 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D View Prediction Models of the Dorsal Visual Stream
Sep 04, 2023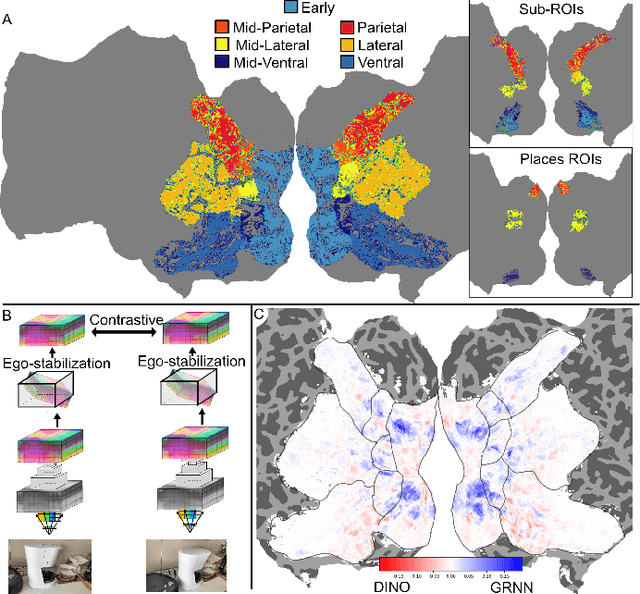
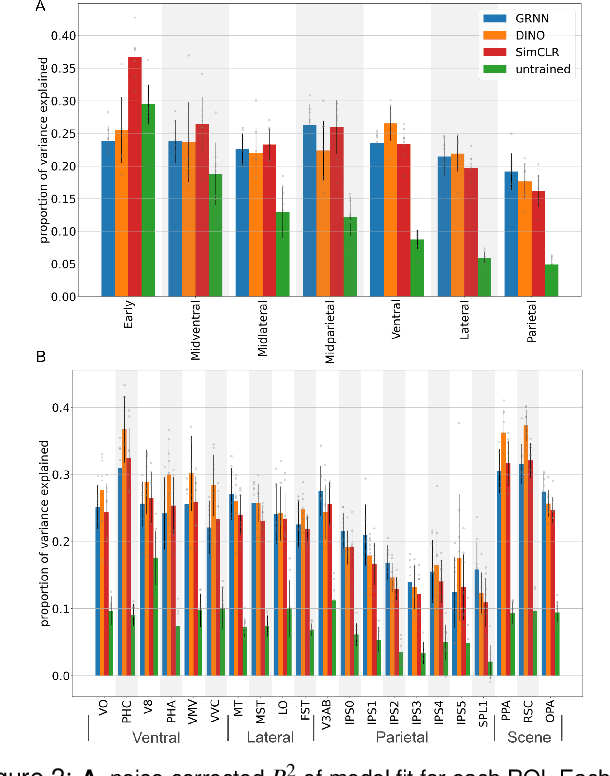
Deep neural network representations align well with brain activity in the ventral visual stream. However, the primate visual system has a distinct dorsal processing stream with different functional properties. To test if a model trained to perceive 3D scene geometry aligns better with neural responses in dorsal visual areas, we trained a self-supervised geometry-aware recurrent neural network (GRNN) to predict novel camera views using a 3D feature memory. We compared GRNN to self-supervised baseline models that have been shown to align well with ventral regions using the large-scale fMRI Natural Scenes Dataset (NSD). We found that while the baseline models accounted better for ventral brain regions, GRNN accounted for a greater proportion of variance in dorsal brain regions. Our findings demonstrate the potential for using task-relevant models to probe representational differences across visual streams.
3D-OES: Viewpoint-Invariant Object-Factorized Environment Simulators
Nov 12, 2020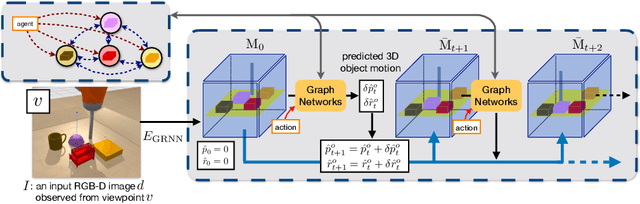


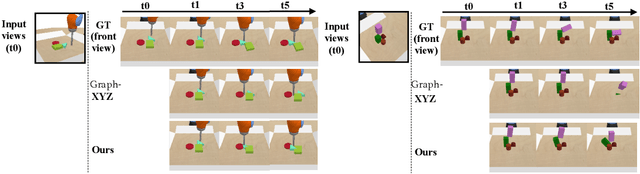
We propose an action-conditioned dynamics model that predicts scene changes caused by object and agent interactions in a viewpoint-invariant 3D neural scene representation space, inferred from RGB-D videos. In this 3D feature space, objects do not interfere with one another and their appearance persists over time and across viewpoints. This permits our model to predict future scenes long in the future by simply "moving" 3D object features based on cumulative object motion predictions. Object motion predictions are computed by a graph neural network that operates over the object features extracted from the 3D neural scene representation. Our model's simulations can be decoded by a neural renderer into2D image views from any desired viewpoint, which aids the interpretability of our latent 3D simulation space. We show our model generalizes well its predictions across varying number and appearances of interacting objects as well as across camera viewpoints, outperforming existing 2D and 3D dynamics models. We further demonstrate sim-to-real transfer of the learnt dynamics by applying our model trained solely in simulation to model-based control for pushing objects to desired locations under clutter on a real robotic setup
3D Object Recognition By Corresponding and Quantizing Neural 3D Scene Representations
Oct 30, 2020
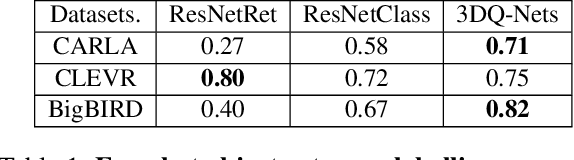
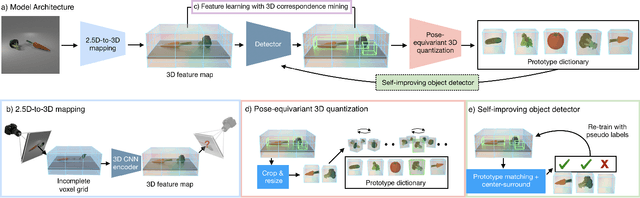
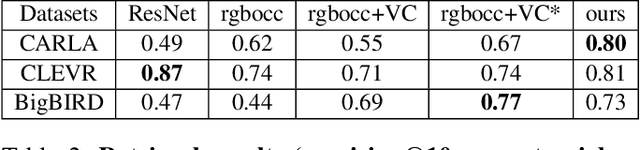
We propose a system that learns to detect objects and infer their 3D poses in RGB-D images. Many existing systems can identify objects and infer 3D poses, but they heavily rely on human labels and 3D annotations. The challenge here is to achieve this without relying on strong supervision signals. To address this challenge, we propose a model that maps RGB-D images to a set of 3D visual feature maps in a differentiable fully-convolutional manner, supervised by predicting views. The 3D feature maps correspond to a featurization of the 3D world scene depicted in the images. The object 3D feature representations are invariant to camera viewpoint changes or zooms, which means feature matching can identify similar objects under different camera viewpoints. We can compare the 3D feature maps of two objects by searching alignment across scales and 3D rotations, and, as a result of the operation, we can estimate pose and scale changes without the need for 3D pose annotations. We cluster object feature maps into a set of 3D prototypes that represent familiar objects in canonical scales and orientations. We then parse images by inferring the prototype identity and 3D pose for each detected object. We compare our method to numerous baselines that do not learn 3D feature visual representations or do not attempt to correspond features across scenes, and outperform them by a large margin in the tasks of object retrieval and object pose estimation. Thanks to the 3D nature of the object-centric feature maps, the visual similarity cues are invariant to 3D pose changes or small scale changes, which gives our method an advantage over 2D and 1D methods.
Embodied Language Grounding with Implicit 3D Visual Feature Representations
Oct 02, 2019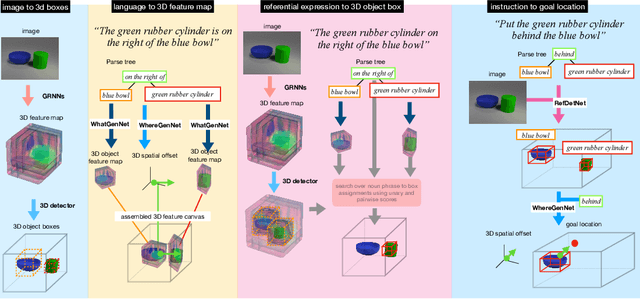



Consider the utterance "the tomato is to the left of the pot." Humans can answer numerous questions about the situation described, as well as reason through counterfactuals and alternatives, such as, "is the pot larger than the tomato ?", "can we move to a viewpoint from which the tomato is completely hidden behind the pot ?", "can we have an object that is both to the left of the tomato and to the right of the pot ?", "would the tomato fit inside the pot ?", and so on. Such reasoning capability remains elusive from current computational models of language understanding. To link language processing with spatial reasoning, we propose associating natural language utterances to a mental workspace of their meaning, encoded as 3-dimensional visual feature representations of the world scenes they describe. We learn such 3-dimensional visual representations---we call them visual imaginations--- by predicting images a mobile agent sees while moving around in the 3D world. The input image streams the agent collects are unprojected into egomotion-stable 3D scene feature maps of the scene, and projected from novel viewpoints to match the observed RGB image views in an end-to-end differentiable manner. We then train modular neural models to generate such 3D feature representations given language utterances, to localize the objects an utterance mentions in the 3D feature representation inferred from an image, and to predict the desired 3D object locations given a manipulation instruction. We empirically show the proposed models outperform by a large margin existing 2D models in spatial reasoning, referential object detection and instruction following, and generalize better across camera viewpoints and object arrangements.
Embodied View-Contrastive 3D Feature Learning
Jul 10, 2019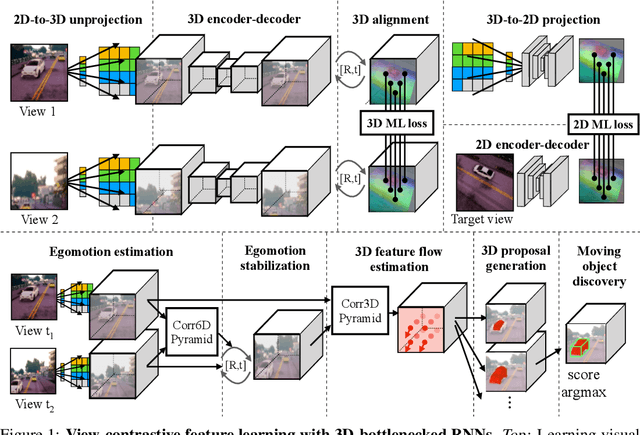
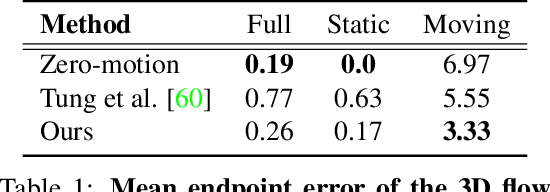

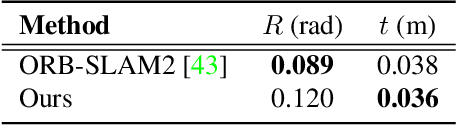
Humans can effortlessly imagine the occluded side of objects in a photograph. We do not simply see the photograph as a flat 2D surface, we perceive the 3D visual world captured in it, by using our imagination to inpaint the information lost during camera projection. We propose neural architectures that similarly learn to approximately imagine abstractions of the 3D world depicted in 2D images. We show that this capability suffices to localize moving objects in 3D, without using any human annotations. Our models are recurrent neural networks that consume RGB or RGB-D videos, and learn to predict novel views of the scene from queried camera viewpoints. They are equipped with a 3D representation bottleneck that learns an egomotion-stabilized and geometrically consistent deep feature map of the 3D world scene. They estimate camera motion from frame to frame, and cancel it from the extracted 2D features before fusing them in the latent 3D map. We handle multimodality and stochasticity in prediction using ranking-based contrastive losses, and show that they can scale to photorealistic imagery, in contrast to regression or VAE alternatives. Our model proposes 3D boxes for moving objects by estimating a 3D motion flow field between its temporally consecutive 3D imaginations, and thresholding motion magnitude: camera motion has been cancelled in the latent 3D space, and thus any non-zero motion is an indication of an independently moving object. Our work underlines the importance of 3D representations and egomotion stabilization for visual recognition, and proposes a viable computational model for learning 3D visual feature representations and 3D object bounding boxes supervised by moving and watching objects move.
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
Dec 31, 2018

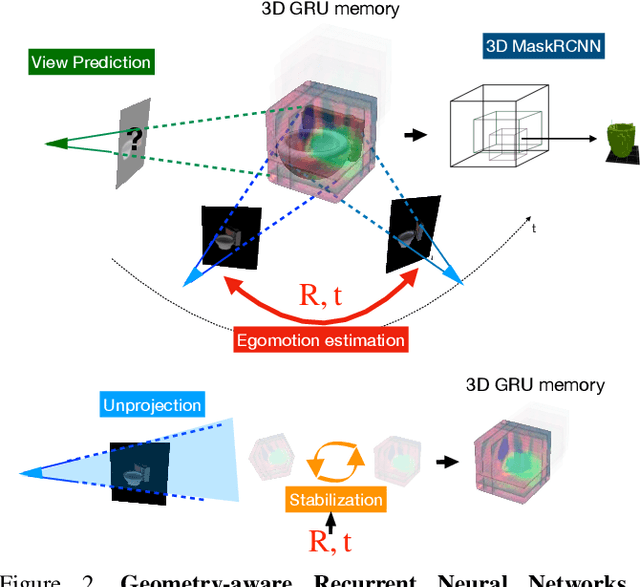
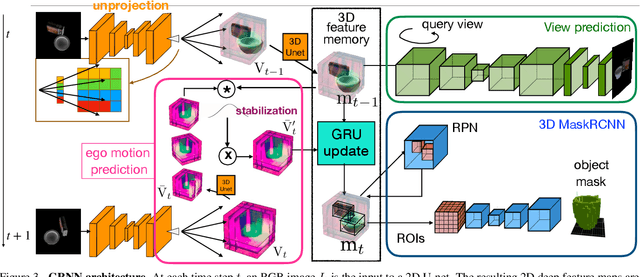
We integrate two powerful ideas, geometry and deep visual representation learning, into recurrent network architectures for mobile visual scene understanding. The proposed networks learn to "lift" 2D visual features and integrate them over time into latent 3D feature maps of the scene. They are equipped with differentiable geometric operations, such as projection, unprojection, egomotion estimation and stabilization, in order to compute a geometrically-consistent mapping between the world scene and their 3D latent feature space. We train the proposed architectures to predict novel image views given short frame sequences as input. Their predictions strongly generalize to scenes with a novel number of objects, appearances and configurations, and greatly outperform predictions of previous works that do not consider egomotion stabilization or a space-aware latent feature space. We train the proposed architectures to detect and segment objects in 3D, using the latent 3D feature map as input--as opposed to any input 2D video frame. The resulting detections are permanent: they continue to exist even when an object gets occluded or leaves the field of view. Our experiments suggest the proposed space-aware latent feature arrangement and egomotion-stabilized convolutions are essential architectural choices for spatial common sense to emerge in artificial embodied visual agents.
Reward Learning from Narrated Demonstrations
Apr 27, 2018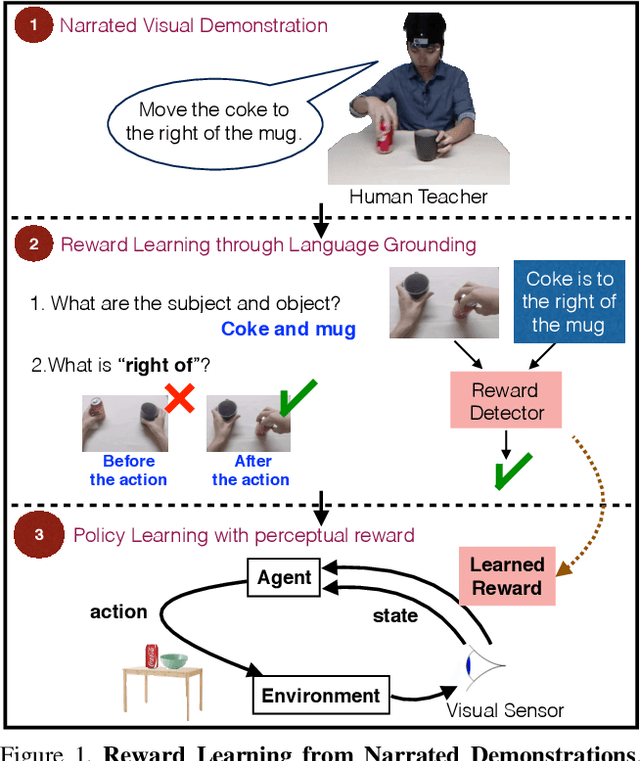
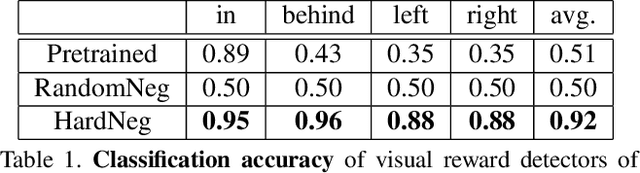

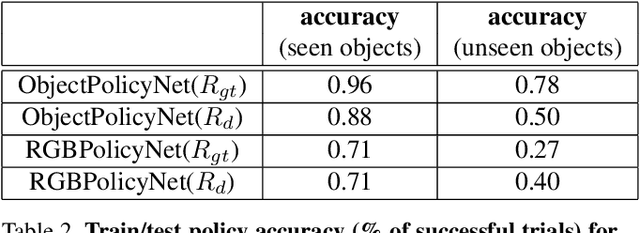
Humans effortlessly "program" one another by communicating goals and desires in natural language. In contrast, humans program robotic behaviours by indicating desired object locations and poses to be achieved, by providing RGB images of goal configurations, or supplying a demonstration to be imitated. None of these methods generalize across environment variations, and they convey the goal in awkward technical terms. This work proposes joint learning of natural language grounding and instructable behavioural policies reinforced by perceptual detectors of natural language expressions, grounded to the sensory inputs of the robotic agent. Our supervision is narrated visual demonstrations(NVD), which are visual demonstrations paired with verbal narration (as opposed to being silent). We introduce a dataset of NVD where teachers perform activities while describing them in detail. We map the teachers' descriptions to perceptual reward detectors, and use them to train corresponding behavioural policies in simulation.We empirically show that our instructable agents (i) learn visual reward detectors using a small number of examples by exploiting hard negative mined configurations from demonstration dynamics, (ii) develop pick-and place policies using learned visual reward detectors, (iii) benefit from object-factorized state representations that mimic the syntactic structure of natural language goal expressions, and (iv) can execute behaviours that involve novel objects in novel locations at test time, instructed by natural language.
Self-supervised Learning of Motion Capture
Dec 04, 2017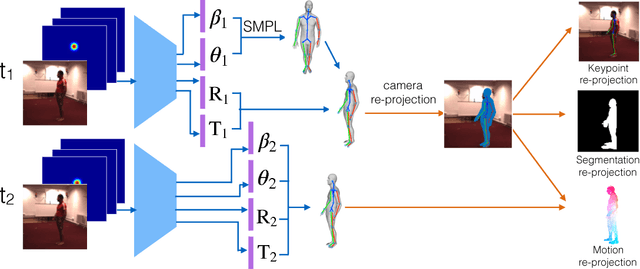
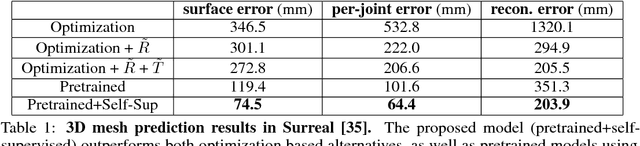
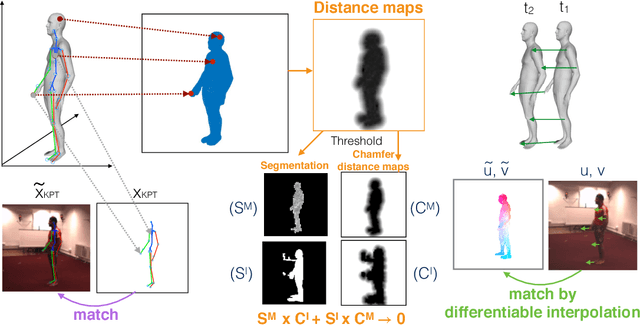
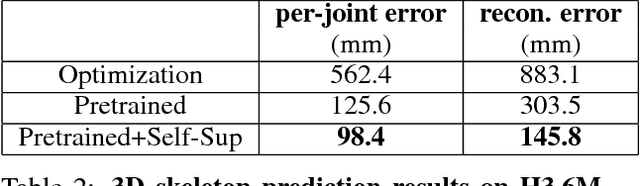
Current state-of-the-art solutions for motion capture from a single camera are optimization driven: they optimize the parameters of a 3D human model so that its re-projection matches measurements in the video (e.g. person segmentation, optical flow, keypoint detections etc.). Optimization models are susceptible to local minima. This has been the bottleneck that forced using clean green-screen like backgrounds at capture time, manual initialization, or switching to multiple cameras as input resource. In this work, we propose a learning based motion capture model for single camera input. Instead of optimizing mesh and skeleton parameters directly, our model optimizes neural network weights that predict 3D shape and skeleton configurations given a monocular RGB video. Our model is trained using a combination of strong supervision from synthetic data, and self-supervision from differentiable rendering of (a) skeletal keypoints, (b) dense 3D mesh motion, and (c) human-background segmentation, in an end-to-end framework. Empirically we show our model combines the best of both worlds of supervised learning and test-time optimization: supervised learning initializes the model parameters in the right regime, ensuring good pose and surface initialization at test time, without manual effort. Self-supervision by back-propagating through differentiable rendering allows (unsupervised) adaptation of the model to the test data, and offers much tighter fit than a pretrained fixed model. We show that the proposed model improves with experience and converges to low-error solutions where previous optimization methods fail.
Adversarial Inverse Graphics Networks: Learning 2D-to-3D Lifting and Image-to-Image Translation from Unpaired Supervision
Sep 02, 2017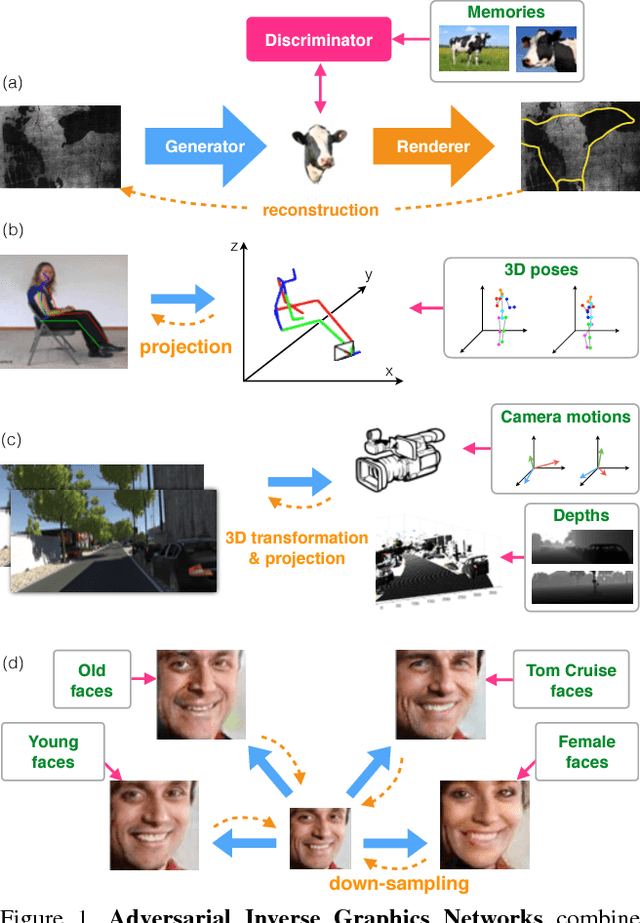
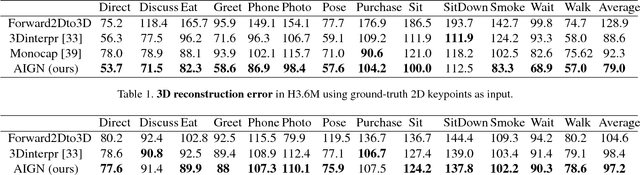
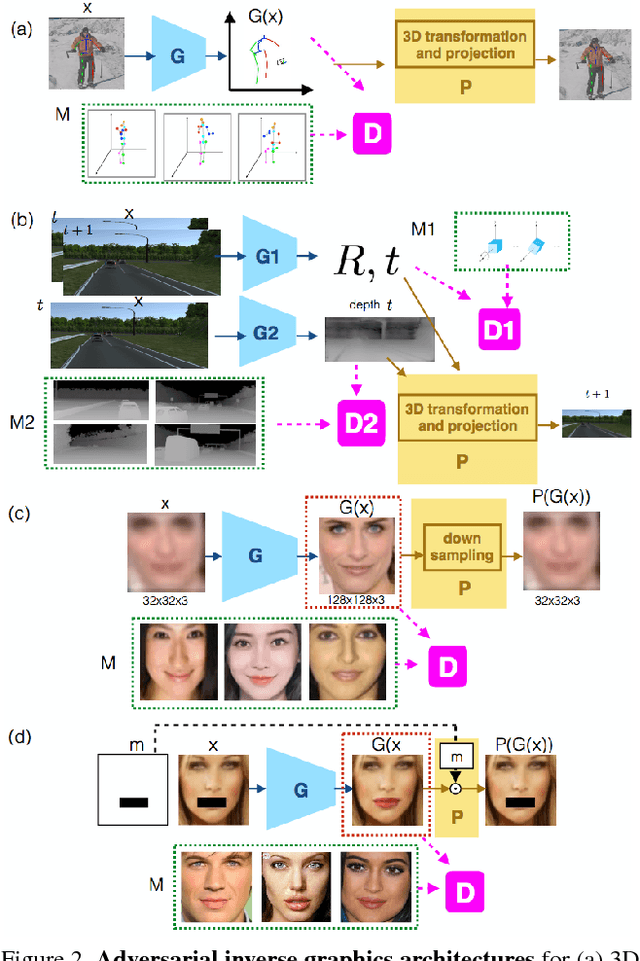
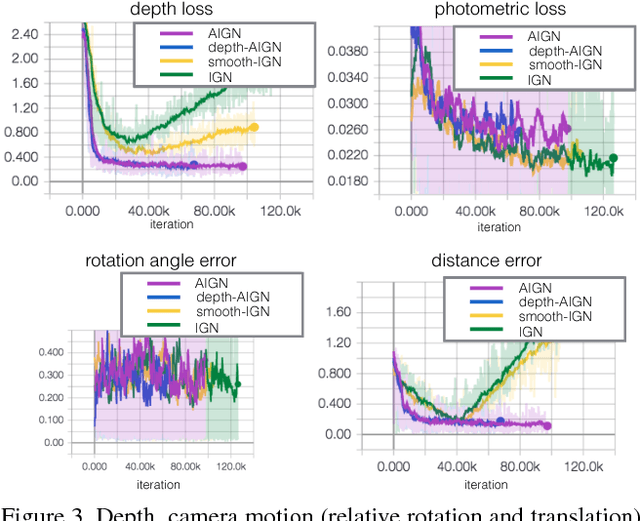
Researchers have developed excellent feed-forward models that learn to map images to desired outputs, such as to the images' latent factors, or to other images, using supervised learning. Learning such mappings from unlabelled data, or improving upon supervised models by exploiting unlabelled data, remains elusive. We argue that there are two important parts to learning without annotations: (i) matching the predictions to the input observations, and (ii) matching the predictions to known priors. We propose Adversarial Inverse Graphics networks (AIGNs): weakly supervised neural network models that combine feedback from rendering their predictions, with distribution matching between their predictions and a collection of ground-truth factors. We apply AIGNs to 3D human pose estimation and 3D structure and egomotion estimation, and outperform models supervised by only paired annotations. We further apply AIGNs to facial image transformation using super-resolution and inpainting renderers, while deliberately adding biases in the ground-truth datasets. Our model seamlessly incorporates such biases, rendering input faces towards young, old, feminine, masculine or Tom Cruise-like equivalents (depending on the chosen bias), or adding lip and nose augmentations while inpainting concealed lips and noses.
Spectral Methods for Nonparametric Models
Mar 31, 2017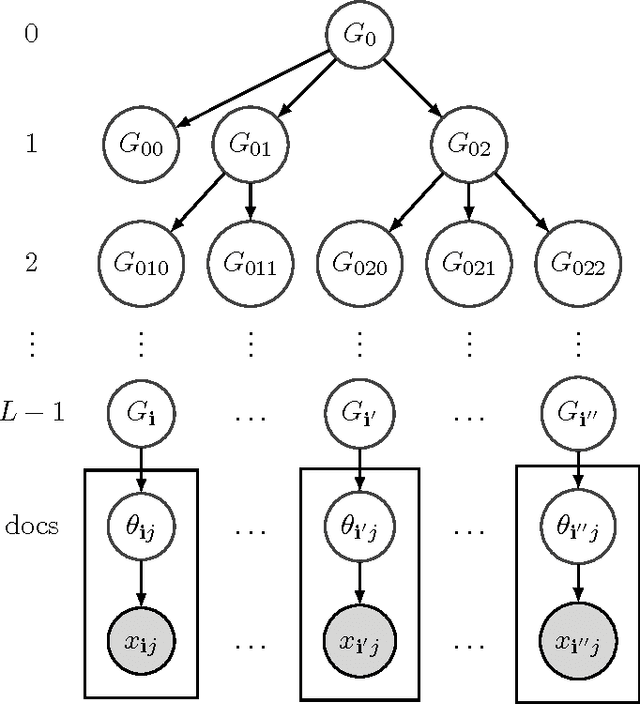

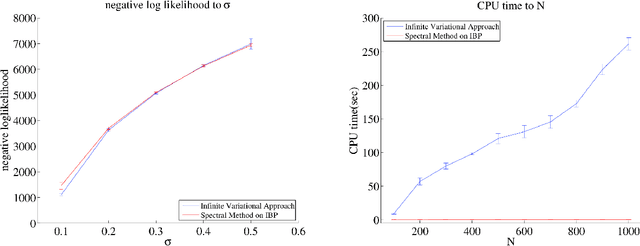

Nonparametric models are versatile, albeit computationally expensive, tool for modeling mixture models. In this paper, we introduce spectral methods for the two most popular nonparametric models: the Indian Buffet Process (IBP) and the Hierarchical Dirichlet Process (HDP). We show that using spectral methods for the inference of nonparametric models are computationally and statistically efficient. In particular, we derive the lower-order moments of the IBP and the HDP, propose spectral algorithms for both models, and provide reconstruction guarantees for the algorithms. For the HDP, we further show that applying hierarchical models on dataset with hierarchical structure, which can be solved with the generalized spectral HDP, produces better solutions to that of flat models regarding likelihood performance.