structural stiffness. A single-finger prototype was fabricated and tested under static loading, showing an average deflection prediction error of 1.0 mm (0.322% of total finger length) and a measured stiffness of 1.2x10^3 N/m under a 3 kg tip load. Integration into a five-finger robotic hand (UTRF-RoboHand) demonstrates effective object manipulation across diverse scenarios, confirming that the proposed routing achieves predictable stiffness and reliable grasping performance with a minimal actuator count.
NegoCollab: A Common Representation Negotiation Approach for Heterogeneous Collaborative Perception
Oct 31, 2025Collaborative perception improves task performance by expanding the perception range through information sharing among agents. . Immutable heterogeneity poses a significant challenge in collaborative perception, as participating agents may employ different and fixed perception models. This leads to domain gaps in the intermediate features shared among agents, consequently degrading collaborative performance. Aligning the features of all agents to a common representation can eliminate domain gaps with low training cost. However, in existing methods, the common representation is designated as the representation of a specific agent, making it difficult for agents with significant domain discrepancies from this specific agent to achieve proper alignment. This paper proposes NegoCollab, a heterogeneous collaboration method based on the negotiated common representation. It introduces a negotiator during training to derive the common representation from the local representations of each modality's agent, effectively reducing the inherent domain gap with the various local representations. In NegoCollab, the mutual transformation of features between the local representation space and the common representation space is achieved by a pair of sender and receiver. To better align local representations to the common representation containing multimodal information, we introduce structural alignment loss and pragmatic alignment loss in addition to the distribution alignment loss to supervise the training. This enables the knowledge in the common representation to be fully distilled into the sender.
Beyond BEV: Optimizing Point-Level Tokens for Collaborative Perception
Aug 27, 2025Collaborative perception allows agents to enhance their perceptual capabilities by exchanging intermediate features. Existing methods typically organize these intermediate features as 2D bird's-eye-view (BEV) representations, which discard critical fine-grained 3D structural cues essential for accurate object recognition and localization. To this end, we first introduce point-level tokens as intermediate representations for collaborative perception. However, point-cloud data are inherently unordered, massive, and position-sensitive, making it challenging to produce compact and aligned point-level token sequences that preserve detailed structural information. Therefore, we present CoPLOT, a novel Collaborative perception framework that utilizes Point-Level Optimized Tokens. It incorporates a point-native processing pipeline, including token reordering, sequence modeling, and multi-agent spatial alignment. A semantic-aware token reordering module generates adaptive 1D reorderings by leveraging scene-level and token-level semantic information. A frequency-enhanced state space model captures long-range sequence dependencies across both spatial and spectral domains, improving the differentiation between foreground tokens and background clutter. Lastly, a neighbor-to-ego alignment module applies a closed-loop process, combining global agent-level correction with local token-level refinement to mitigate localization noise. Extensive experiments on both simulated and real-world datasets show that CoPLOT outperforms state-of-the-art models, with even lower communication and computation overhead. Code will be available at https://github.com/CheeryLeeyy/CoPLOT.
Strongly Consistent Community Detection in Popularity Adjusted Block Models
Jun 08, 2025The Popularity Adjusted Block Model (PABM) provides a flexible framework for community detection in network data by allowing heterogeneous node popularity across communities. However, this flexibility increases model complexity and raises key unresolved challenges, particularly in effectively adapting spectral clustering techniques and efficiently achieving strong consistency in label recovery. To address these challenges, we first propose the Thresholded Cosine Spectral Clustering (TCSC) algorithm and establish its weak consistency under the PABM. We then introduce the one-step Refined TCSC algorithm and prove that it achieves strong consistency under the PABM, correctly recovering all community labels with high probability. We further show that the two-step Refined TCSC accelerates clustering error convergence, especially with small sample sizes. Additionally, we propose a data-driven approach for selecting the number of communities, which outperforms existing methods under the PABM. The effectiveness and robustness of our methods are validated through extensive simulations and real-world applications.
Probing In-Context Learning: Impact of Task Complexity and Model Architecture on Generalization and Efficiency
May 10, 2025We investigate in-context learning (ICL) through a meticulous experimental framework that systematically varies task complexity and model architecture. Extending beyond the linear regression baseline, we introduce Gaussian kernel regression and nonlinear dynamical system tasks, which emphasize temporal and recursive reasoning. We evaluate four distinct models: a GPT2-style Transformer, a Transformer with FlashAttention mechanism, a convolutional Hyena-based model, and the Mamba state-space model. Each model is trained from scratch on synthetic datasets and assessed for generalization during testing. Our findings highlight that model architecture significantly shapes ICL performance. The standard Transformer demonstrates robust performance across diverse tasks, while Mamba excels in temporally structured dynamics. Hyena effectively captures long-range dependencies but shows higher variance early in training, and FlashAttention offers computational efficiency but is more sensitive in low-data regimes. Further analysis uncovers locality-induced shortcuts in Gaussian kernel tasks, enhanced nonlinear separability through input range scaling, and the critical role of curriculum learning in mastering high-dimensional tasks.