 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Visual Sim-to-Real Gap with Object-Composable NeRFs
Mar 07, 2024Deep learning methods for perception are the cornerstone of many robotic systems. Despite their potential for impressive performance, obtaining real-world training data is expensive, and can be impractically difficult for some tasks. Sim-to-real transfer with domain randomization offers a potential workaround, but often requires extensive manual tuning and results in models that are brittle to distribution shift between sim and real. In this work, we introduce Composable Object Volume NeRF (COV-NeRF), an object-composable NeRF model that is the centerpiece of a real-to-sim pipeline for synthesizing training data targeted to scenes and objects from the real world. COV-NeRF extracts objects from real images and composes them into new scenes, generating photorealistic renderings and many types of 2D and 3D supervision, including depth maps, segmentation masks, and meshes. We show that COV-NeRF matches the rendering quality of modern NeRF methods, and can be used to rapidly close the sim-to-real gap across a variety of perceptual modalities.
Convolutional Occupancy Models for Dense Packing of Complex, Novel Objects
Jul 31, 2023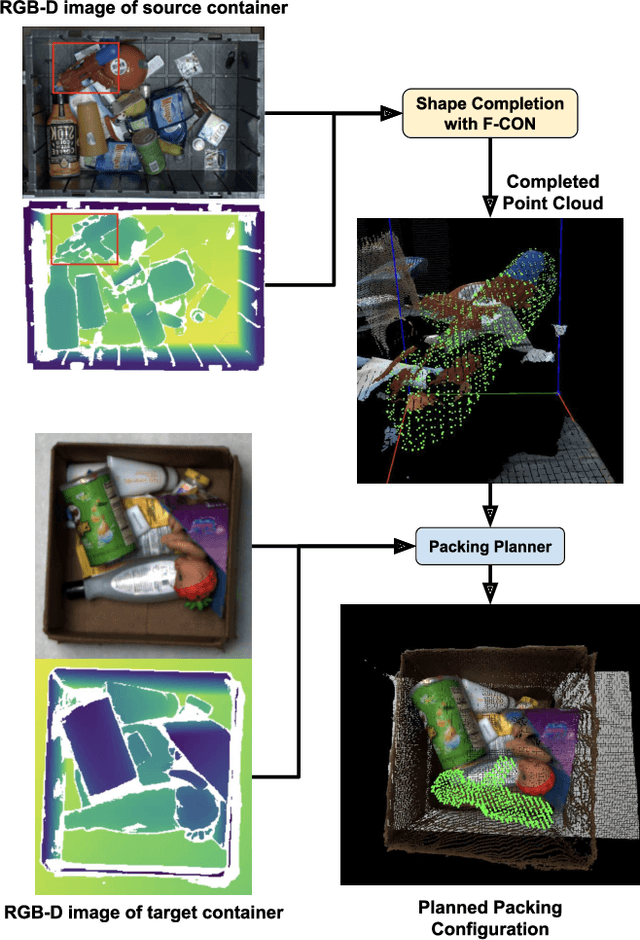
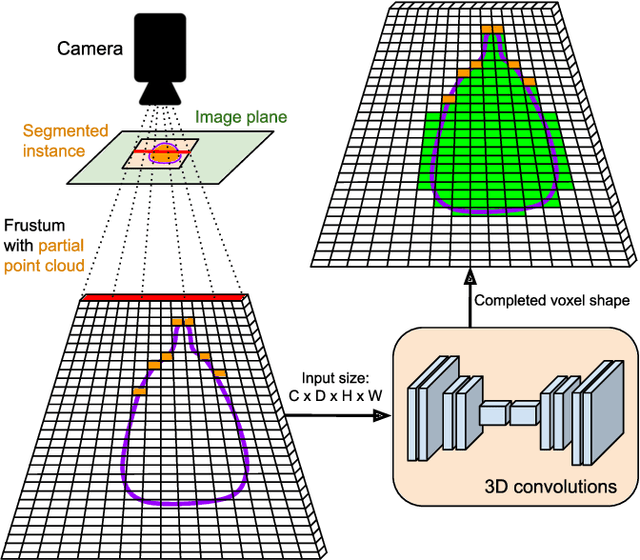

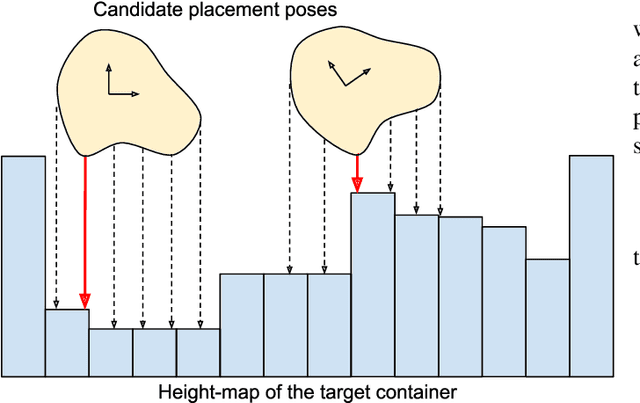
Dense packing in pick-and-place systems is an important feature in many warehouse and logistics applications. Prior work in this space has largely focused on planning algorithms in simulation, but real-world packing performance is often bottlenecked by the difficulty of perceiving 3D object geometry in highly occluded, partially observed scenes. In this work, we present a fully-convolutional shape completion model, F-CON, which can be easily combined with off-the-shelf planning methods for dense packing in the real world. We also release a simulated dataset, COB-3D-v2, that can be used to train shape completion models for real-word robotics applications, and use it to demonstrate that F-CON outperforms other state-of-the-art shape completion methods. Finally, we equip a real-world pick-and-place system with F-CON, and demonstrate dense packing of complex, unseen objects in cluttered scenes. Across multiple planning methods, F-CON enables substantially better dense packing than other shape completion methods.
Autoregressive Uncertainty Modeling for 3D Bounding Box Prediction
Oct 13, 2022
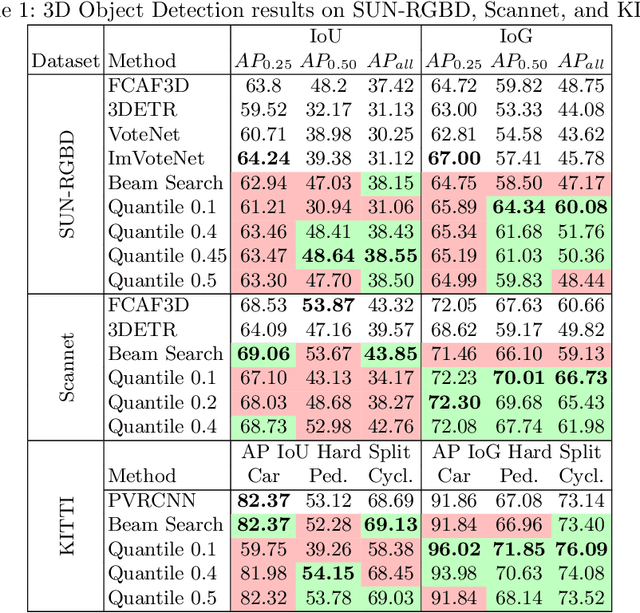
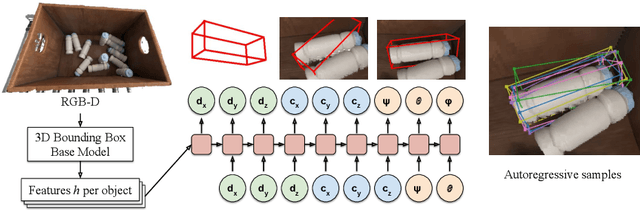
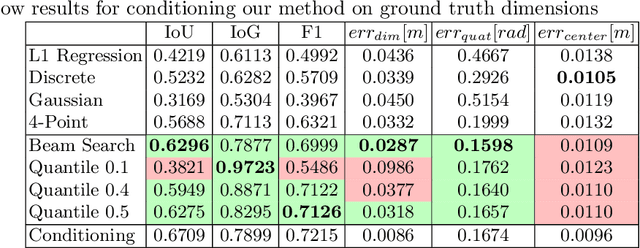
3D bounding boxes are a widespread intermediate representation in many computer vision applications. However, predicting them is a challenging task, largely due to partial observability, which motivates the need for a strong sense of uncertainty. While many recent methods have explored better architectures for consuming sparse and unstructured point cloud data, we hypothesize that there is room for improvement in the modeling of the output distribution and explore how this can be achieved using an autoregressive prediction head. Additionally, we release a simulated dataset, COB-3D, which highlights new types of ambiguity that arise in real-world robotics applications, where 3D bounding box prediction has largely been underexplored. We propose methods for leveraging our autoregressive model to make high confidence predictions and meaningful uncertainty measures, achieving strong results on SUN-RGBD, Scannet, KITTI, and our new dataset.
Embodied Language Grounding with Implicit 3D Visual Feature Representations
Oct 02, 2019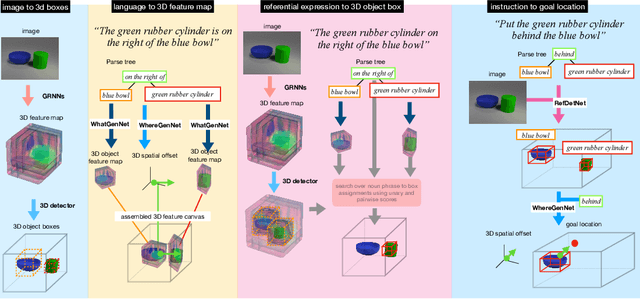



Consider the utterance "the tomato is to the left of the pot." Humans can answer numerous questions about the situation described, as well as reason through counterfactuals and alternatives, such as, "is the pot larger than the tomato ?", "can we move to a viewpoint from which the tomato is completely hidden behind the pot ?", "can we have an object that is both to the left of the tomato and to the right of the pot ?", "would the tomato fit inside the pot ?", and so on. Such reasoning capability remains elusive from current computational models of language understanding. To link language processing with spatial reasoning, we propose associating natural language utterances to a mental workspace of their meaning, encoded as 3-dimensional visual feature representations of the world scenes they describe. We learn such 3-dimensional visual representations---we call them visual imaginations--- by predicting images a mobile agent sees while moving around in the 3D world. The input image streams the agent collects are unprojected into egomotion-stable 3D scene feature maps of the scene, and projected from novel viewpoints to match the observed RGB image views in an end-to-end differentiable manner. We then train modular neural models to generate such 3D feature representations given language utterances, to localize the objects an utterance mentions in the 3D feature representation inferred from an image, and to predict the desired 3D object locations given a manipulation instruction. We empirically show the proposed models outperform by a large margin existing 2D models in spatial reasoning, referential object detection and instruction following, and generalize better across camera viewpoints and object arrangements.
Graph-Structured Visual Imitation
Jul 11, 2019

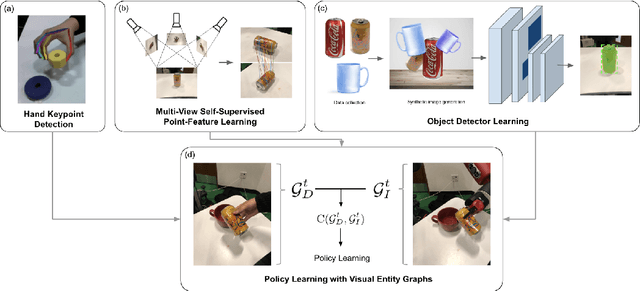
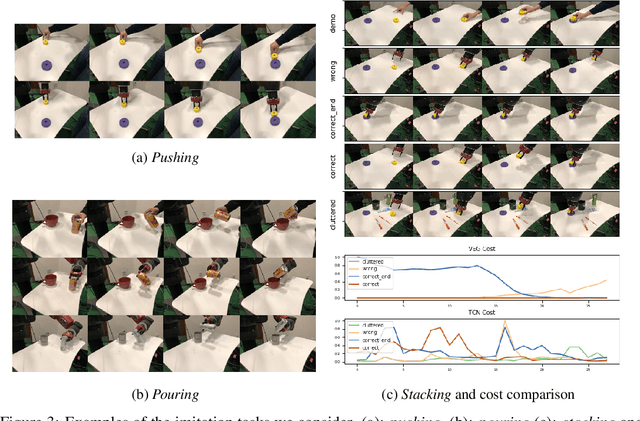
We cast visual imitation as a visual correspondence problem. Our robotic agent is rewarded when its actions result in better matching of relative spatial configurations for corresponding visual entities detected in its workspace and teacher's demonstration. We build upon recent advances in Computer Vision,such as human finger keypoint detectors, object detectors trained on-the-fly with synthetic augmentations, and point detectors supervised by viewpoint changes and learn multiple visual entity detectors for each demonstration without human annotations or robot interactions. We empirically show the proposed factorized visual representations of entities and their spatial arrangements drive successful imitation of a variety of manipulation skills within minutes, using a single demonstration and without any environment instrumentation. It is robust to background clutter and can effectively generalize across environment variations between demonstrator and imitator, greatly outperforming unstructured non-factorized full-frame CNN encodings of previous works.
Probabilistic Trajectory Segmentation by Means of Hierarchical Dirichlet Process Switching Linear Dynamical Systems
Aug 07, 2018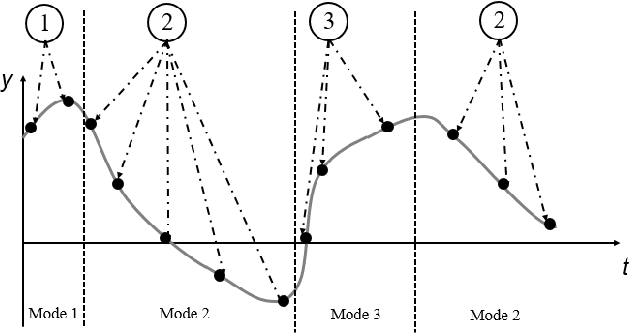
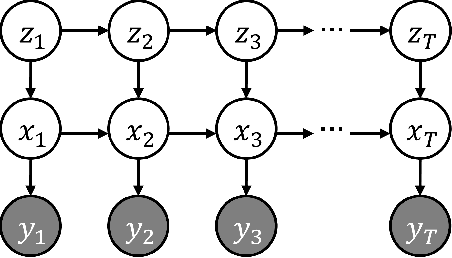
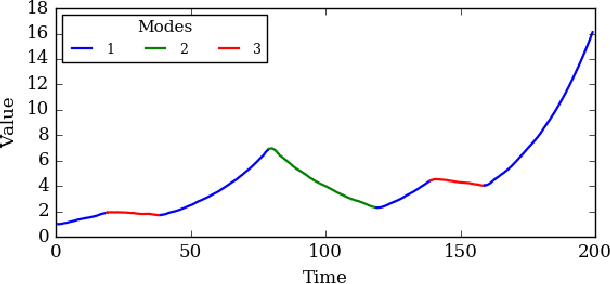
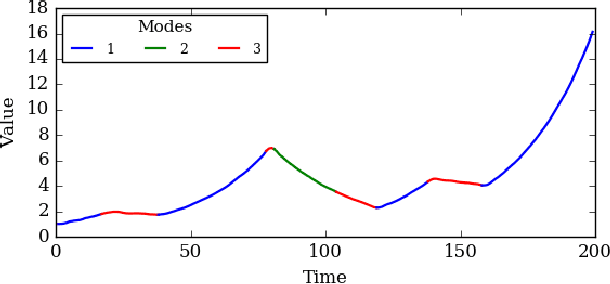
Using movement primitive libraries is an effective means to enable robots to solve more complex tasks. In order to build these movement libraries, current algorithms require a prior segmentation of the demonstration trajectories. A promising approach is to model the trajectory as being generated by a set of Switching Linear Dynamical Systems and inferring a meaningful segmentation by inspecting the transition points characterized by the switching dynamics. With respect to the learning, a nonparametric Bayesian approach is employed utilizing a Gibbs sampler.