 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIMEST: Temporal Information Motif Estimator Using Sampling Trees
Jul 27, 2025The mining of pattern subgraphs, known as motifs, is a core task in the field of graph mining. Edges in real-world networks often have timestamps, so there is a need for temporal motif mining. A temporal motif is a richer structure that imposes timing constraints on the edges of the motif. Temporal motifs have been used to analyze social networks, financial transactions, and biological networks. Motif counting in temporal graphs is particularly challenging. A graph with millions of edges can have trillions of temporal motifs, since the same edge can occur with multiple timestamps. There is a combinatorial explosion of possibilities, and state-of-the-art algorithms cannot manage motifs with more than four vertices. In this work, we present TIMEST: a general, fast, and accurate estimation algorithm to count temporal motifs of arbitrary sizes in temporal networks. Our approach introduces a temporal spanning tree sampler that leverages weighted sampling to generate substructures of target temporal motifs. This method carefully takes a subset of temporal constraints of the motif that can be jointly and efficiently sampled. TIMEST uses randomized estimation techniques to obtain accurate estimates of motif counts. We give theoretical guarantees on the running time and approximation guarantees of TIMEST. We perform an extensive experimental evaluation and show that TIMEST is both faster and more accurate than previous algorithms. Our CPU implementation exhibits an average speedup of 28x over state-of-the-art GPU implementation of the exact algorithm, and 6x speedup over SOTA approximate algorithms while consistently showcasing less than 5% error in most cases. For example, TIMEST can count the number of instances of a financial fraud temporal motif in four minutes with 0.6% error, while exact methods take more than two days.
Triadic First-Order Logic Queries in Temporal Networks
Jul 23, 2025Motif counting is a fundamental problem in network analysis, and there is a rich literature of theoretical and applied algorithms for this problem. Given a large input network $G$, a motif $H$ is a small "pattern" graph indicative of special local structure. Motif/pattern mining involves finding all matches of this pattern in the input $G$. The simplest, yet challenging, case of motif counting is when $H$ has three vertices, often called a "triadic" query. Recent work has focused on "temporal graph mining", where the network $G$ has edges with timestamps (and directions) and $H$ has time constraints. Inspired by concepts in logic and database theory, we introduce the study of "thresholded First Order Logic (FOL) Motif Analysis" for massive temporal networks. A typical triadic motif query asks for the existence of three vertices that form a desired temporal pattern. An "FOL" motif query is obtained by having both existential and thresholded universal quantifiers. This allows for query semantics that can mine richer information from networks. A typical triadic query would be "find all triples of vertices $u,v,w$ such that they form a triangle within one hour". A thresholded FOL query can express "find all pairs $u,v$ such that for half of $w$ where $(u,w)$ formed an edge, $(v,w)$ also formed an edge within an hour". We design the first algorithm, FOLTY, for mining thresholded FOL triadic queries. The theoretical running time of FOLTY matches the best known running time for temporal triangle counting in sparse graphs. We give an efficient implementation of FOLTY using specialized temporal data structures. FOLTY has excellent empirical behavior, and can answer triadic FOL queries on graphs with nearly 70M edges is less than hour on commodity hardware. Our work has the potential to start a new research direction in the classic well-studied problem of motif analysis.
MoE-Lens: Towards the Hardware Limit of High-Throughput MoE LLM Serving Under Resource Constraints
Apr 12, 2025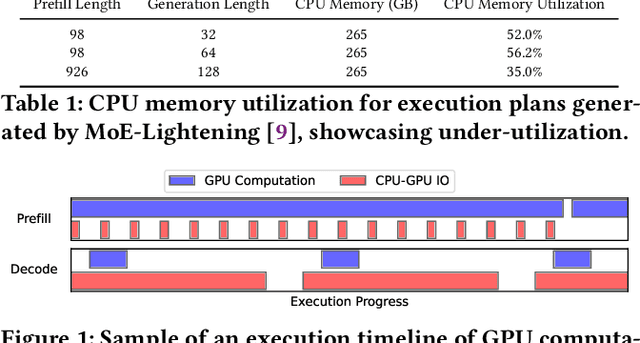

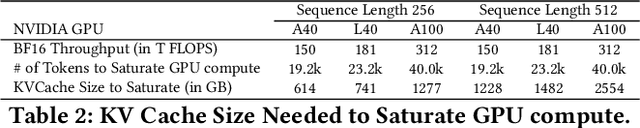
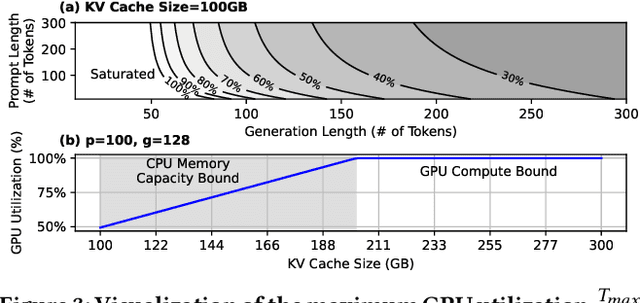
Mixture of Experts (MoE) LLMs, characterized by their sparse activation patterns, offer a promising approach to scaling language models while avoiding proportionally increasing the inference cost. However, their large parameter sizes present deployment challenges in resource-constrained environments with limited GPU memory capacity, as GPU memory is often insufficient to accommodate the full set of model weights. Consequently, typical deployments rely on CPU-GPU hybrid execution: the GPU handles compute-intensive GEMM operations, while the CPU processes the relatively lightweight attention mechanism. This setup introduces a key challenge: how to effectively optimize resource utilization across CPU and GPU? Prior work has designed system optimizations based on performance models with limited scope. Specifically, such models do not capture the complex interactions between hardware properties and system execution mechanisms. Therefore, previous approaches neither identify nor achieve the hardware limit. This paper presents MoE-Lens, a high-throughput MoE LLM inference system designed through holistic performance modeling for resource-constrained environments. Our performance model thoroughly analyzes various fundamental system components, including CPU memory capacity, GPU compute power, and workload characteristics, to understand the theoretical performance upper bound of MoE inference. Furthermore, it captures the system execution mechanisms to identify the key hardware bottlenecks and accurately predict the achievable throughput. Informed by our performance model, MoE-Lens introduces an inference system approaching hardware limits. Evaluated on diverse MoE models and datasets, MoE-Lens outperforms the state-of-the-art solution by 4.6x on average (up to 25.5x), with our theoretical model predicting performance with an average 94% accuracy.
Accurate and Fast Estimation of Temporal Motifs using Path Sampling
Sep 13, 2024



Counting the number of small subgraphs, called motifs, is a fundamental problem in social network analysis and graph mining. Many real-world networks are directed and temporal, where edges have timestamps. Motif counting in directed, temporal graphs is especially challenging because there are a plethora of different kinds of patterns. Temporal motif counts reveal much richer information and there is a need for scalable algorithms for motif counting. A major challenge in counting is that there can be trillions of temporal motif matches even with a graph with only millions of vertices. Both the motifs and the input graphs can have multiple edges between two vertices, leading to a combinatorial explosion problem. Counting temporal motifs involving just four vertices is not feasible with current state-of-the-art algorithms. We design an algorithm, TEACUPS, that addresses this problem using a novel technique of temporal path sampling. We combine a path sampling method with carefully designed temporal data structures, to propose an efficient approximate algorithm for temporal motif counting. TEACUPS is an unbiased estimator with provable concentration behavior, which can be used to bound the estimation error. For a Bitcoin graph with hundreds of millions of edges, TEACUPS runs in less than 1 minute, while the exact counting algorithm takes more than a day. We empirically demonstrate the accuracy of TEACUPS on large datasets, showing an average of 30$\times$ speedup (up to 2000$\times$ speedup) compared to existing GPU-based exact counting methods while preserving high count estimation accuracy.
Understanding the Performance and Estimating the Cost of LLM Fine-Tuning
Aug 08, 2024



Due to the cost-prohibitive nature of training Large Language Models (LLMs), fine-tuning has emerged as an attractive alternative for specializing LLMs for specific tasks using limited compute resources in a cost-effective manner. In this paper, we characterize sparse Mixture of Experts (MoE) based LLM fine-tuning to understand their accuracy and runtime performance on a single GPU. Our evaluation provides unique insights into the training efficacy of sparse and dense versions of MoE models, as well as their runtime characteristics, including maximum batch size, execution time breakdown, end-to-end throughput, GPU hardware utilization, and load distribution. Our study identifies the optimization of the MoE layer as crucial for further improving the performance of LLM fine-tuning. Using our profiling results, we also develop and validate an analytical model to estimate the cost of LLM fine-tuning on the cloud. This model, based on parameters of the model and GPU architecture, estimates LLM throughput and the cost of training, aiding practitioners in industry and academia to budget the cost of fine-tuning a specific model.