 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrack, Check, Repeat: An EM Approach to Unsupervised Tracking
Apr 07, 2021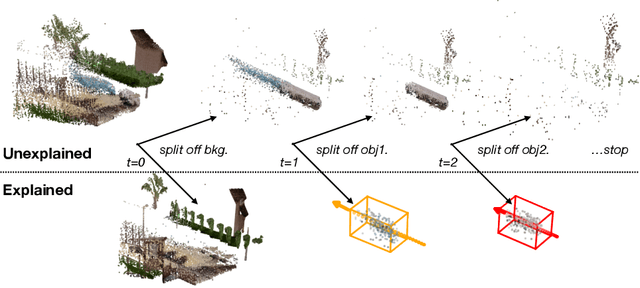
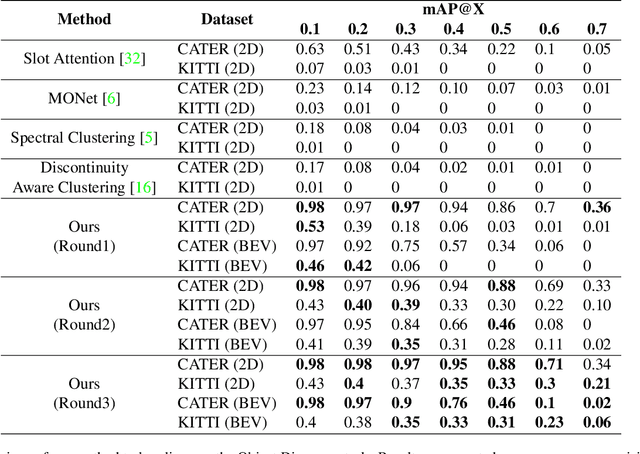


We propose an unsupervised method for detecting and tracking moving objects in 3D, in unlabelled RGB-D videos. The method begins with classic handcrafted techniques for segmenting objects using motion cues: we estimate optical flow and camera motion, and conservatively segment regions that appear to be moving independently of the background. Treating these initial segments as pseudo-labels, we learn an ensemble of appearance-based 2D and 3D detectors, under heavy data augmentation. We use this ensemble to detect new instances of the "moving" type, even if they are not moving, and add these as new pseudo-labels. Our method is an expectation-maximization algorithm, where in the expectation step we fire all modules and look for agreement among them, and in the maximization step we re-train the modules to improve this agreement. The constraint of ensemble agreement helps combat contamination of the generated pseudo-labels (during the E step), and data augmentation helps the modules generalize to yet-unlabelled data (during the M step). We compare against existing unsupervised object discovery and tracking methods, using challenging videos from CATER and KITTI, and show strong improvements over the state-of-the-art.
3D Object Recognition By Corresponding and Quantizing Neural 3D Scene Representations
Oct 30, 2020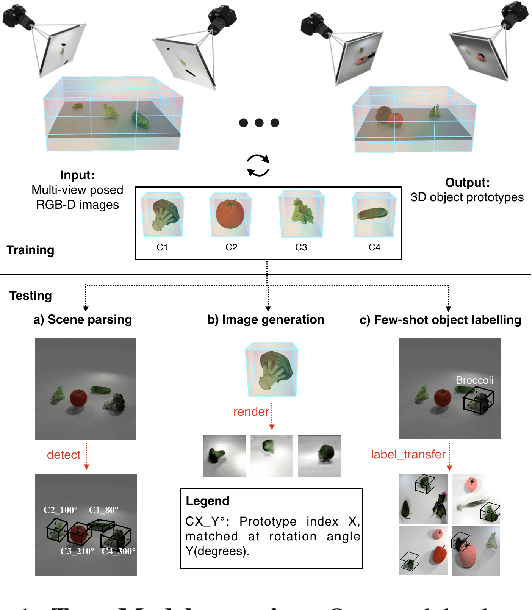
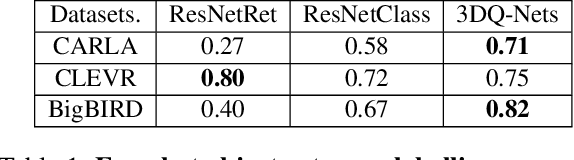
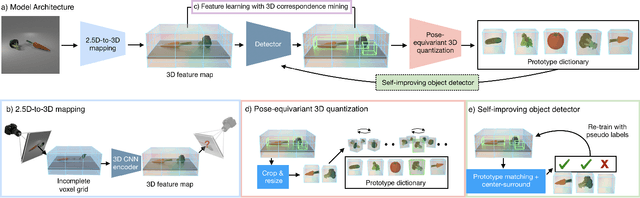
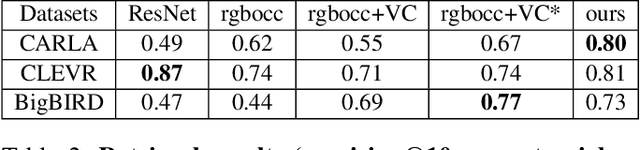
We propose a system that learns to detect objects and infer their 3D poses in RGB-D images. Many existing systems can identify objects and infer 3D poses, but they heavily rely on human labels and 3D annotations. The challenge here is to achieve this without relying on strong supervision signals. To address this challenge, we propose a model that maps RGB-D images to a set of 3D visual feature maps in a differentiable fully-convolutional manner, supervised by predicting views. The 3D feature maps correspond to a featurization of the 3D world scene depicted in the images. The object 3D feature representations are invariant to camera viewpoint changes or zooms, which means feature matching can identify similar objects under different camera viewpoints. We can compare the 3D feature maps of two objects by searching alignment across scales and 3D rotations, and, as a result of the operation, we can estimate pose and scale changes without the need for 3D pose annotations. We cluster object feature maps into a set of 3D prototypes that represent familiar objects in canonical scales and orientations. We then parse images by inferring the prototype identity and 3D pose for each detected object. We compare our method to numerous baselines that do not learn 3D feature visual representations or do not attempt to correspond features across scenes, and outperform them by a large margin in the tasks of object retrieval and object pose estimation. Thanks to the 3D nature of the object-centric feature maps, the visual similarity cues are invariant to 3D pose changes or small scale changes, which gives our method an advantage over 2D and 1D methods.