 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSARM2: Multi-Task Stage Aware Reward Modeling for Self Improving Robotic Manipulation
Jun 09, 2026Fine-tuning vision-language-action (VLA) policies for long-horizon manipulation still relies heavily on behavior cloning, which requires costly high-quality demonstrations and keeps policies near the demonstration distribution. Reward models can reduce this dependence by reweighting demonstrations and providing dense supervision for on-robot reinforcement learning (RL), but they must be dense, accurate, and general. Existing methods fall short: task-specific stage-aware models are accurate but require per-task annotations, while general vision-language-model (VLM) reward models are broadly applicable but too coarse for fine-grained long-horizon progress. We introduce RM, a multi-task stage-aware reward model that combines an action-primitive-based stage estimator with a multi-gate Mixture-of-Experts (MMoE) value head to produce dense per-step rewards across manipulation tasks. Building on RM, we further propose SPIRAL (Self-Policy Improvement via Reward-Aligned Learning), an on-policy reward-guided framework that improves VLA policies from cheap autonomous rollouts. On a 10-task benchmark, RM reduces value-estimation MSE by 80% over the strongest baselines; when used in SPIRAL, it improves task success from around 50% to near-perfect performance on Folding Shorts (58% to 100%) and Cleaning Whiteboard (50% to 90%), showing that high-quality dense rewards are key to a stable robot data flywheel. Project website: https://qianzhong-chen.github.io/sarm2.github.io/.
RoboCopilot: Human-in-the-loop Interactive Imitation Learning for Robot Manipulation
Mar 10, 2025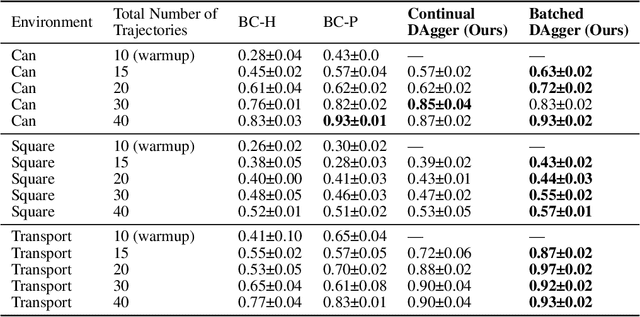
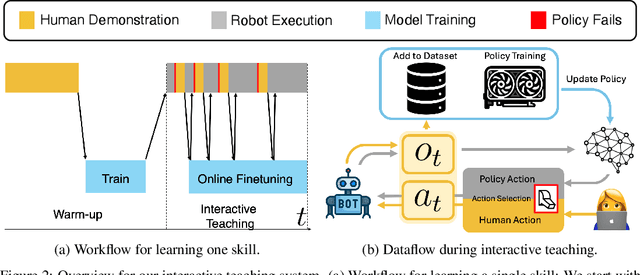
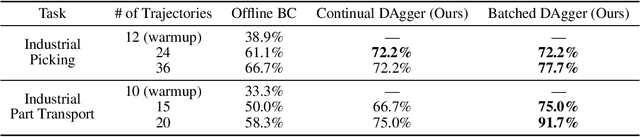
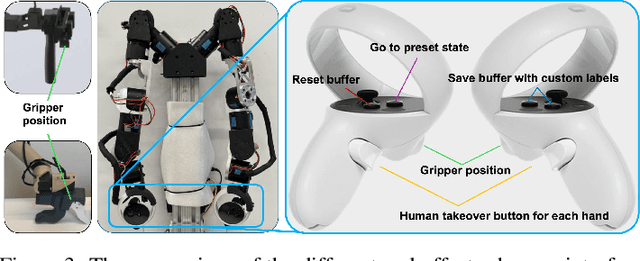
Learning from human demonstration is an effective approach for learning complex manipulation skills. However, existing approaches heavily focus on learning from passive human demonstration data for its simplicity in data collection. Interactive human teaching has appealing theoretical and practical properties, but they are not well supported by existing human-robot interfaces. This paper proposes a novel system that enables seamless control switching between human and an autonomous policy for bi-manual manipulation tasks, enabling more efficient learning of new tasks. This is achieved through a compliant, bilateral teleoperation system. Through simulation and hardware experiments, we demonstrate the value of our system in an interactive human teaching for learning complex bi-manual manipulation skills.
From LLMs to Actions: Latent Codes as Bridges in Hierarchical Robot Control
May 08, 2024



Hierarchical control for robotics has long been plagued by the need to have a well defined interface layer to communicate between high-level task planners and low-level policies. With the advent of LLMs, language has been emerging as a prospective interface layer. However, this has several limitations. Not all tasks can be decomposed into steps that are easily expressible in natural language (e.g. performing a dance routine). Further, it makes end-to-end finetuning on embodied data challenging due to domain shift and catastrophic forgetting. We introduce our method -- Learnable Latent Codes as Bridges (LCB) -- as an alternate architecture to overcome these limitations. \method~uses a learnable latent code to act as a bridge between LLMs and low-level policies. This enables LLMs to flexibly communicate goals in the task plan without being entirely constrained by language limitations. Additionally, it enables end-to-end finetuning without destroying the embedding space of word tokens learned during pre-training. Through experiments on Language Table and Calvin, two common language based benchmarks for embodied agents, we find that \method~outperforms baselines (including those w/ GPT-4V) that leverage pure language as the interface layer on tasks that require reasoning and multi-step behaviors.
GELLO: A General, Low-Cost, and Intuitive Teleoperation Framework for Robot Manipulators
Sep 22, 2023



Imitation learning from human demonstrations is a powerful framework to teach robots new skills. However, the performance of the learned policies is bottlenecked by the quality, scale, and variety of the demonstration data. In this paper, we aim to lower the barrier to collecting large and high-quality human demonstration data by proposing GELLO, a general framework for building low-cost and intuitive teleoperation systems for robotic manipulation. Given a target robot arm, we build a GELLO controller that has the same kinematic structure as the target arm, leveraging 3D-printed parts and off-the-shelf motors. GELLO is easy to build and intuitive to use. Through an extensive user study, we show that GELLO enables more reliable and efficient demonstration collection compared to commonly used teleoperation devices in the imitation learning literature such as VR controllers and 3D spacemouses. We further demonstrate the capabilities of GELLO for performing complex bi-manual and contact-rich manipulation tasks. To make GELLO accessible to everyone, we have designed and built GELLO systems for 3 commonly used robotic arms: Franka, UR5, and xArm. All software and hardware are open-sourced and can be found on our website: https://wuphilipp.github.io/gello/.
Autoregressive Uncertainty Modeling for 3D Bounding Box Prediction
Oct 13, 2022
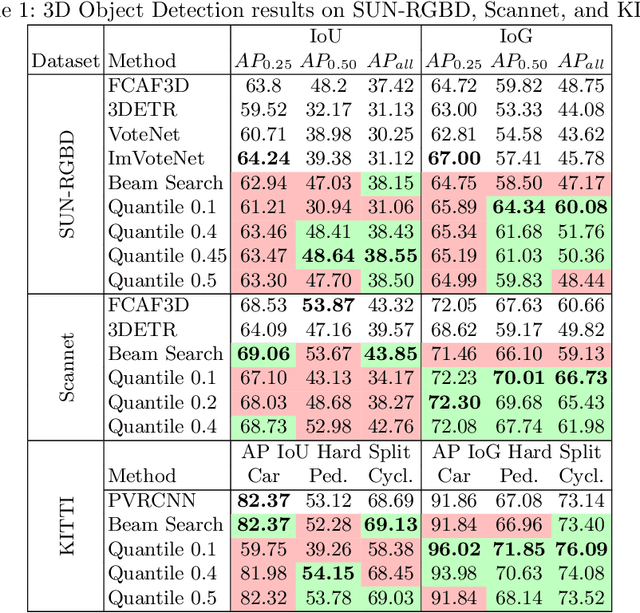
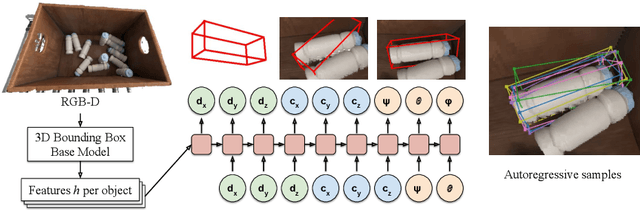
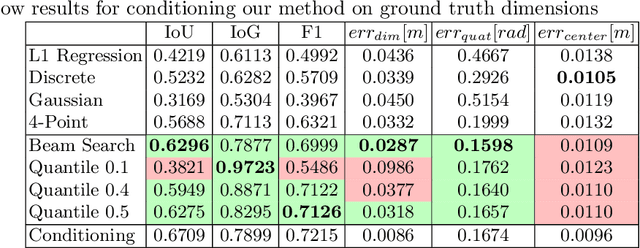
3D bounding boxes are a widespread intermediate representation in many computer vision applications. However, predicting them is a challenging task, largely due to partial observability, which motivates the need for a strong sense of uncertainty. While many recent methods have explored better architectures for consuming sparse and unstructured point cloud data, we hypothesize that there is room for improvement in the modeling of the output distribution and explore how this can be achieved using an autoregressive prediction head. Additionally, we release a simulated dataset, COB-3D, which highlights new types of ambiguity that arise in real-world robotics applications, where 3D bounding box prediction has largely been underexplored. We propose methods for leveraging our autoregressive model to make high confidence predictions and meaningful uncertainty measures, achieving strong results on SUN-RGBD, Scannet, KITTI, and our new dataset.
Learning Instance Segmentation by Interaction
Jun 21, 2018
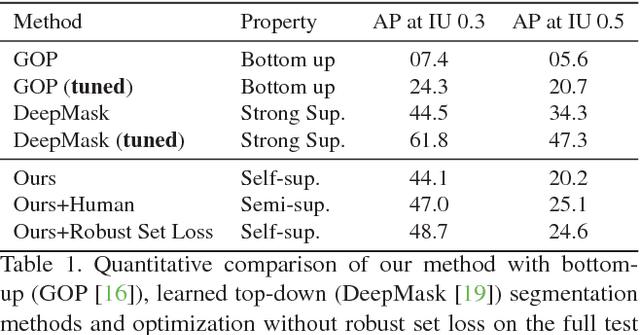
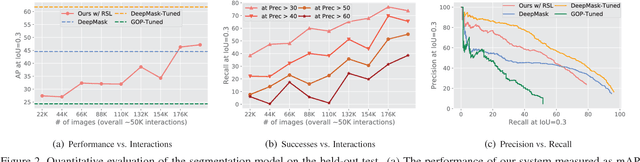
We present an approach for building an active agent that learns to segment its visual observations into individual objects by interacting with its environment in a completely self-supervised manner. The agent uses its current segmentation model to infer pixels that constitute objects and refines the segmentation model by interacting with these pixels. The model learned from over 50K interactions generalizes to novel objects and backgrounds. To deal with noisy training signal for segmenting objects obtained by self-supervised interactions, we propose robust set loss. A dataset of robot's interactions along-with a few human labeled examples is provided as a benchmark for future research. We test the utility of the learned segmentation model by providing results on a downstream vision-based control task of rearranging multiple objects into target configurations from visual inputs alone. Videos, code, and robotic interaction dataset are available at https://pathak22.github.io/seg-by-interaction/
Zero-Shot Visual Imitation
Apr 23, 2018



The current dominant paradigm for imitation learning relies on strong supervision of expert actions to learn both 'what' and 'how' to imitate. We pursue an alternative paradigm wherein an agent first explores the world without any expert supervision and then distills its experience into a goal-conditioned skill policy with a novel forward consistency loss. In our framework, the role of the expert is only to communicate the goals (i.e., what to imitate) during inference. The learned policy is then employed to mimic the expert (i.e., how to imitate) after seeing just a sequence of images demonstrating the desired task. Our method is 'zero-shot' in the sense that the agent never has access to expert actions during training or for the task demonstration at inference. We evaluate our zero-shot imitator in two real-world settings: complex rope manipulation with a Baxter robot and navigation in previously unseen office environments with a TurtleBot. Through further experiments in VizDoom simulation, we provide evidence that better mechanisms for exploration lead to learning a more capable policy which in turn improves end task performance. Videos, models, and more details are available at https://pathak22.github.io/zeroshot-imitation/