 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Visual Sim-to-Real Gap with Object-Composable NeRFs
Mar 07, 2024Deep learning methods for perception are the cornerstone of many robotic systems. Despite their potential for impressive performance, obtaining real-world training data is expensive, and can be impractically difficult for some tasks. Sim-to-real transfer with domain randomization offers a potential workaround, but often requires extensive manual tuning and results in models that are brittle to distribution shift between sim and real. In this work, we introduce Composable Object Volume NeRF (COV-NeRF), an object-composable NeRF model that is the centerpiece of a real-to-sim pipeline for synthesizing training data targeted to scenes and objects from the real world. COV-NeRF extracts objects from real images and composes them into new scenes, generating photorealistic renderings and many types of 2D and 3D supervision, including depth maps, segmentation masks, and meshes. We show that COV-NeRF matches the rendering quality of modern NeRF methods, and can be used to rapidly close the sim-to-real gap across a variety of perceptual modalities.
Convolutional Occupancy Models for Dense Packing of Complex, Novel Objects
Jul 31, 2023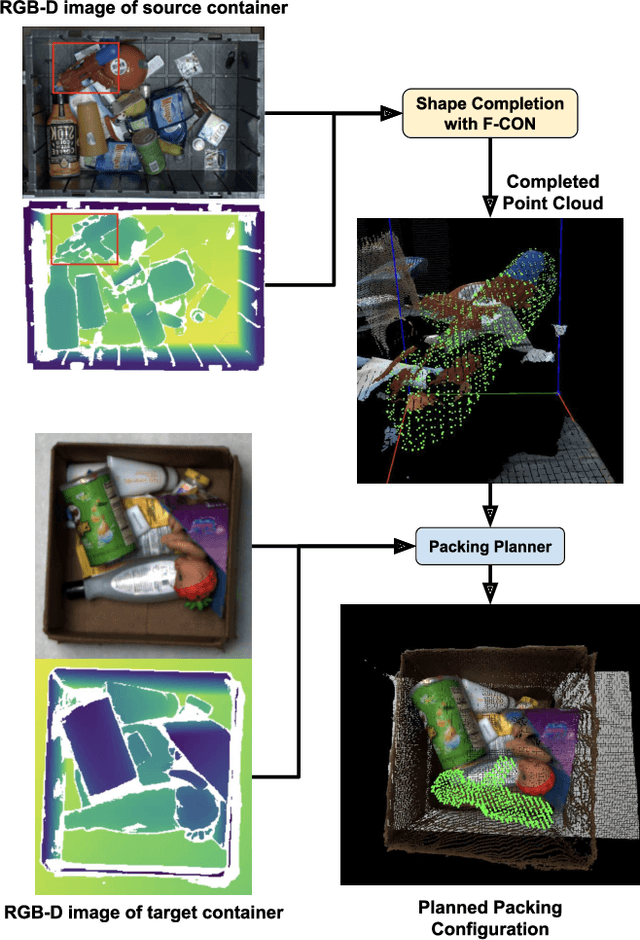
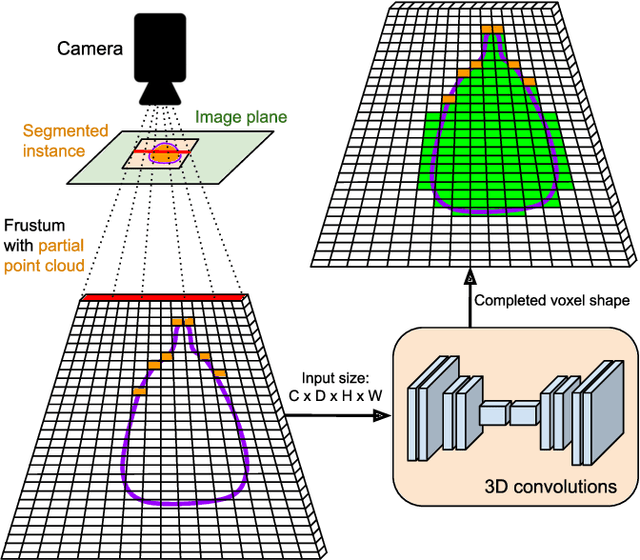

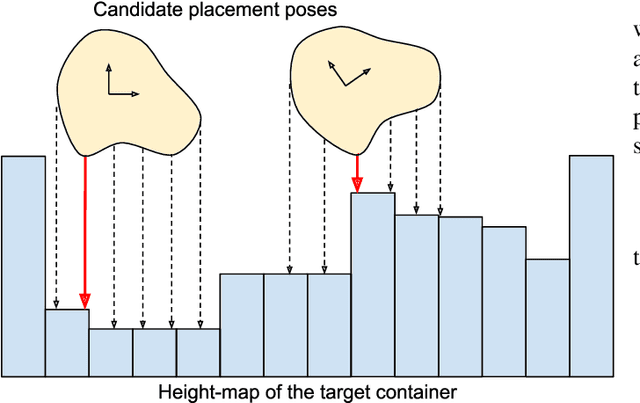
Dense packing in pick-and-place systems is an important feature in many warehouse and logistics applications. Prior work in this space has largely focused on planning algorithms in simulation, but real-world packing performance is often bottlenecked by the difficulty of perceiving 3D object geometry in highly occluded, partially observed scenes. In this work, we present a fully-convolutional shape completion model, F-CON, which can be easily combined with off-the-shelf planning methods for dense packing in the real world. We also release a simulated dataset, COB-3D-v2, that can be used to train shape completion models for real-word robotics applications, and use it to demonstrate that F-CON outperforms other state-of-the-art shape completion methods. Finally, we equip a real-world pick-and-place system with F-CON, and demonstrate dense packing of complex, unseen objects in cluttered scenes. Across multiple planning methods, F-CON enables substantially better dense packing than other shape completion methods.
Distributional Instance Segmentation: Modeling Uncertainty and High Confidence Predictions with Latent-MaskRCNN
May 03, 2023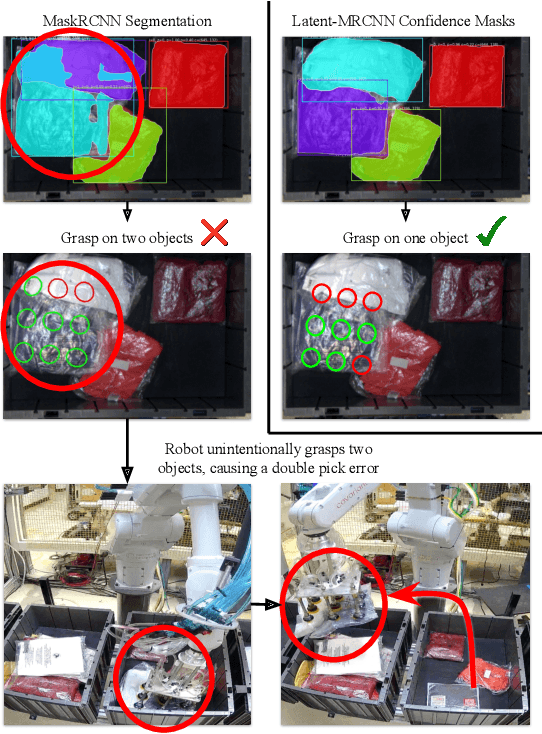

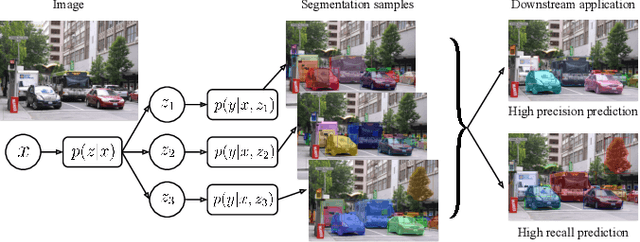
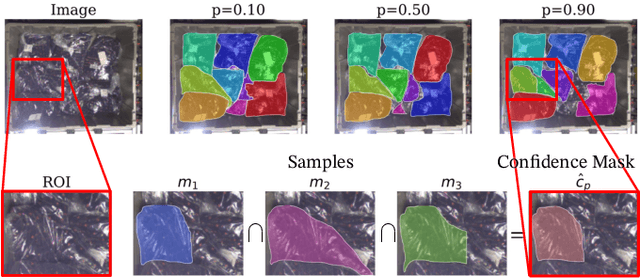
Object recognition and instance segmentation are fundamental skills in any robotic or autonomous system. Existing state-of-the-art methods are often unable to capture meaningful uncertainty in challenging or ambiguous scenes, and as such can cause critical errors in high-performance applications. In this paper, we explore a class of distributional instance segmentation models using latent codes that can model uncertainty over plausible hypotheses of object masks. For robotic picking applications, we propose a confidence mask method to achieve the high precision necessary in industrial use cases. We show that our method can significantly reduce critical errors in robotic systems, including our newly released dataset of ambiguous scenes in a robotic application. On a real-world apparel-picking robot, our method significantly reduces double pick errors while maintaining high performance.
Autoregressive Uncertainty Modeling for 3D Bounding Box Prediction
Oct 13, 2022
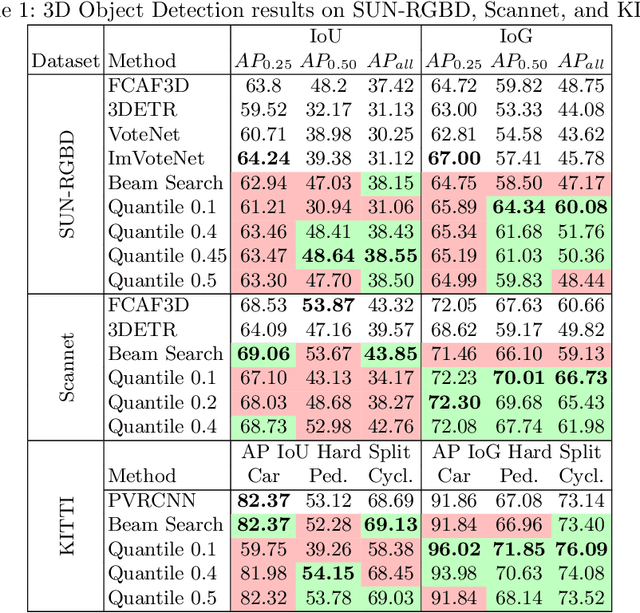
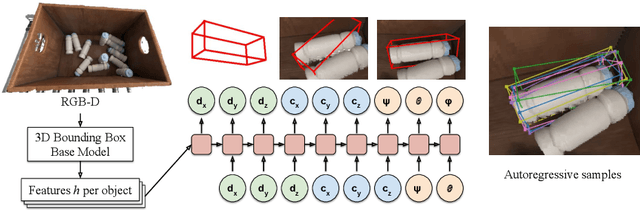
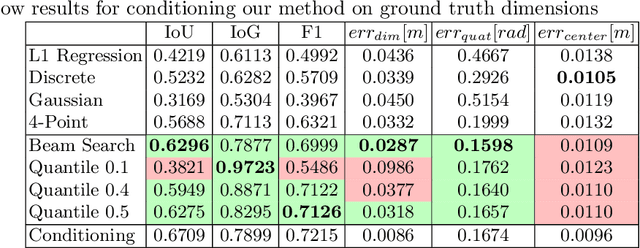
3D bounding boxes are a widespread intermediate representation in many computer vision applications. However, predicting them is a challenging task, largely due to partial observability, which motivates the need for a strong sense of uncertainty. While many recent methods have explored better architectures for consuming sparse and unstructured point cloud data, we hypothesize that there is room for improvement in the modeling of the output distribution and explore how this can be achieved using an autoregressive prediction head. Additionally, we release a simulated dataset, COB-3D, which highlights new types of ambiguity that arise in real-world robotics applications, where 3D bounding box prediction has largely been underexplored. We propose methods for leveraging our autoregressive model to make high confidence predictions and meaningful uncertainty measures, achieving strong results on SUN-RGBD, Scannet, KITTI, and our new dataset.
A Simple Neural Attentive Meta-Learner
Feb 25, 2018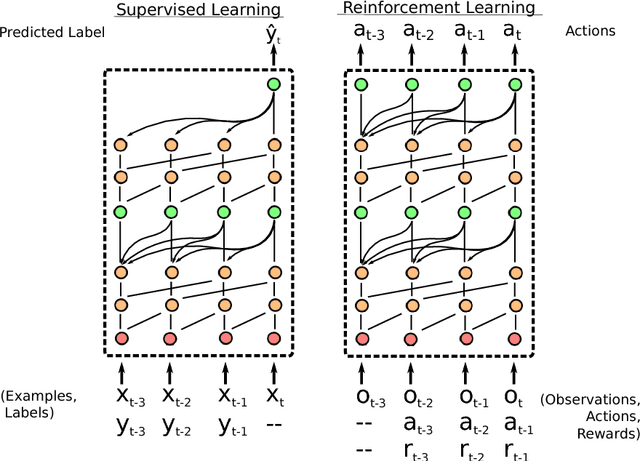
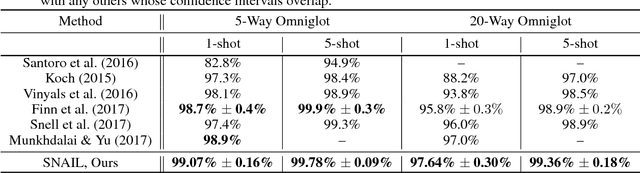
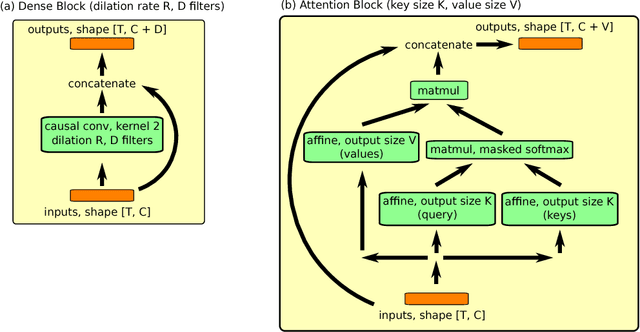

Deep neural networks excel in regimes with large amounts of data, but tend to struggle when data is scarce or when they need to adapt quickly to changes in the task. In response, recent work in meta-learning proposes training a meta-learner on a distribution of similar tasks, in the hopes of generalization to novel but related tasks by learning a high-level strategy that captures the essence of the problem it is asked to solve. However, many recent meta-learning approaches are extensively hand-designed, either using architectures specialized to a particular application, or hard-coding algorithmic components that constrain how the meta-learner solves the task. We propose a class of simple and generic meta-learner architectures that use a novel combination of temporal convolutions and soft attention; the former to aggregate information from past experience and the latter to pinpoint specific pieces of information. In the most extensive set of meta-learning experiments to date, we evaluate the resulting Simple Neural AttentIve Learner (or SNAIL) on several heavily-benchmarked tasks. On all tasks, in both supervised and reinforcement learning, SNAIL attains state-of-the-art performance by significant margins.
PixelSNAIL: An Improved Autoregressive Generative Model
Dec 28, 2017
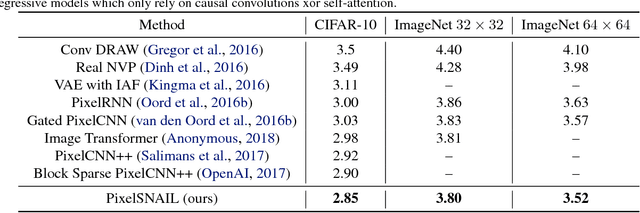
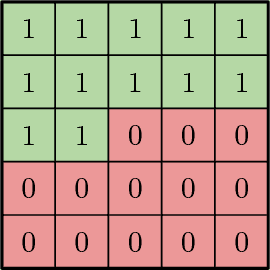
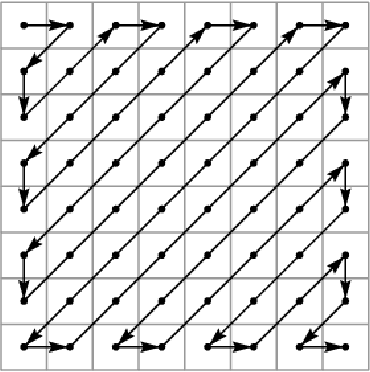
Autoregressive generative models consistently achieve the best results in density estimation tasks involving high dimensional data, such as images or audio. They pose density estimation as a sequence modeling task, where a recurrent neural network (RNN) models the conditional distribution over the next element conditioned on all previous elements. In this paradigm, the bottleneck is the extent to which the RNN can model long-range dependencies, and the most successful approaches rely on causal convolutions, which offer better access to earlier parts of the sequence than conventional RNNs. Taking inspiration from recent work in meta reinforcement learning, where dealing with long-range dependencies is also essential, we introduce a new generative model architecture that combines causal convolutions with self attention. In this note, we describe the resulting model and present state-of-the-art log-likelihood results on CIFAR-10 (2.85 bits per dim) and $32 \times 32$ ImageNet (3.80 bits per dim). Our implementation is available at https://github.com/neocxi/pixelsnail-public
Prediction and Control with Temporal Segment Models
Jul 13, 2017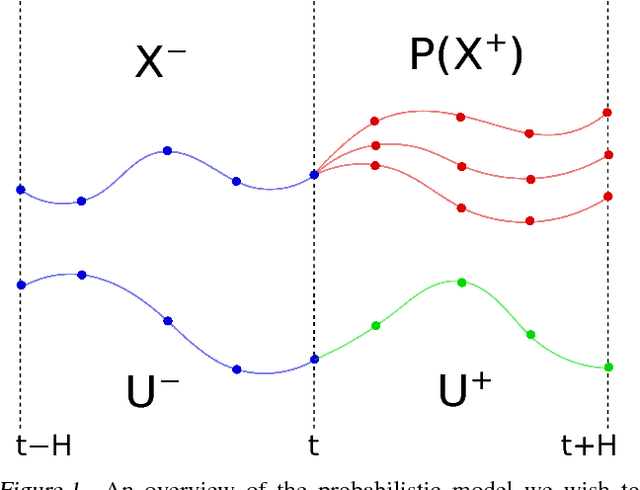
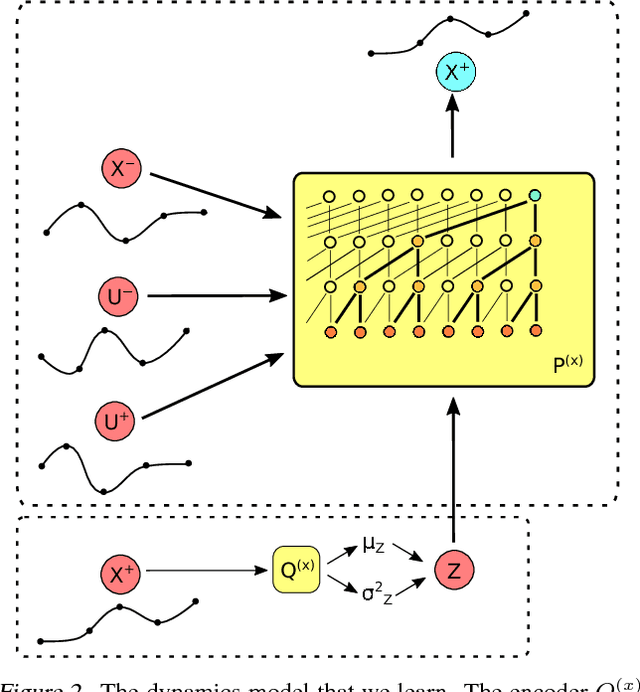
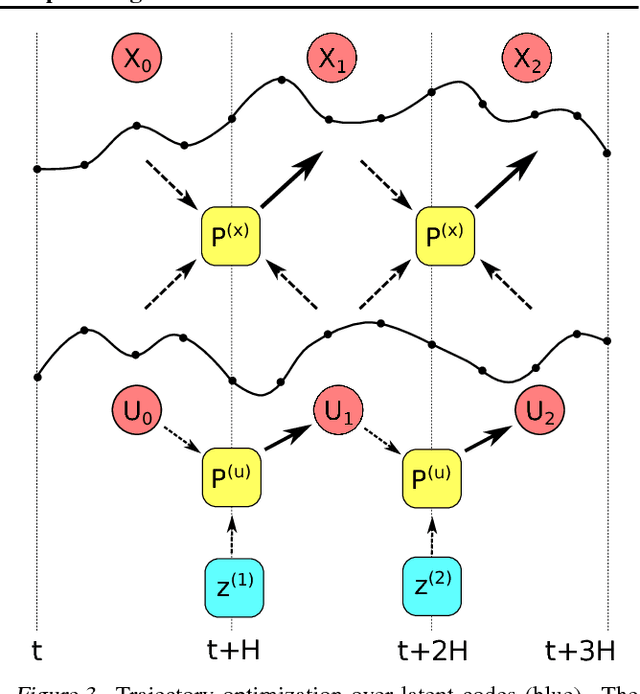
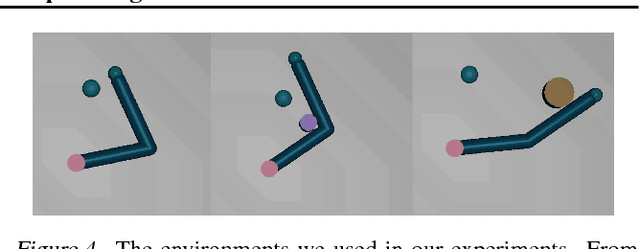
We introduce a method for learning the dynamics of complex nonlinear systems based on deep generative models over temporal segments of states and actions. Unlike dynamics models that operate over individual discrete timesteps, we learn the distribution over future state trajectories conditioned on past state, past action, and planned future action trajectories, as well as a latent prior over action trajectories. Our approach is based on convolutional autoregressive models and variational autoencoders. It makes stable and accurate predictions over long horizons for complex, stochastic systems, effectively expressing uncertainty and modeling the effects of collisions, sensory noise, and action delays. The learned dynamics model and action prior can be used for end-to-end, fully differentiable trajectory optimization and model-based policy optimization, which we use to evaluate the performance and sample-efficiency of our method.