 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised One-Shot Imitation Learning
Aug 09, 2024



One-shot Imitation Learning~(OSIL) aims to imbue AI agents with the ability to learn a new task from a single demonstration. To supervise the learning, OSIL typically requires a prohibitively large number of paired expert demonstrations -- i.e. trajectories corresponding to different variations of the same semantic task. To overcome this limitation, we introduce the semi-supervised OSIL problem setting, where the learning agent is presented with a large dataset of trajectories with no task labels (i.e. an unpaired dataset), along with a small dataset of multiple demonstrations per semantic task (i.e. a paired dataset). This presents a more realistic and practical embodiment of few-shot learning and requires the agent to effectively leverage weak supervision from a large dataset of trajectories. Subsequently, we develop an algorithm specifically applicable to this semi-supervised OSIL setting. Our approach first learns an embedding space where different tasks cluster uniquely. We utilize this embedding space and the clustering it supports to self-generate pairings between trajectories in the large unpaired dataset. Through empirical results on simulated control tasks, we demonstrate that OSIL models trained on such self-generated pairings are competitive with OSIL models trained with ground-truth labels, presenting a major advancement in the label-efficiency of OSIL.
Pretraining Graph Neural Networks for few-shot Analog Circuit Modeling and Design
Apr 01, 2022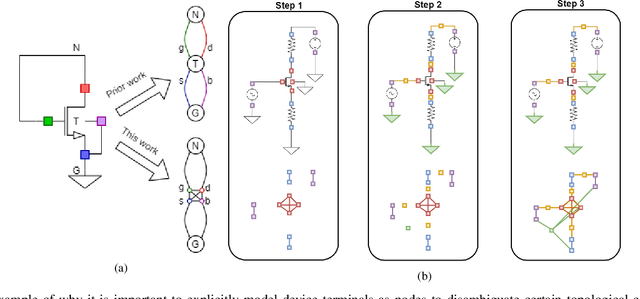
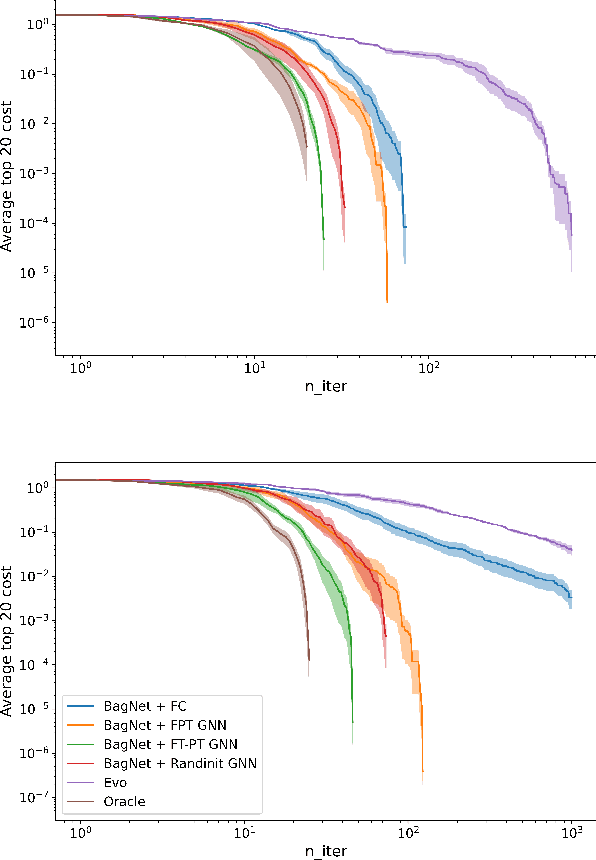

Being able to predict the performance of circuits without running expensive simulations is a desired capability that can catalyze automated design. In this paper, we present a supervised pretraining approach to learn circuit representations that can be adapted to new circuit topologies or unseen prediction tasks. We hypothesize that if we train a neural network (NN) that can predict the output DC voltages of a wide range of circuit instances it will be forced to learn generalizable knowledge about the role of each circuit element and how they interact with each other. The dataset for this supervised learning objective can be easily collected at scale since the required DC simulation to get ground truth labels is relatively cheap. This representation would then be helpful for few-shot generalization to unseen circuit metrics that require more time consuming simulations for obtaining the ground-truth labels. To cope with the variable topological structure of different circuits we describe each circuit as a graph and use graph neural networks (GNNs) to learn node embeddings. We show that pretraining GNNs on prediction of output node voltages can encourage learning representations that can be adapted to new unseen topologies or prediction of new circuit level properties with up to 10x more sample efficiency compared to a randomly initialized model. We further show that we can improve sample efficiency of prior SoTA model-based optimization methods by 2x (almost as good as using an oracle model) via fintuning pretrained GNNs as the feature extractor of the learned models.
Skill Preferences: Learning to Extract and Execute Robotic Skills from Human Feedback
Aug 11, 2021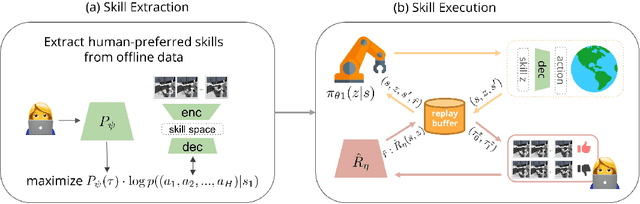
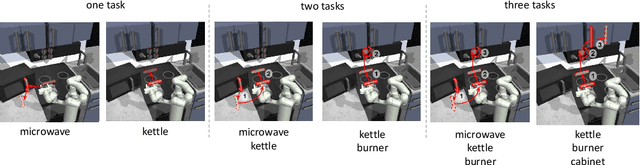
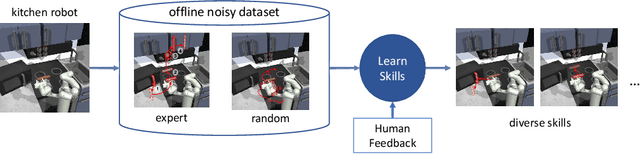
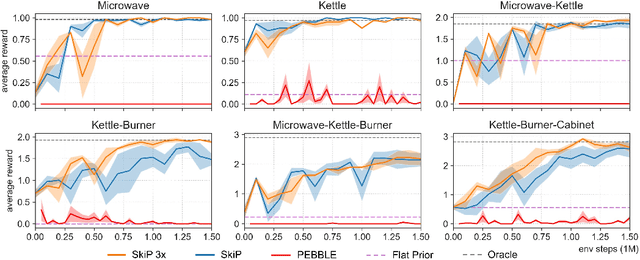
A promising approach to solving challenging long-horizon tasks has been to extract behavior priors (skills) by fitting generative models to large offline datasets of demonstrations. However, such generative models inherit the biases of the underlying data and result in poor and unusable skills when trained on imperfect demonstration data. To better align skill extraction with human intent we present Skill Preferences (SkiP), an algorithm that learns a model over human preferences and uses it to extract human-aligned skills from offline data. After extracting human-preferred skills, SkiP also utilizes human feedback to solve down-stream tasks with RL. We show that SkiP enables a simulated kitchen robot to solve complex multi-step manipulation tasks and substantially outperforms prior leading RL algorithms with human preferences as well as leading skill extraction algorithms without human preferences.
Hierarchical Few-Shot Imitation with Skill Transition Models
Jul 19, 2021
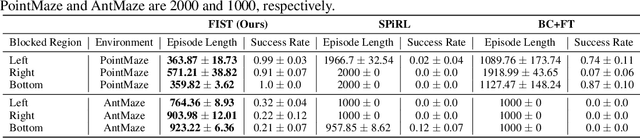
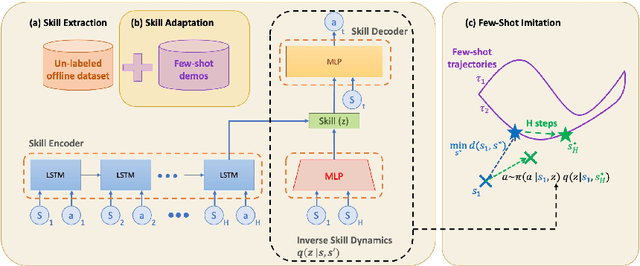

A desirable property of autonomous agents is the ability to both solve long-horizon problems and generalize to unseen tasks. Recent advances in data-driven skill learning have shown that extracting behavioral priors from offline data can enable agents to solve challenging long-horizon tasks with reinforcement learning. However, generalization to tasks unseen during behavioral prior training remains an outstanding challenge. To this end, we present Few-shot Imitation with Skill Transition Models (FIST), an algorithm that extracts skills from offline data and utilizes them to generalize to unseen tasks given a few downstream demonstrations. FIST learns an inverse skill dynamics model, a distance function, and utilizes a semi-parametric approach for imitation. We show that FIST is capable of generalizing to new tasks and substantially outperforms prior baselines in navigation experiments requiring traversing unseen parts of a large maze and 7-DoF robotic arm experiments requiring manipulating previously unseen objects in a kitchen.
JUMBO: Scalable Multi-task Bayesian Optimization using Offline Data
Jun 02, 2021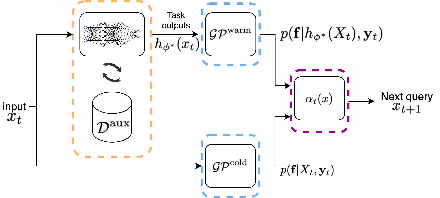

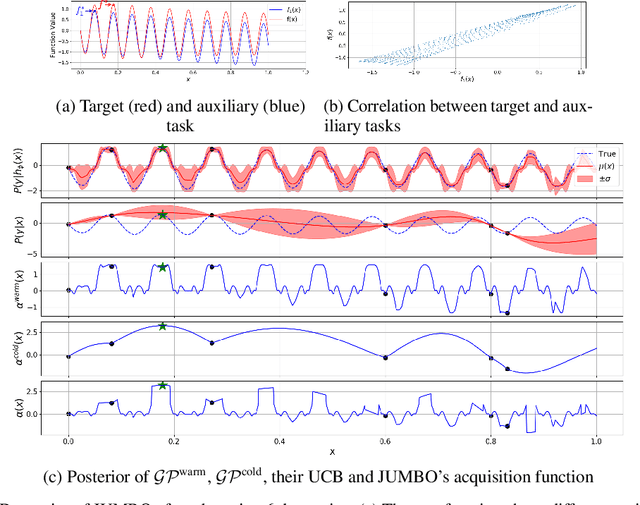
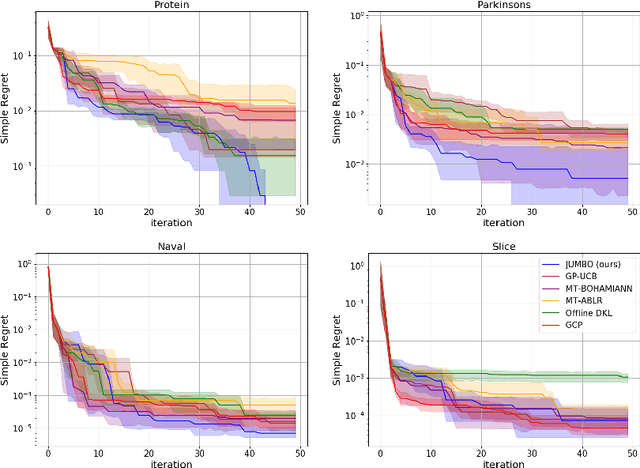
The goal of Multi-task Bayesian Optimization (MBO) is to minimize the number of queries required to accurately optimize a target black-box function, given access to offline evaluations of other auxiliary functions. When offline datasets are large, the scalability of prior approaches comes at the expense of expressivity and inference quality. We propose JUMBO, an MBO algorithm that sidesteps these limitations by querying additional data based on a combination of acquisition signals derived from training two Gaussian Processes (GP): a cold-GP operating directly in the input domain and a warm-GP that operates in the feature space of a deep neural network pretrained using the offline data. Such a decomposition can dynamically control the reliability of information derived from the online and offline data and the use of pretrained neural networks permits scalability to large offline datasets. Theoretically, we derive regret bounds for JUMBO and show that it achieves no-regret under conditions analogous to GP-UCB (Srinivas et. al. 2010). Empirically, we demonstrate significant performance improvements over existing approaches on two real-world optimization problems: hyper-parameter optimization and automated circuit design.
GACEM: Generalized Autoregressive Cross Entropy Method for Multi-Modal Black Box Constraint Satisfaction
Feb 17, 2020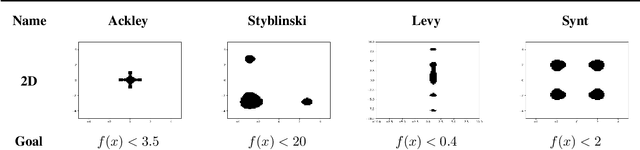
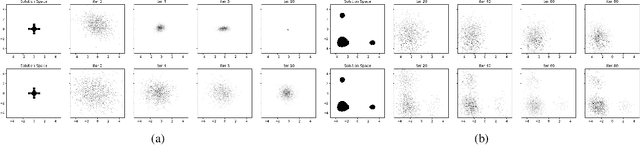
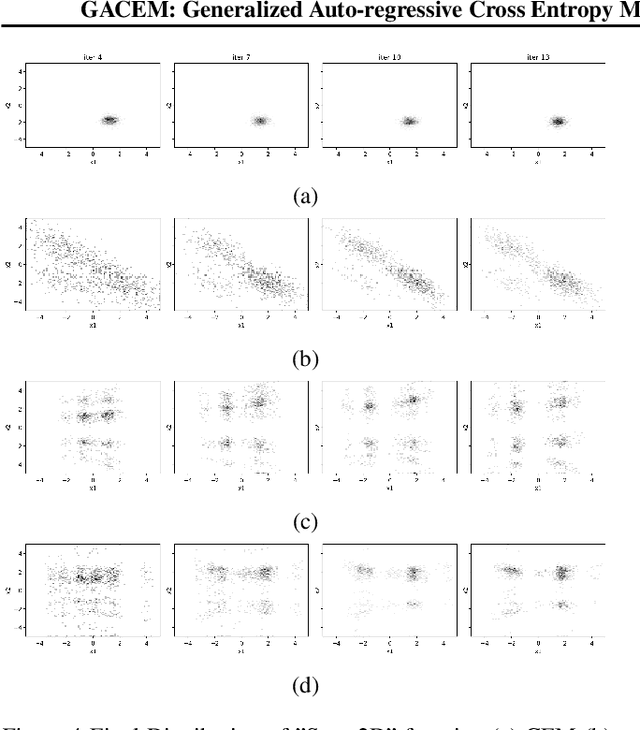
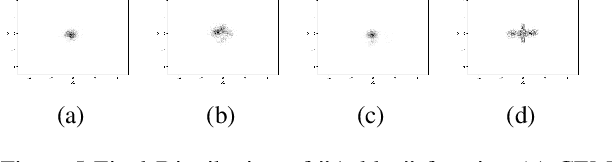
In this work we present a new method of black-box optimization and constraint satisfaction. Existing algorithms that have attempted to solve this problem are unable to consider multiple modes, and are not able to adapt to changes in environment dynamics. To address these issues, we developed a modified Cross-Entropy Method (CEM) that uses a masked auto-regressive neural network for modeling uniform distributions over the solution space. We train the model using maximum entropy policy gradient methods from Reinforcement Learning. Our algorithm is able to express complicated solution spaces, thus allowing it to track a variety of different solution regions. We empirically compare our algorithm with variations of CEM, including one with a Gaussian prior with fixed variance, and demonstrate better performance in terms of: number of diverse solutions, better mode discovery in multi-modal problems, and better sample efficiency in certain cases.
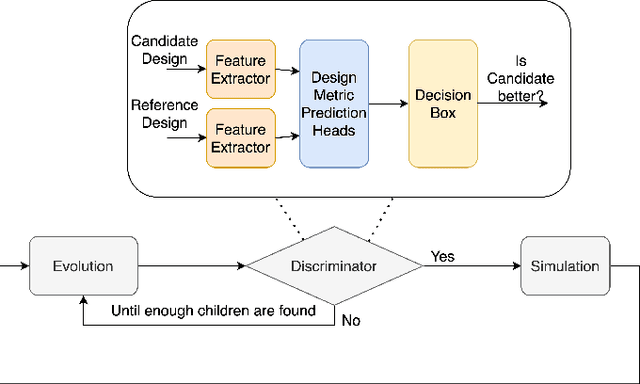
BagNet: Berkeley Analog Generator with Layout Optimizer Boosted with Deep Neural Networks
Jul 23, 2019
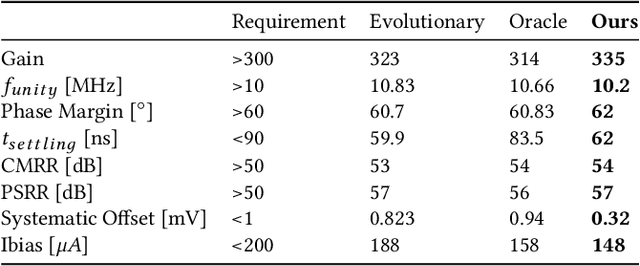
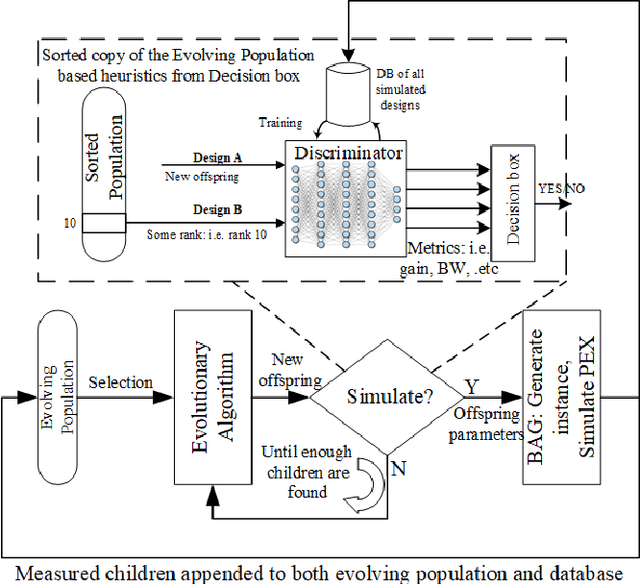

The discrepancy between post-layout and schematic simulation results continues to widen in analog design due in part to the domination of layout parasitics. This paradigm shift is forcing designers to adopt design methodologies that seamlessly integrate layout effects into the standard design flow. Hence, any simulation-based optimization framework should take into account time-consuming post-layout simulation results. This work presents a learning framework that learns to reduce the number of simulations of evolutionary-based combinatorial optimizers, using a DNN that discriminates against generated samples, before running simulations. Using this approach, the discriminator achieves at least two orders of magnitude improvement on sample efficiency for several large circuit examples including an optical link receiver layout.