 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEAP Cache: Deep Eviction Admission and Prefetching for Cache
Sep 19, 2020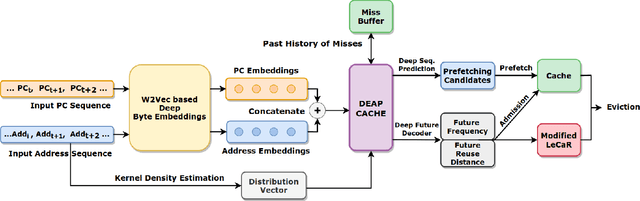
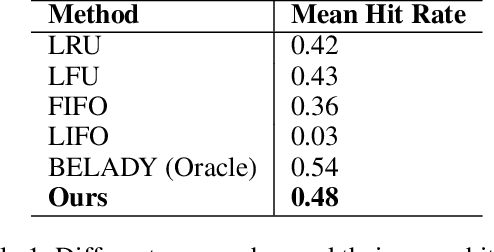
Recent approaches for learning policies to improve caching, target just one out of the prefetching, admission and eviction processes. In contrast, we propose an end to end pipeline to learn all three policies using machine learning. We also take inspiration from the success of pretraining on large corpora to learn specialized embeddings for the task. We model prefetching as a sequence prediction task based on past misses. Following previous works suggesting that frequency and recency are the two orthogonal fundamental attributes for caching, we use an online reinforcement learning technique to learn the optimal policy distribution between two orthogonal eviction strategies based on them. While previous approaches used the past as an indicator of the future, we instead explicitly model the future frequency and recency in a multi-task fashion with prefetching, leveraging the abilities of deep networks to capture futuristic trends and use them for learning eviction and admission. We also model the distribution of the data in an online fashion using Kernel Density Estimation in our approach, to deal with the problem of caching non-stationary data. We present our approach as a "proof of concept" of learning all three components of cache strategies using machine learning and leave improving practical deployment for future work.
VacSIM: Learning Effective Strategies for COVID-19 Vaccine Distribution using Reinforcement Learning
Sep 14, 2020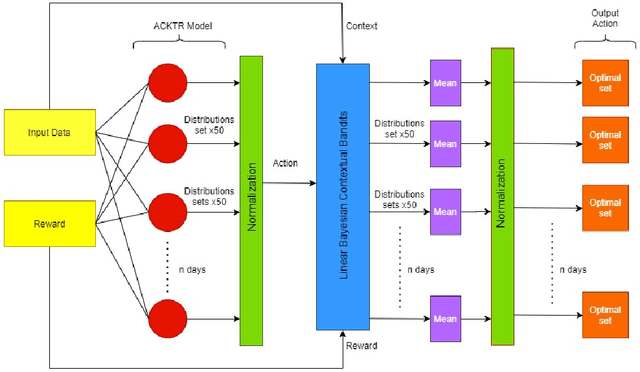

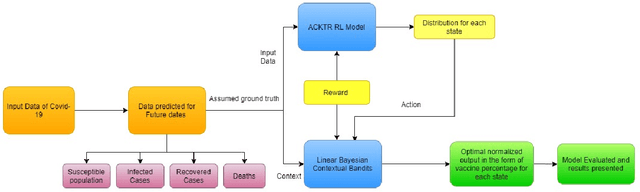
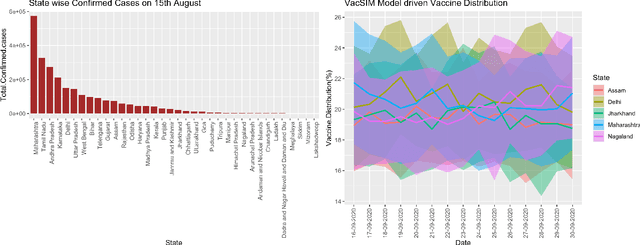
A COVID-19 vaccine is our best bet for mitigating the ongoing onslaught of the pandemic. However, vaccine is also expected to be a limited resource. An optimal allocation strategy, especially in countries with access inequities and a temporal separation of hot-spots might be an effective way of halting the disease spread. We approach this problem by proposing a novel pipeline VacSIM that dovetails Actor-Critic using Kronecker-Factored Trust Region (ACKTR) model into a Contextual Bandits approach for optimizing the distribution of COVID-19 vaccine. Whereas the ACKTR model suggests better actions and rewards, Contextual Bandits allow online modifications that may need to be implemented on a day-to-day basis in the real world scenario. We evaluate this framework against a naive allocation approach of distributing vaccine proportional to the incidence of COVID-19 cases in five different States across India and demonstrate up to 100,000 additional lives potentially saved and a five-fold increase in the efficacy of limiting the spread over a period of 30 days through the VacSIM approach. We also propose novel evaluation strategies including a standard compartmental model based projections and a causality preserving evaluation of our model. Finally, we contribute a new Open-AI environment meant for the vaccine distribution scenario, and open-source VacSIM for wide testing and applications across the globe.