 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Multimodal Models for Embodied Intelligent Driving: The Next Frontier in Self-Driving?
Jan 13, 2026The advent of Large Multimodal Models (LMMs) offers a promising technology to tackle the limitations of modular design in autonomous driving, which often falters in open-world scenarios requiring sustained environmental understanding and logical reasoning. Besides, embodied artificial intelligence facilitates policy optimization through closed-loop interactions to achieve the continuous learning capability, thereby advancing autonomous driving toward embodied intelligent (El) driving. However, such capability will be constrained by relying solely on LMMs to enhance EI driving without joint decision-making. This article introduces a novel semantics and policy dual-driven hybrid decision framework to tackle this challenge, ensuring continuous learning and joint decision. The framework merges LMMs for semantic understanding and cognitive representation, and deep reinforcement learning (DRL) for real-time policy optimization. We starts by introducing the foundational principles of EI driving and LMMs. Moreover, we examine the emerging opportunities this framework enables, encompassing potential benefits and representative use cases. A case study is conducted experimentally to validate the performance superiority of our framework in completing lane-change planning task. Finally, several future research directions to empower EI driving are identified to guide subsequent work.
One is Plenty: A Polymorphic Feature Interpreter for Immutable Heterogeneous Collaborative Perception
Nov 25, 2024Collaborative perception in autonomous driving significantly enhances the perception capabilities of individual agents. Immutable heterogeneity in collaborative perception, where agents have different and fixed perception networks, presents a major challenge due to the semantic gap in their exchanged intermediate features without modifying the perception networks. Most existing methods bridge the semantic gap through interpreters. However, they either require training a new interpreter for each new agent type, limiting extensibility, or rely on a two-stage interpretation via an intermediate standardized semantic space, causing cumulative semantic loss. To achieve both extensibility in immutable heterogeneous scenarios and low-loss feature interpretation, we propose PolyInter, a polymorphic feature interpreter. It contains an extension point through which emerging new agents can seamlessly integrate by overriding only their specific prompts, which are learnable parameters intended to guide the interpretation, while reusing PolyInter's remaining parameters. By leveraging polymorphism, our design ensures that a single interpreter is sufficient to accommodate diverse agents and interpret their features into the ego agent's semantic space. Experiments conducted on the OPV2V dataset demonstrate that PolyInter improves collaborative perception precision by up to 11.1% compared to SOTA interpreters, while comparable results can be achieved by training only 1.4% of PolyInter's parameters when adapting to new agents.
Control Industrial Automation System with Large Language Models
Sep 26, 2024



Traditional industrial automation systems require specialized expertise to operate and complex reprogramming to adapt to new processes. Large language models offer the intelligence to make them more flexible and easier to use. However, LLMs' application in industrial settings is underexplored. This paper introduces a framework for integrating LLMs to achieve end-to-end control of industrial automation systems. At the core of the framework are an agent system designed for industrial tasks, a structured prompting method, and an event-driven information modeling mechanism that provides real-time data for LLM inference. The framework supplies LLMs with real-time events on different context semantic levels, allowing them to interpret the information, generate production plans, and control operations on the automation system. It also supports structured dataset creation for fine-tuning on this downstream application of LLMs. Our contribution includes a formal system design, proof-of-concept implementation, and a method for generating task-specific datasets for LLM fine-tuning and testing. This approach enables a more adaptive automation system that can respond to spontaneous events, while allowing easier operation and configuration through natural language for more intuitive human-machine interaction. We provide demo videos and detailed data on GitHub: https://github.com/YuchenXia/LLM4IAS
Understanding the Performance and Estimating the Cost of LLM Fine-Tuning
Aug 08, 2024



Due to the cost-prohibitive nature of training Large Language Models (LLMs), fine-tuning has emerged as an attractive alternative for specializing LLMs for specific tasks using limited compute resources in a cost-effective manner. In this paper, we characterize sparse Mixture of Experts (MoE) based LLM fine-tuning to understand their accuracy and runtime performance on a single GPU. Our evaluation provides unique insights into the training efficacy of sparse and dense versions of MoE models, as well as their runtime characteristics, including maximum batch size, execution time breakdown, end-to-end throughput, GPU hardware utilization, and load distribution. Our study identifies the optimization of the MoE layer as crucial for further improving the performance of LLM fine-tuning. Using our profiling results, we also develop and validate an analytical model to estimate the cost of LLM fine-tuning on the cloud. This model, based on parameters of the model and GPU architecture, estimates LLM throughput and the cost of training, aiding practitioners in industry and academia to budget the cost of fine-tuning a specific model.
Incorporating Large Language Models into Production Systems for Enhanced Task Automation and Flexibility
Jul 11, 2024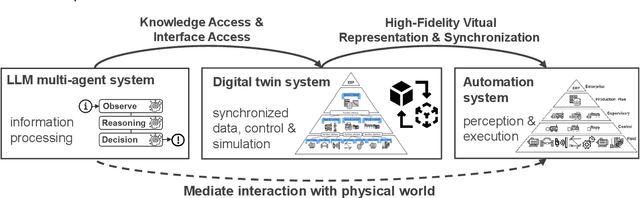
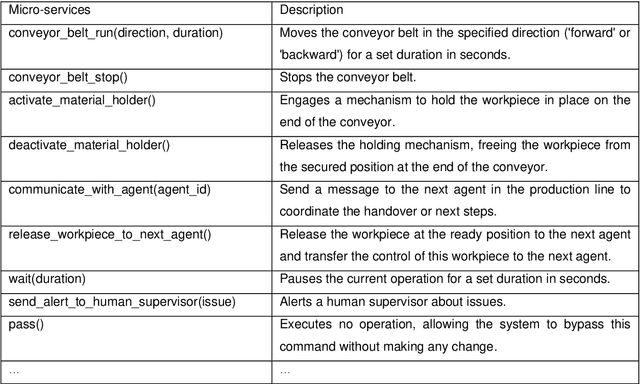
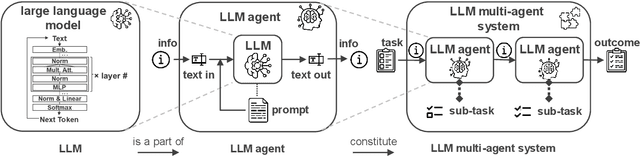
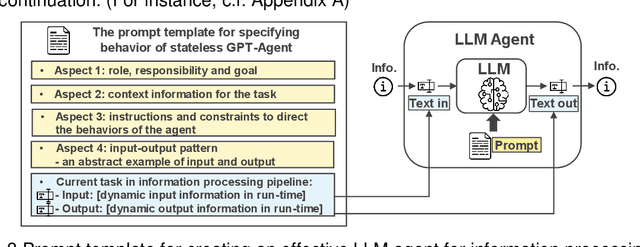
This paper introduces a novel approach to integrating large language model (LLM) agents into automated production systems, aimed at enhancing task automation and flexibility. We organize production operations within a hierarchical framework based on the automation pyramid. Atomic operation functionalities are modeled as microservices, which are executed through interface invocation within a dedicated digital twin system. This allows for a scalable and flexible foundation for orchestrating production processes. In this digital twin system, low-level, hardware-specific data is semantically enriched and made interpretable for LLMs for production planning and control tasks. Large language model agents are systematically prompted to interpret these production-specific data and knowledge. Upon receiving a user request or identifying a triggering event, the LLM agents generate a process plan. This plan is then decomposed into a series of atomic operations, executed as microservices within the real-world automation system. We implement this overall approach on an automated modular production facility at our laboratory, demonstrating how the LLMs can handle production planning and control tasks through a concrete case study. This results in an intuitive production facility with higher levels of task automation and flexibility. Finally, we reveal the several limitations in realizing the full potential of the large language models in autonomous systems and point out promising benefits. Demos of this series of ongoing research series can be accessed at: https://github.com/YuchenXia/GPT4IndustrialAutomation
LLM experiments with simulation: Large Language Model Multi-Agent System for Process Simulation Parametrization in Digital Twins
May 28, 2024This paper presents a novel design of a multi-agent system framework that applies a large language model (LLM) to automate the parametrization of process simulations in digital twins. We propose a multi-agent framework that includes four types of agents: observation, reasoning, decision and summarization. By enabling dynamic interaction between LLM agents and simulation model, the developed system can automatically explore the parametrization of the simulation and use heuristic reasoning to determine a set of parameters to control the simulation to achieve an objective. The proposed approach enhances the simulation model by infusing it with heuristics from LLM and enables autonomous search for feasible parametrization to solve a user task. Furthermore, the system has the potential to increase user-friendliness and reduce the cognitive load on human users by assisting in complex decision-making processes. The effectiveness and functionality of the system are demonstrated through a case study, and the visualized demos are available at a GitHub Repository: https://github.com/YuchenXia/LLMDrivenSimulation
Generation of Asset Administration Shell with Large Language Model Agents: Interoperability in Digital Twins with Semantic Node
Mar 25, 2024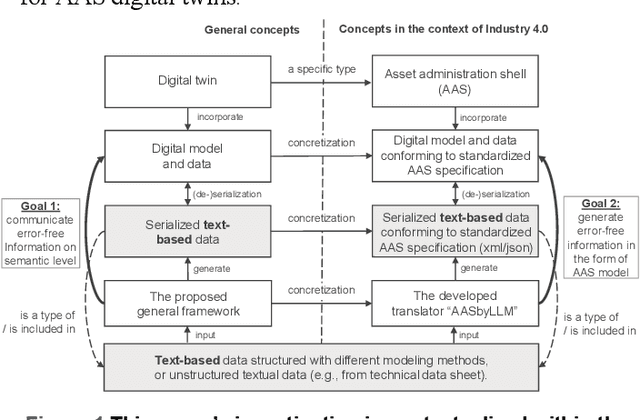
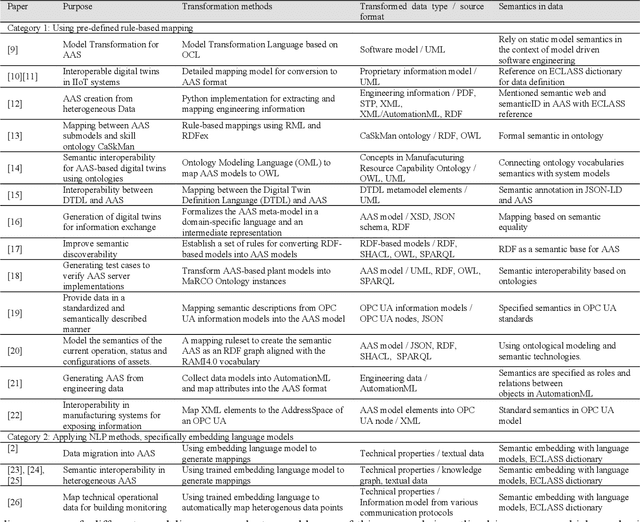
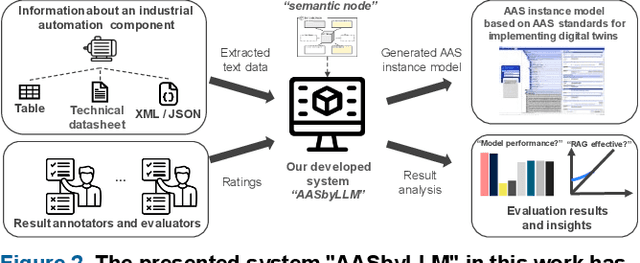
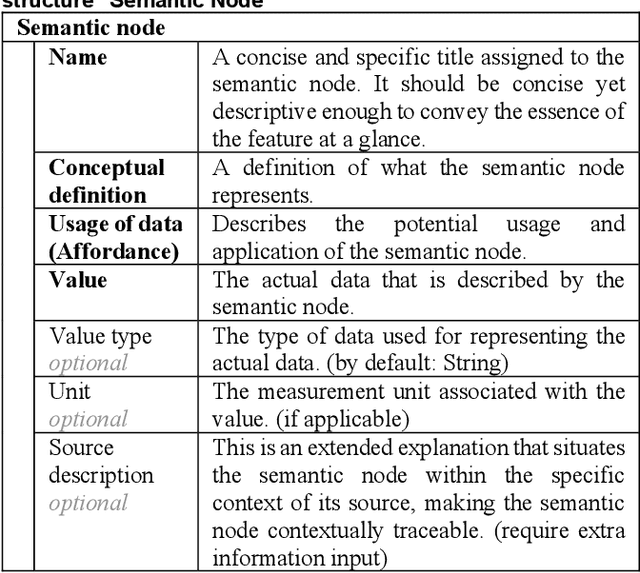
This research introduces a novel approach for assisting the creation of Asset Administration Shell (AAS) instances for digital twin modeling within the context of Industry 4.0, aiming to enhance interoperability in smart manufacturing and reduce manual effort. We construct a "semantic node" data structure to capture the semantic essence of textual data. Then, a system powered by large language models is designed and implemented to process "semantic node" and generate AAS instance models from textual technical data. Our evaluation demonstrates a 62-79% effective generation rate, indicating a substantial proportion of manual creation effort can be converted into easier validation effort, thereby reducing the time and cost in creating AAS instance models. In our evaluation, a comparative analysis of different LLMs and an in-depth ablation study of Retrieval-Augmented Generation (RAG) mechanisms provide insights into the effectiveness of LLM systems for interpreting technical concepts. Our findings emphasize LLMs' capability in automating AAS instance creation, enhancing semantic interoperability, and contributing to the broader field of semantic interoperability for digital twins in industrial applications. The prototype implementation and evaluation results are released on our GitHub Repository with the link: https://github.com/YuchenXia/AASbyLLM
Towards autonomous system: flexible modular production system enhanced with large language model agents
May 02, 2023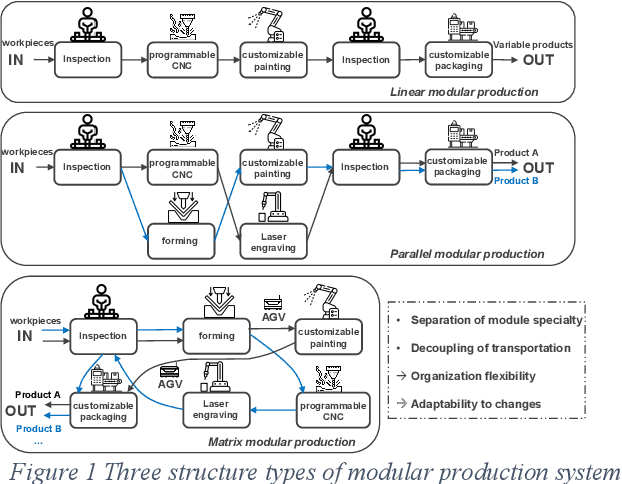
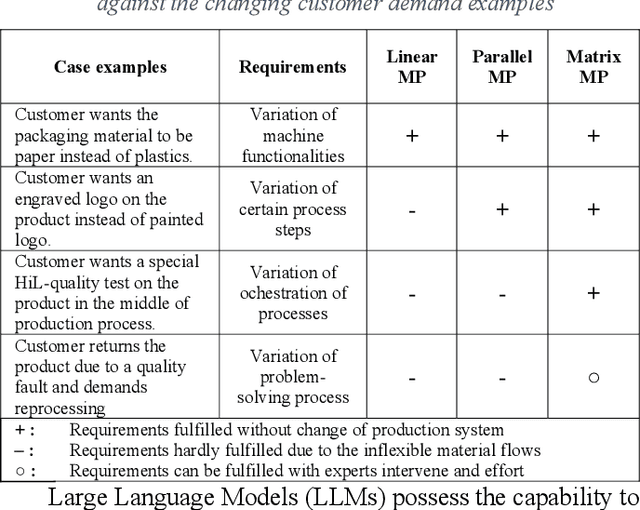
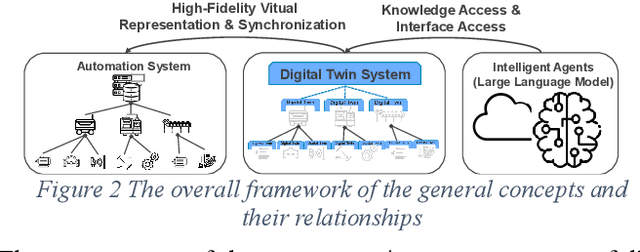
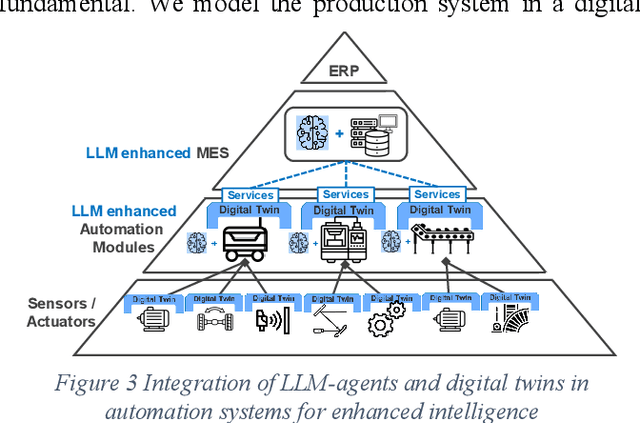
In this paper, we present a novel framework that combines large language models (LLMs), digital twins and industrial automation system to enable intelligent planning and control of production processes. We retrofit the automation system for a modular production facility and create executable control interfaces of fine-granular functionalities and coarse-granular skills. Low-level functionalities are executed by automation components, and high-level skills are performed by automation modules. Subsequently, a digital twin system is developed, registering these interfaces and containing additional descriptive information about the production system. Based on the retrofitted automation system and the created digital twins, LLM-agents are designed to interpret descriptive information in the digital twins and control the physical system through service interfaces. These LLM-agents serve as intelligent agents on different levels within an automation system, enabling autonomous planning and control of flexible production. Given a task instruction as input, the LLM-agents orchestrate a sequence of atomic functionalities and skills to accomplish the task. We demonstrate how our implemented prototype can handle un-predefined tasks, plan a production process, and execute the operations. This research highlights the potential of integrating LLMs into industrial automation systems in the context of smart factory for more agile, flexible, and adaptive production processes, while it also underscores the critical insights and limitations for future work.