 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIMEST: Temporal Information Motif Estimator Using Sampling Trees
Jul 27, 2025The mining of pattern subgraphs, known as motifs, is a core task in the field of graph mining. Edges in real-world networks often have timestamps, so there is a need for temporal motif mining. A temporal motif is a richer structure that imposes timing constraints on the edges of the motif. Temporal motifs have been used to analyze social networks, financial transactions, and biological networks. Motif counting in temporal graphs is particularly challenging. A graph with millions of edges can have trillions of temporal motifs, since the same edge can occur with multiple timestamps. There is a combinatorial explosion of possibilities, and state-of-the-art algorithms cannot manage motifs with more than four vertices. In this work, we present TIMEST: a general, fast, and accurate estimation algorithm to count temporal motifs of arbitrary sizes in temporal networks. Our approach introduces a temporal spanning tree sampler that leverages weighted sampling to generate substructures of target temporal motifs. This method carefully takes a subset of temporal constraints of the motif that can be jointly and efficiently sampled. TIMEST uses randomized estimation techniques to obtain accurate estimates of motif counts. We give theoretical guarantees on the running time and approximation guarantees of TIMEST. We perform an extensive experimental evaluation and show that TIMEST is both faster and more accurate than previous algorithms. Our CPU implementation exhibits an average speedup of 28x over state-of-the-art GPU implementation of the exact algorithm, and 6x speedup over SOTA approximate algorithms while consistently showcasing less than 5% error in most cases. For example, TIMEST can count the number of instances of a financial fraud temporal motif in four minutes with 0.6% error, while exact methods take more than two days.
Triadic First-Order Logic Queries in Temporal Networks
Jul 23, 2025Motif counting is a fundamental problem in network analysis, and there is a rich literature of theoretical and applied algorithms for this problem. Given a large input network $G$, a motif $H$ is a small "pattern" graph indicative of special local structure. Motif/pattern mining involves finding all matches of this pattern in the input $G$. The simplest, yet challenging, case of motif counting is when $H$ has three vertices, often called a "triadic" query. Recent work has focused on "temporal graph mining", where the network $G$ has edges with timestamps (and directions) and $H$ has time constraints. Inspired by concepts in logic and database theory, we introduce the study of "thresholded First Order Logic (FOL) Motif Analysis" for massive temporal networks. A typical triadic motif query asks for the existence of three vertices that form a desired temporal pattern. An "FOL" motif query is obtained by having both existential and thresholded universal quantifiers. This allows for query semantics that can mine richer information from networks. A typical triadic query would be "find all triples of vertices $u,v,w$ such that they form a triangle within one hour". A thresholded FOL query can express "find all pairs $u,v$ such that for half of $w$ where $(u,w)$ formed an edge, $(v,w)$ also formed an edge within an hour". We design the first algorithm, FOLTY, for mining thresholded FOL triadic queries. The theoretical running time of FOLTY matches the best known running time for temporal triangle counting in sparse graphs. We give an efficient implementation of FOLTY using specialized temporal data structures. FOLTY has excellent empirical behavior, and can answer triadic FOL queries on graphs with nearly 70M edges is less than hour on commodity hardware. Our work has the potential to start a new research direction in the classic well-studied problem of motif analysis.
Accurate and Fast Estimation of Temporal Motifs using Path Sampling
Sep 13, 2024



Counting the number of small subgraphs, called motifs, is a fundamental problem in social network analysis and graph mining. Many real-world networks are directed and temporal, where edges have timestamps. Motif counting in directed, temporal graphs is especially challenging because there are a plethora of different kinds of patterns. Temporal motif counts reveal much richer information and there is a need for scalable algorithms for motif counting. A major challenge in counting is that there can be trillions of temporal motif matches even with a graph with only millions of vertices. Both the motifs and the input graphs can have multiple edges between two vertices, leading to a combinatorial explosion problem. Counting temporal motifs involving just four vertices is not feasible with current state-of-the-art algorithms. We design an algorithm, TEACUPS, that addresses this problem using a novel technique of temporal path sampling. We combine a path sampling method with carefully designed temporal data structures, to propose an efficient approximate algorithm for temporal motif counting. TEACUPS is an unbiased estimator with provable concentration behavior, which can be used to bound the estimation error. For a Bitcoin graph with hundreds of millions of edges, TEACUPS runs in less than 1 minute, while the exact counting algorithm takes more than a day. We empirically demonstrate the accuracy of TEACUPS on large datasets, showing an average of 30$\times$ speedup (up to 2000$\times$ speedup) compared to existing GPU-based exact counting methods while preserving high count estimation accuracy.
Large Scale Learning on Non-Homophilous Graphs: New Benchmarks and Strong Simple Methods
Oct 27, 2021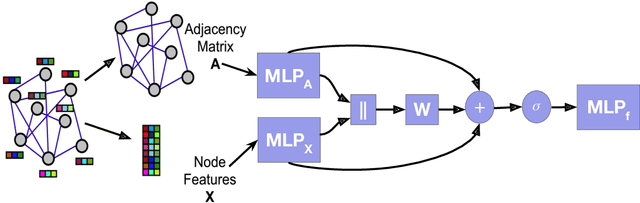
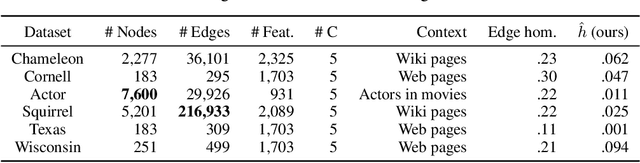
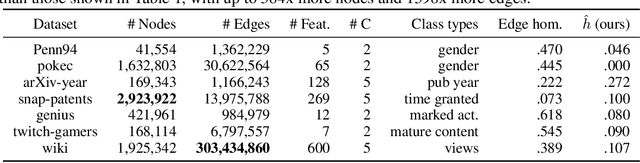
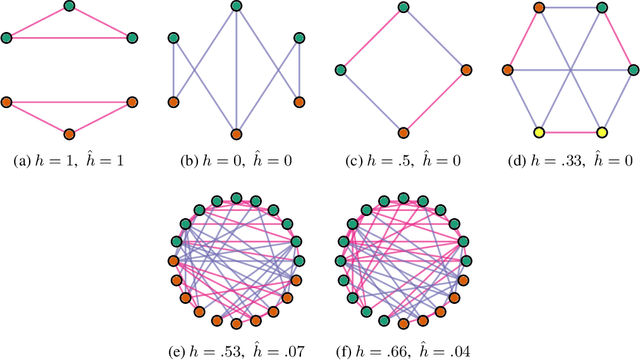
Many widely used datasets for graph machine learning tasks have generally been homophilous, where nodes with similar labels connect to each other. Recently, new Graph Neural Networks (GNNs) have been developed that move beyond the homophily regime; however, their evaluation has often been conducted on small graphs with limited application domains. We collect and introduce diverse non-homophilous datasets from a variety of application areas that have up to 384x more nodes and 1398x more edges than prior datasets. We further show that existing scalable graph learning and graph minibatching techniques lead to performance degradation on these non-homophilous datasets, thus highlighting the need for further work on scalable non-homophilous methods. To address these concerns, we introduce LINKX -- a strong simple method that admits straightforward minibatch training and inference. Extensive experimental results with representative simple methods and GNNs across our proposed datasets show that LINKX achieves state-of-the-art performance for learning on non-homophilous graphs. Our codes and data are available at https://github.com/CUAI/Non-Homophily-Large-Scale.
Edge Proposal Sets for Link Prediction
Jun 30, 2021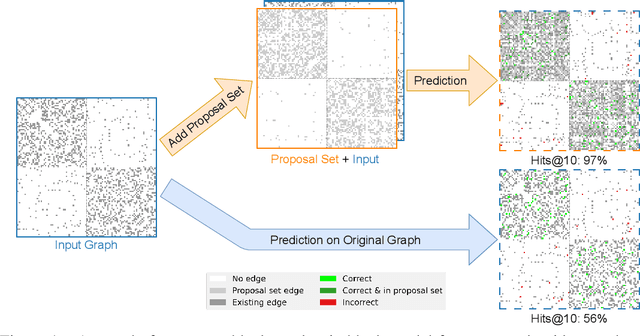
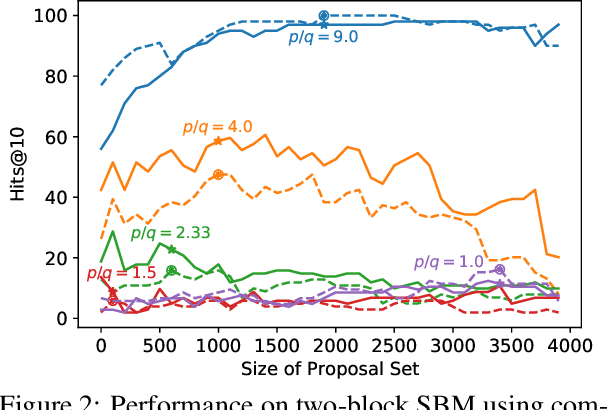
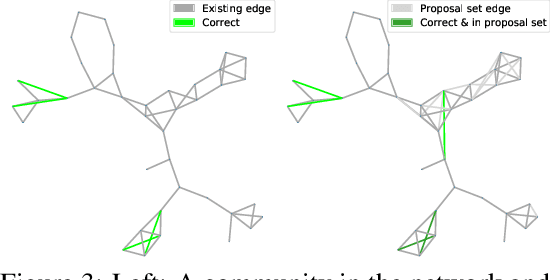
Graphs are a common model for complex relational data such as social networks and protein interactions, and such data can evolve over time (e.g., new friendships) and be noisy (e.g., unmeasured interactions). Link prediction aims to predict future edges or infer missing edges in the graph, and has diverse applications in recommender systems, experimental design, and complex systems. Even though link prediction algorithms strongly depend on the set of edges in the graph, existing approaches typically do not modify the graph topology to improve performance. Here, we demonstrate how simply adding a set of edges, which we call a \emph{proposal set}, to the graph as a pre-processing step can improve the performance of several link prediction algorithms. The underlying idea is that if the edges in the proposal set generally align with the structure of the graph, link prediction algorithms are further guided towards predicting the right edges; in other words, adding a proposal set of edges is a signal-boosting pre-processing step. We show how to use existing link prediction algorithms to generate effective proposal sets and evaluate this approach on various synthetic and empirical datasets. We find that proposal sets meaningfully improve the accuracy of link prediction algorithms based on both neighborhood heuristics and graph neural networks. Code is available at \url{https://github.com/CUAI/Edge-Proposal-Sets}.
DEAP Cache: Deep Eviction Admission and Prefetching for Cache
Sep 19, 2020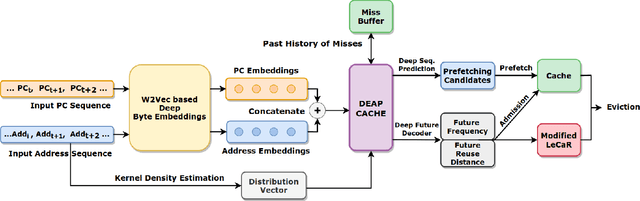
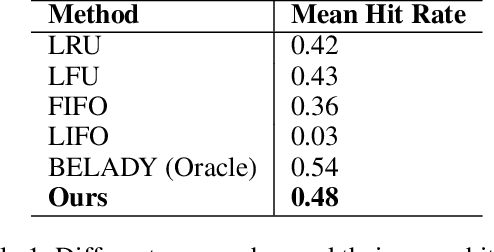
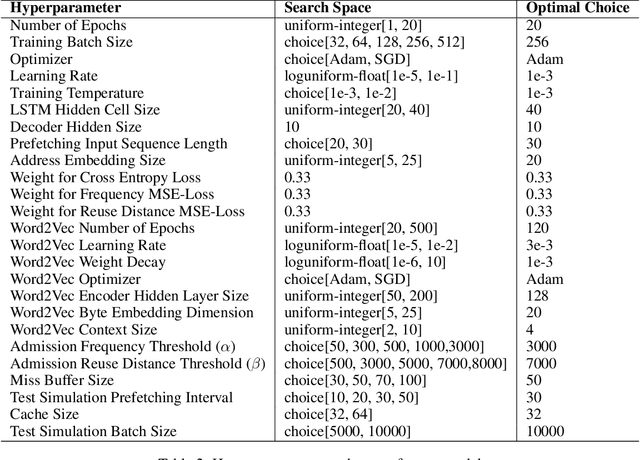
Recent approaches for learning policies to improve caching, target just one out of the prefetching, admission and eviction processes. In contrast, we propose an end to end pipeline to learn all three policies using machine learning. We also take inspiration from the success of pretraining on large corpora to learn specialized embeddings for the task. We model prefetching as a sequence prediction task based on past misses. Following previous works suggesting that frequency and recency are the two orthogonal fundamental attributes for caching, we use an online reinforcement learning technique to learn the optimal policy distribution between two orthogonal eviction strategies based on them. While previous approaches used the past as an indicator of the future, we instead explicitly model the future frequency and recency in a multi-task fashion with prefetching, leveraging the abilities of deep networks to capture futuristic trends and use them for learning eviction and admission. We also model the distribution of the data in an online fashion using Kernel Density Estimation in our approach, to deal with the problem of caching non-stationary data. We present our approach as a "proof of concept" of learning all three components of cache strategies using machine learning and leave improving practical deployment for future work.