 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiGen: Using Multimodal Generation in Simulation to Learn Multimodal Policies in Real
Jul 03, 2025Robots must integrate multiple sensory modalities to act effectively in the real world. Yet, learning such multimodal policies at scale remains challenging. Simulation offers a viable solution, but while vision has benefited from high-fidelity simulators, other modalities (e.g. sound) can be notoriously difficult to simulate. As a result, sim-to-real transfer has succeeded primarily in vision-based tasks, with multimodal transfer still largely unrealized. In this work, we tackle these challenges by introducing MultiGen, a framework that integrates large-scale generative models into traditional physics simulators, enabling multisensory simulation. We showcase our framework on the dynamic task of robot pouring, which inherently relies on multimodal feedback. By synthesizing realistic audio conditioned on simulation video, our method enables training on rich audiovisual trajectories -- without any real robot data. We demonstrate effective zero-shot transfer to real-world pouring with novel containers and liquids, highlighting the potential of generative modeling to both simulate hard-to-model modalities and close the multimodal sim-to-real gap.
RoboCopilot: Human-in-the-loop Interactive Imitation Learning for Robot Manipulation
Mar 10, 2025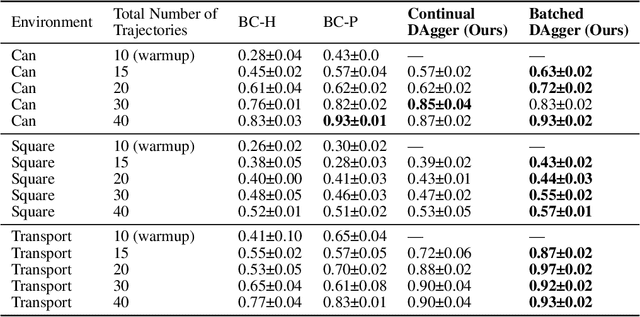
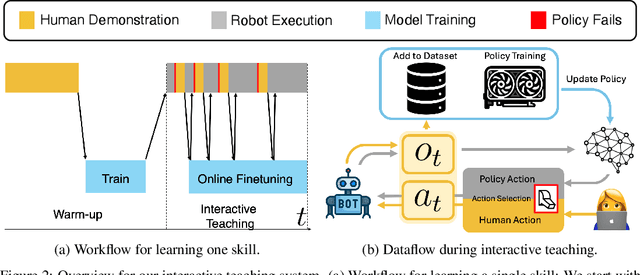
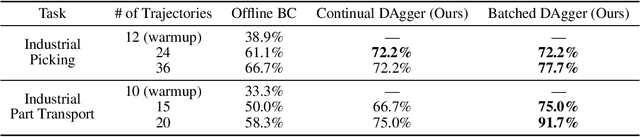
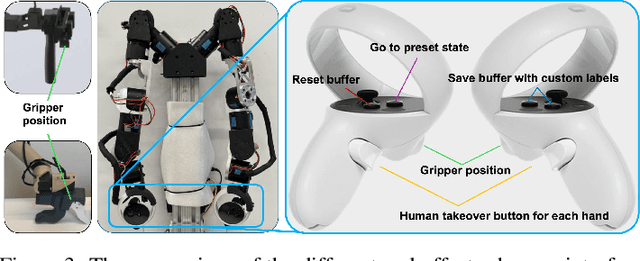
Learning from human demonstration is an effective approach for learning complex manipulation skills. However, existing approaches heavily focus on learning from passive human demonstration data for its simplicity in data collection. Interactive human teaching has appealing theoretical and practical properties, but they are not well supported by existing human-robot interfaces. This paper proposes a novel system that enables seamless control switching between human and an autonomous policy for bi-manual manipulation tasks, enabling more efficient learning of new tasks. This is achieved through a compliant, bilateral teleoperation system. Through simulation and hardware experiments, we demonstrate the value of our system in an interactive human teaching for learning complex bi-manual manipulation skills.
Semi-Supervised One-Shot Imitation Learning
Aug 09, 2024



One-shot Imitation Learning~(OSIL) aims to imbue AI agents with the ability to learn a new task from a single demonstration. To supervise the learning, OSIL typically requires a prohibitively large number of paired expert demonstrations -- i.e. trajectories corresponding to different variations of the same semantic task. To overcome this limitation, we introduce the semi-supervised OSIL problem setting, where the learning agent is presented with a large dataset of trajectories with no task labels (i.e. an unpaired dataset), along with a small dataset of multiple demonstrations per semantic task (i.e. a paired dataset). This presents a more realistic and practical embodiment of few-shot learning and requires the agent to effectively leverage weak supervision from a large dataset of trajectories. Subsequently, we develop an algorithm specifically applicable to this semi-supervised OSIL setting. Our approach first learns an embedding space where different tasks cluster uniquely. We utilize this embedding space and the clustering it supports to self-generate pairings between trajectories in the large unpaired dataset. Through empirical results on simulated control tasks, we demonstrate that OSIL models trained on such self-generated pairings are competitive with OSIL models trained with ground-truth labels, presenting a major advancement in the label-efficiency of OSIL.
From LLMs to Actions: Latent Codes as Bridges in Hierarchical Robot Control
May 08, 2024



Hierarchical control for robotics has long been plagued by the need to have a well defined interface layer to communicate between high-level task planners and low-level policies. With the advent of LLMs, language has been emerging as a prospective interface layer. However, this has several limitations. Not all tasks can be decomposed into steps that are easily expressible in natural language (e.g. performing a dance routine). Further, it makes end-to-end finetuning on embodied data challenging due to domain shift and catastrophic forgetting. We introduce our method -- Learnable Latent Codes as Bridges (LCB) -- as an alternate architecture to overcome these limitations. \method~uses a learnable latent code to act as a bridge between LLMs and low-level policies. This enables LLMs to flexibly communicate goals in the task plan without being entirely constrained by language limitations. Additionally, it enables end-to-end finetuning without destroying the embedding space of word tokens learned during pre-training. Through experiments on Language Table and Calvin, two common language based benchmarks for embodied agents, we find that \method~outperforms baselines (including those w/ GPT-4V) that leverage pure language as the interface layer on tasks that require reasoning and multi-step behaviors.
Interactive Task Planning with Language Models
Oct 16, 2023An interactive robot framework accomplishes long-horizon task planning and can easily generalize to new goals or distinct tasks, even during execution. However, most traditional methods require predefined module design, which makes it hard to generalize to different goals. Recent large language model based approaches can allow for more open-ended planning but often require heavy prompt engineering or domain-specific pretrained models. To tackle this, we propose a simple framework that achieves interactive task planning with language models. Our system incorporates both high-level planning and low-level function execution via language. We verify the robustness of our system in generating novel high-level instructions for unseen objectives and its ease of adaptation to different tasks by merely substituting the task guidelines, without the need for additional complex prompt engineering. Furthermore, when the user sends a new request, our system is able to replan accordingly with precision based on the new request, task guidelines and previously executed steps. Please check more details on our https://wuphilipp.github.io/itp_site and https://youtu.be/TrKLuyv26_g.
GELLO: A General, Low-Cost, and Intuitive Teleoperation Framework for Robot Manipulators
Sep 22, 2023



Imitation learning from human demonstrations is a powerful framework to teach robots new skills. However, the performance of the learned policies is bottlenecked by the quality, scale, and variety of the demonstration data. In this paper, we aim to lower the barrier to collecting large and high-quality human demonstration data by proposing GELLO, a general framework for building low-cost and intuitive teleoperation systems for robotic manipulation. Given a target robot arm, we build a GELLO controller that has the same kinematic structure as the target arm, leveraging 3D-printed parts and off-the-shelf motors. GELLO is easy to build and intuitive to use. Through an extensive user study, we show that GELLO enables more reliable and efficient demonstration collection compared to commonly used teleoperation devices in the imitation learning literature such as VR controllers and 3D spacemouses. We further demonstrate the capabilities of GELLO for performing complex bi-manual and contact-rich manipulation tasks. To make GELLO accessible to everyone, we have designed and built GELLO systems for 3 commonly used robotic arms: Franka, UR5, and xArm. All software and hardware are open-sourced and can be found on our website: https://wuphilipp.github.io/gello/.
Masked Trajectory Models for Prediction, Representation, and Control
May 04, 2023



We introduce Masked Trajectory Models (MTM) as a generic abstraction for sequential decision making. MTM takes a trajectory, such as a state-action sequence, and aims to reconstruct the trajectory conditioned on random subsets of the same trajectory. By training with a highly randomized masking pattern, MTM learns versatile networks that can take on different roles or capabilities, by simply choosing appropriate masks at inference time. For example, the same MTM network can be used as a forward dynamics model, inverse dynamics model, or even an offline RL agent. Through extensive experiments in several continuous control tasks, we show that the same MTM network -- i.e. same weights -- can match or outperform specialized networks trained for the aforementioned capabilities. Additionally, we find that state representations learned by MTM can significantly accelerate the learning speed of traditional RL algorithms. Finally, in offline RL benchmarks, we find that MTM is competitive with specialized offline RL algorithms, despite MTM being a generic self-supervised learning method without any explicit RL components. Code is available at https://github.com/facebookresearch/mtm
DayDreamer: World Models for Physical Robot Learning
Jun 28, 2022
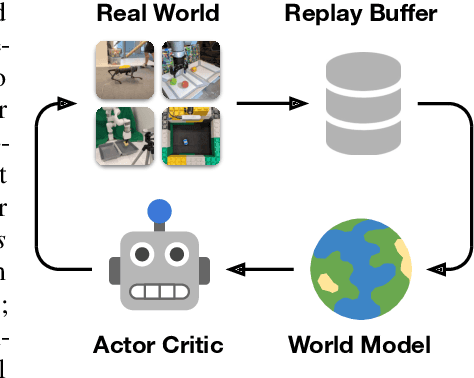
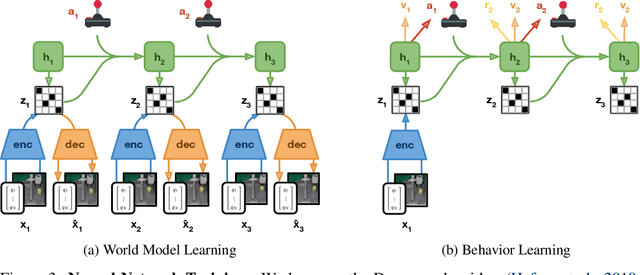

To solve tasks in complex environments, robots need to learn from experience. Deep reinforcement learning is a common approach to robot learning but requires a large amount of trial and error to learn, limiting its deployment in the physical world. As a consequence, many advances in robot learning rely on simulators. On the other hand, learning inside of simulators fails to capture the complexity of the real world, is prone to simulator inaccuracies, and the resulting behaviors do not adapt to changes in the world. The Dreamer algorithm has recently shown great promise for learning from small amounts of interaction by planning within a learned world model, outperforming pure reinforcement learning in video games. Learning a world model to predict the outcomes of potential actions enables planning in imagination, reducing the amount of trial and error needed in the real environment. However, it is unknown whether Dreamer can facilitate faster learning on physical robots. In this paper, we apply Dreamer to 4 robots to learn online and directly in the real world, without simulators. Dreamer trains a quadruped robot to roll off its back, stand up, and walk from scratch and without resets in only 1 hour. We then push the robot and find that Dreamer adapts within 10 minutes to withstand perturbations or quickly roll over and stand back up. On two different robotic arms, Dreamer learns to pick and place multiple objects directly from camera images and sparse rewards, approaching human performance. On a wheeled robot, Dreamer learns to navigate to a goal position purely from camera images, automatically resolving ambiguity about the robot orientation. Using the same hyperparameters across all experiments, we find that Dreamer is capable of online learning in the real world, establishing a strong baseline. We release our infrastructure for future applications of world models to robot learning.
Quasi-Direct Drive for Low-Cost Compliant Robotic Manipulation
Apr 11, 2019
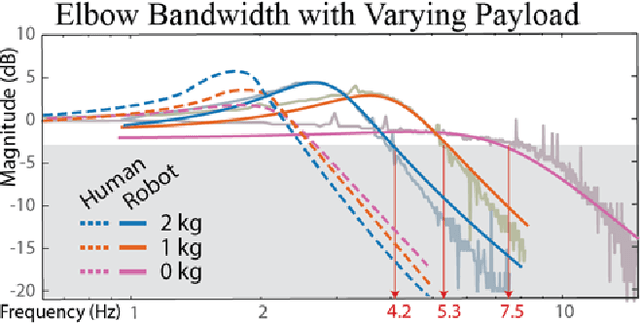


Robots must cost less and be force-controlled to enable widespread, safe deployment in unconstrained human environments. We propose Quasi-Direct Drive actuation as a capable paradigm for robotic force-controlled manipulation in human environments at low-cost. Our prototype - Blue - is a human scale 7 Degree of Freedom arm with 2kg payload. Blue can cost less than $5000. We show that Blue has dynamic properties that meet or exceed the needs of human operators: the robot has a nominal position-control bandwidth of 7.5Hz and repeatability within 4mm. We demonstrate a Virtual Reality based interface that can be used as a method for telepresence and collecting robot training demonstrations. Manufacturability, scaling, and potential use-cases for the Blue system are also addressed. Videos and additional information can be found online at berkeleyopenarms.github.io