 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGive me a hint: Can LLMs take a hint to solve math problems?
Oct 08, 2024



While many state-of-the-art LLMs have shown poor logical and basic mathematical reasoning, recent works try to improve their problem-solving abilities using prompting techniques. We propose giving "hints" to improve the language model's performance on advanced mathematical problems, taking inspiration from how humans approach math pedagogically. We also test the model's adversarial robustness to wrong hints. We demonstrate the effectiveness of our approach by evaluating various LLMs, presenting them with a diverse set of problems of different difficulties and topics from the MATH dataset and comparing against techniques such as one-shot, few-shot, and chain of thought prompting.
Track, Check, Repeat: An EM Approach to Unsupervised Tracking
Apr 07, 2021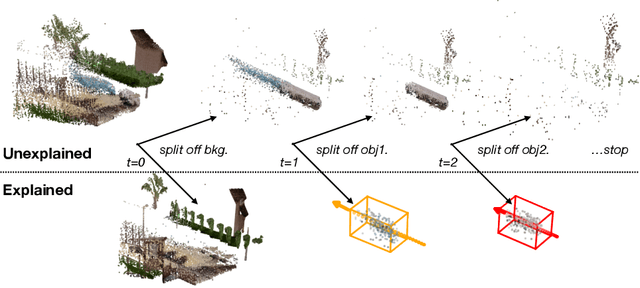
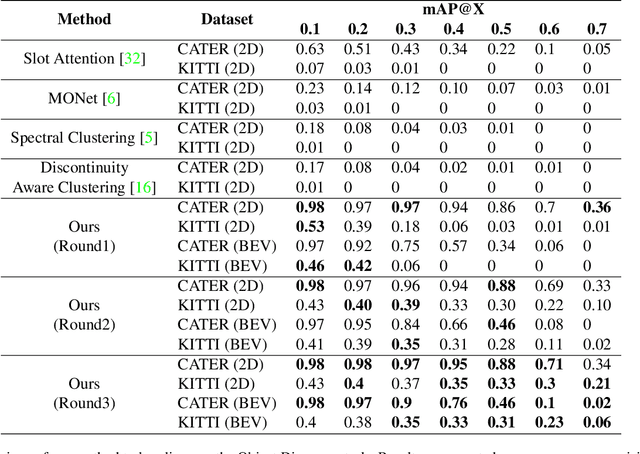


We propose an unsupervised method for detecting and tracking moving objects in 3D, in unlabelled RGB-D videos. The method begins with classic handcrafted techniques for segmenting objects using motion cues: we estimate optical flow and camera motion, and conservatively segment regions that appear to be moving independently of the background. Treating these initial segments as pseudo-labels, we learn an ensemble of appearance-based 2D and 3D detectors, under heavy data augmentation. We use this ensemble to detect new instances of the "moving" type, even if they are not moving, and add these as new pseudo-labels. Our method is an expectation-maximization algorithm, where in the expectation step we fire all modules and look for agreement among them, and in the maximization step we re-train the modules to improve this agreement. The constraint of ensemble agreement helps combat contamination of the generated pseudo-labels (during the E step), and data augmentation helps the modules generalize to yet-unlabelled data (during the M step). We compare against existing unsupervised object discovery and tracking methods, using challenging videos from CATER and KITTI, and show strong improvements over the state-of-the-art.
DEAP Cache: Deep Eviction Admission and Prefetching for Cache
Sep 19, 2020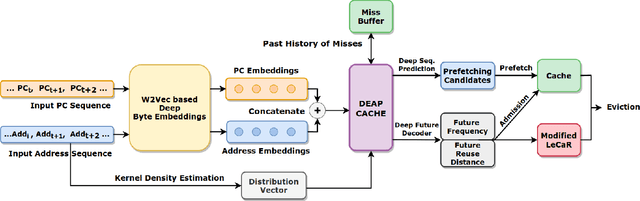
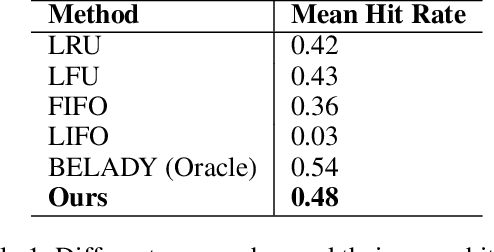
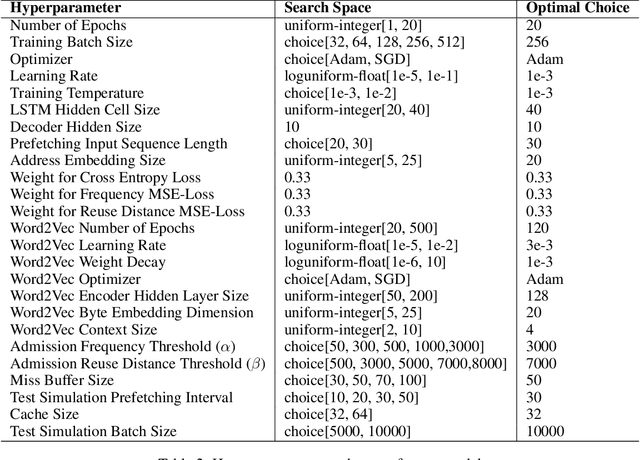
Recent approaches for learning policies to improve caching, target just one out of the prefetching, admission and eviction processes. In contrast, we propose an end to end pipeline to learn all three policies using machine learning. We also take inspiration from the success of pretraining on large corpora to learn specialized embeddings for the task. We model prefetching as a sequence prediction task based on past misses. Following previous works suggesting that frequency and recency are the two orthogonal fundamental attributes for caching, we use an online reinforcement learning technique to learn the optimal policy distribution between two orthogonal eviction strategies based on them. While previous approaches used the past as an indicator of the future, we instead explicitly model the future frequency and recency in a multi-task fashion with prefetching, leveraging the abilities of deep networks to capture futuristic trends and use them for learning eviction and admission. We also model the distribution of the data in an online fashion using Kernel Density Estimation in our approach, to deal with the problem of caching non-stationary data. We present our approach as a "proof of concept" of learning all three components of cache strategies using machine learning and leave improving practical deployment for future work.
Visual Relationship Detection using Scene Graphs: A Survey
May 16, 2020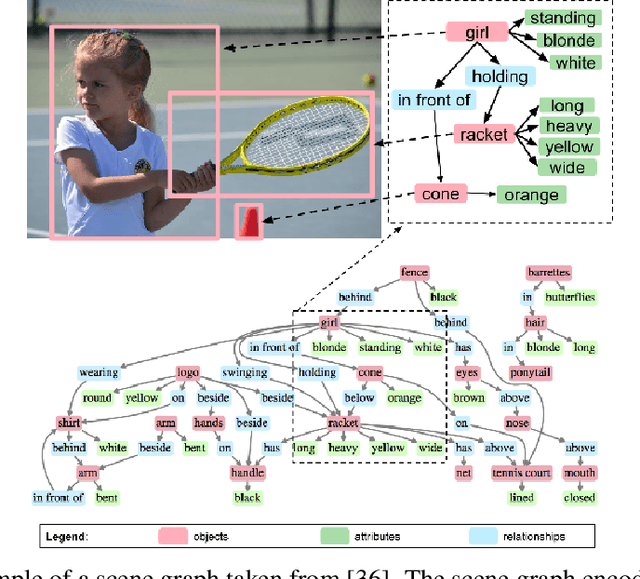
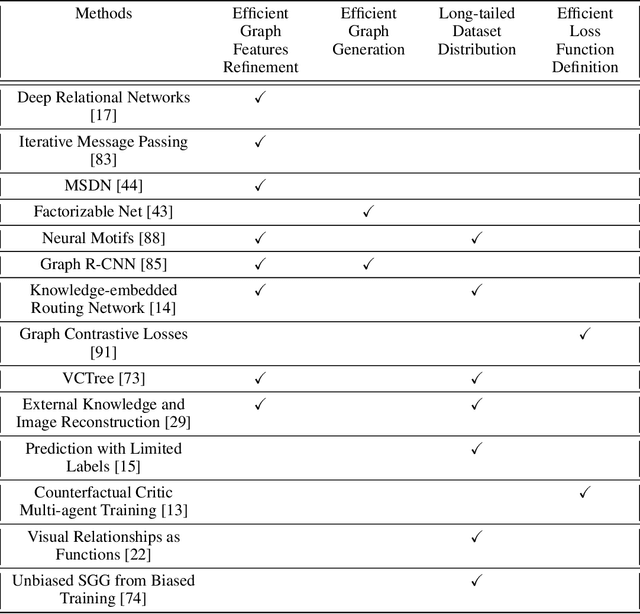
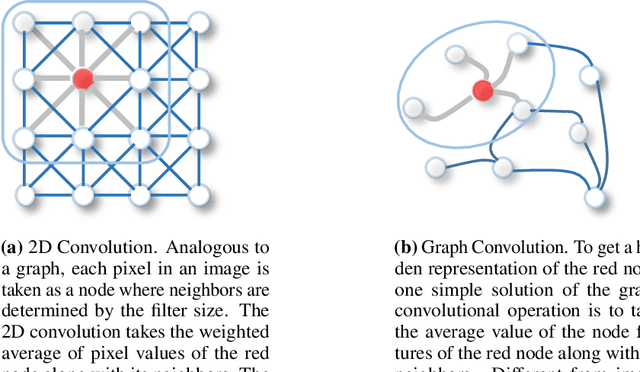
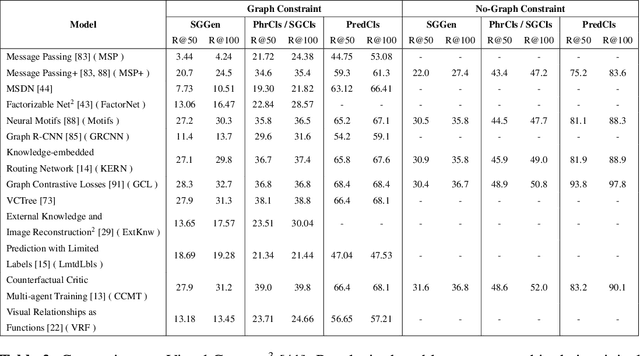
Understanding a scene by decoding the visual relationships depicted in an image has been a long studied problem. While the recent advances in deep learning and the usage of deep neural networks have achieved near human accuracy on many tasks, there still exists a pretty big gap between human and machine level performance when it comes to various visual relationship detection tasks. Developing on earlier tasks like object recognition, segmentation and captioning which focused on a relatively coarser image understanding, newer tasks have been introduced recently to deal with a finer level of image understanding. A Scene Graph is one such technique to better represent a scene and the various relationships present in it. With its wide number of applications in various tasks like Visual Question Answering, Semantic Image Retrieval, Image Generation, among many others, it has proved to be a useful tool for deeper and better visual relationship understanding. In this paper, we present a detailed survey on the various techniques for scene graph generation, their efficacy to represent visual relationships and how it has been used to solve various downstream tasks. We also attempt to analyze the various future directions in which the field might advance in the future. Being one of the first papers to give a detailed survey on this topic, we also hope to give a succinct introduction to scene graphs, and guide practitioners while developing approaches for their applications.