 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturBench: Benchmarking Machine Learning Models for Cellular Perturbation Analysis
Aug 20, 2024



We present a comprehensive framework for predicting the effects of perturbations in single cells, designed to standardize benchmarking in this rapidly evolving field. Our framework, PerturBench, includes a user-friendly platform, diverse datasets, metrics for fair model comparison, and detailed performance analysis. Extensive evaluations of published and baseline models reveal limitations like mode or posterior collapse, and underscore the importance of rank metrics that assess the ordering of perturbations alongside traditional measures like RMSE. Our findings show that simple models can outperform more complex approaches. This benchmarking exercise sets new standards for model evaluation, supports robust model development, and advances the potential of these models to use high-throughput and high-content genetic and chemical screens for disease target discovery.
MatSciML: A Broad, Multi-Task Benchmark for Solid-State Materials Modeling
Sep 12, 2023



We propose MatSci ML, a novel benchmark for modeling MATerials SCIence using Machine Learning (MatSci ML) methods focused on solid-state materials with periodic crystal structures. Applying machine learning methods to solid-state materials is a nascent field with substantial fragmentation largely driven by the great variety of datasets used to develop machine learning models. This fragmentation makes comparing the performance and generalizability of different methods difficult, thereby hindering overall research progress in the field. Building on top of open-source datasets, including large-scale datasets like the OpenCatalyst, OQMD, NOMAD, the Carolina Materials Database, and Materials Project, the MatSci ML benchmark provides a diverse set of materials systems and properties data for model training and evaluation, including simulated energies, atomic forces, material bandgaps, as well as classification data for crystal symmetries via space groups. The diversity of properties in MatSci ML makes the implementation and evaluation of multi-task learning algorithms for solid-state materials possible, while the diversity of datasets facilitates the development of new, more generalized algorithms and methods across multiple datasets. In the multi-dataset learning setting, MatSci ML enables researchers to combine observations from multiple datasets to perform joint prediction of common properties, such as energy and forces. Using MatSci ML, we evaluate the performance of different graph neural networks and equivariant point cloud networks on several benchmark tasks spanning single task, multitask, and multi-data learning scenarios. Our open-source code is available at https://github.com/IntelLabs/matsciml.
The Open MatSci ML Toolkit: A Flexible Framework for Machine Learning in Materials Science
Oct 31, 2022



We present the Open MatSci ML Toolkit: a flexible, self-contained, and scalable Python-based framework to apply deep learning models and methods on scientific data with a specific focus on materials science and the OpenCatalyst Dataset. Our toolkit provides: 1. A scalable machine learning workflow for materials science leveraging PyTorch Lightning, which enables seamless scaling across different computation capabilities (laptop, server, cluster) and hardware platforms (CPU, GPU, XPU). 2. Deep Graph Library (DGL) support for rapid graph neural network prototyping and development. By publishing and sharing this toolkit with the research community via open-source release, we hope to: 1. Lower the entry barrier for new machine learning researchers and practitioners that want to get started with the OpenCatalyst dataset, which presently comprises the largest computational materials science dataset. 2. Enable the scientific community to apply advanced machine learning tools to high-impact scientific challenges, such as modeling of materials behavior for clean energy applications. We demonstrate the capabilities of our framework by enabling three new equivariant neural network models for multiple OpenCatalyst tasks and arrive at promising results for compute scaling and model performance.
Pretraining Graph Neural Networks for few-shot Analog Circuit Modeling and Design
Apr 01, 2022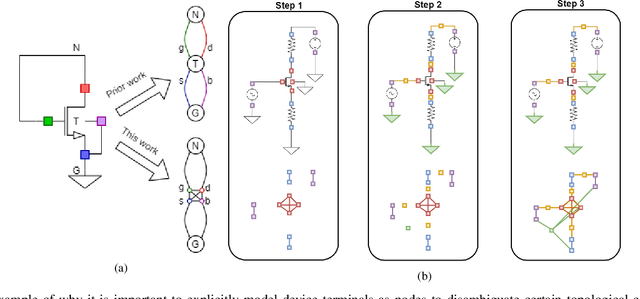
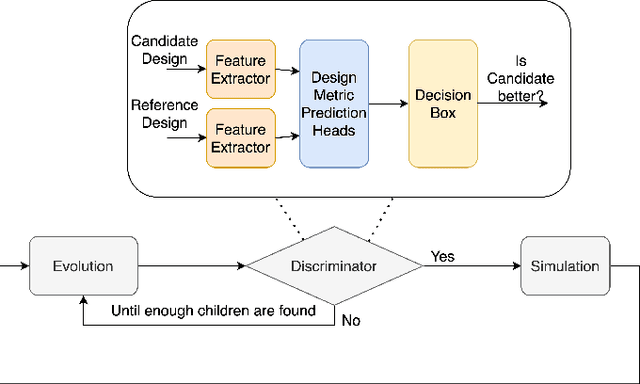
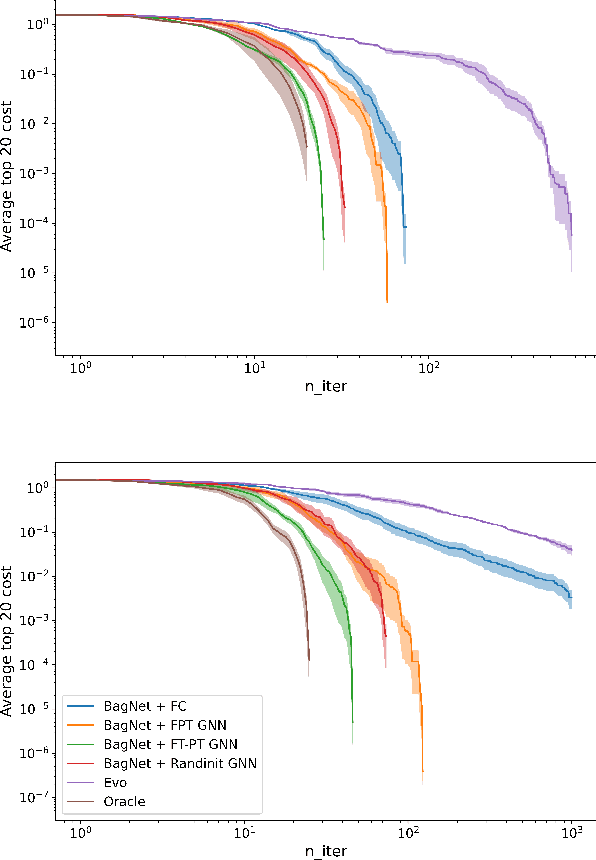

Being able to predict the performance of circuits without running expensive simulations is a desired capability that can catalyze automated design. In this paper, we present a supervised pretraining approach to learn circuit representations that can be adapted to new circuit topologies or unseen prediction tasks. We hypothesize that if we train a neural network (NN) that can predict the output DC voltages of a wide range of circuit instances it will be forced to learn generalizable knowledge about the role of each circuit element and how they interact with each other. The dataset for this supervised learning objective can be easily collected at scale since the required DC simulation to get ground truth labels is relatively cheap. This representation would then be helpful for few-shot generalization to unseen circuit metrics that require more time consuming simulations for obtaining the ground-truth labels. To cope with the variable topological structure of different circuits we describe each circuit as a graph and use graph neural networks (GNNs) to learn node embeddings. We show that pretraining GNNs on prediction of output node voltages can encourage learning representations that can be adapted to new unseen topologies or prediction of new circuit level properties with up to 10x more sample efficiency compared to a randomly initialized model. We further show that we can improve sample efficiency of prior SoTA model-based optimization methods by 2x (almost as good as using an oracle model) via fintuning pretrained GNNs as the feature extractor of the learned models.
Exploiting Long-Term Dependencies for Generating Dynamic Scene Graphs
Dec 18, 2021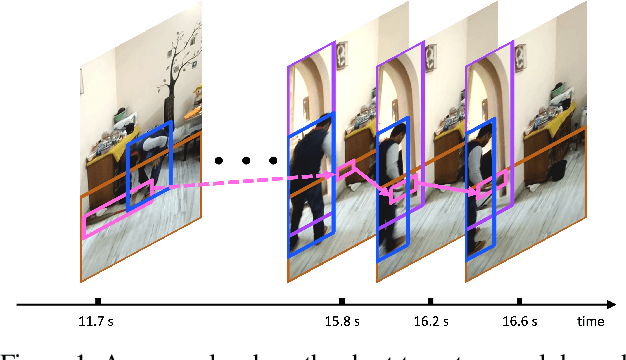
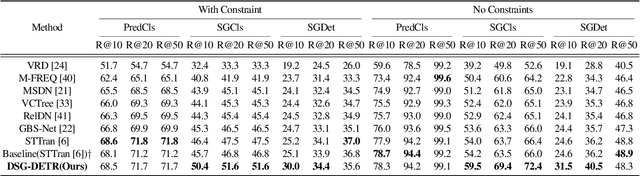
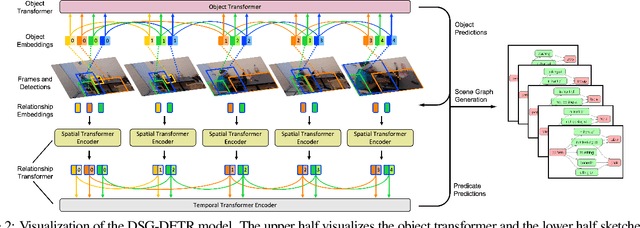
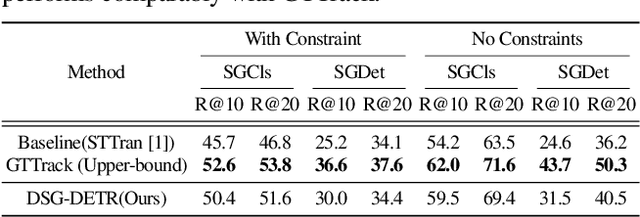
Structured video representation in the form of dynamic scene graphs is an effective tool for several video understanding tasks. Compared to the task of scene graph generation from images, dynamic scene graph generation is more challenging due to the temporal dynamics of the scene and the inherent temporal fluctuations of predictions. We show that capturing long-term dependencies is the key to effective generation of dynamic scene graphs. We present the detect-track-recognize paradigm by constructing consistent long-term object tracklets from a video, followed by transformers to capture the dynamics of objects and visual relations. Experimental results demonstrate that our Dynamic Scene Graph Detection Transformer (DSG-DETR) outperforms state-of-the-art methods by a significant margin on the benchmark dataset Action Genome. We also perform ablation studies and validate the effectiveness of each component of the proposed approach.
Implicit SVD for Graph Representation Learning
Nov 11, 2021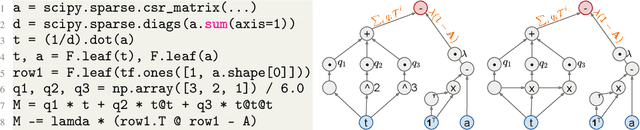
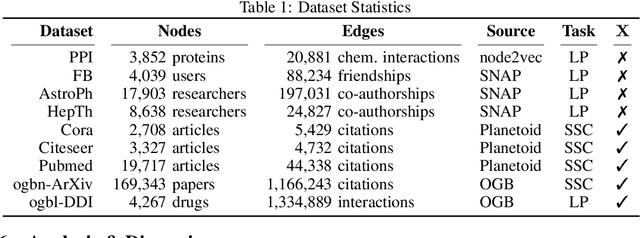
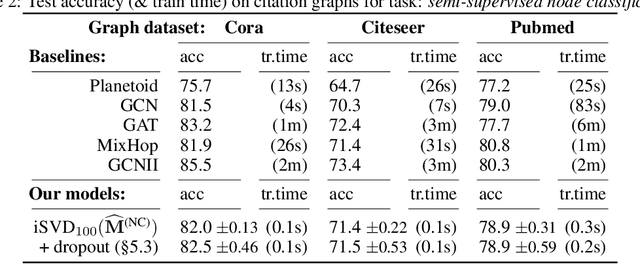
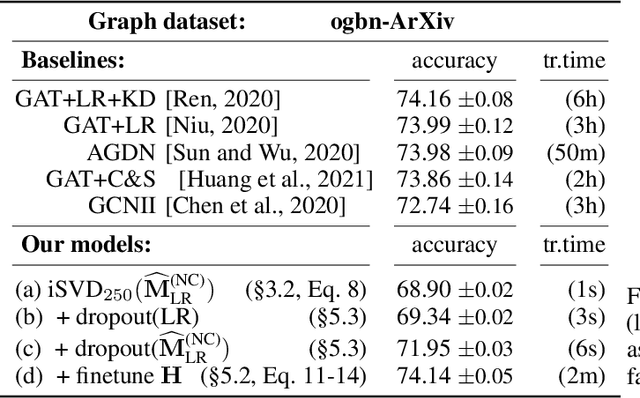
Recent improvements in the performance of state-of-the-art (SOTA) methods for Graph Representational Learning (GRL) have come at the cost of significant computational resource requirements for training, e.g., for calculating gradients via backprop over many data epochs. Meanwhile, Singular Value Decomposition (SVD) can find closed-form solutions to convex problems, using merely a handful of epochs. In this paper, we make GRL more computationally tractable for those with modest hardware. We design a framework that computes SVD of \textit{implicitly} defined matrices, and apply this framework to several GRL tasks. For each task, we derive linear approximation of a SOTA model, where we design (expensive-to-store) matrix $\mathbf{M}$ and train the model, in closed-form, via SVD of $\mathbf{M}$, without calculating entries of $\mathbf{M}$. By converging to a unique point in one step, and without calculating gradients, our models show competitive empirical test performance over various graphs such as article citation and biological interaction networks. More importantly, SVD can initialize a deeper model, that is architected to be non-linear almost everywhere, though behaves linearly when its parameters reside on a hyperplane, onto which SVD initializes. The deeper model can then be fine-tuned within only a few epochs. Overall, our procedure trains hundreds of times faster than state-of-the-art methods, while competing on empirical test performance. We open-source our implementation at: https://github.com/samihaija/isvd
On Local Aggregation in Heterophilic Graphs
Jun 06, 2021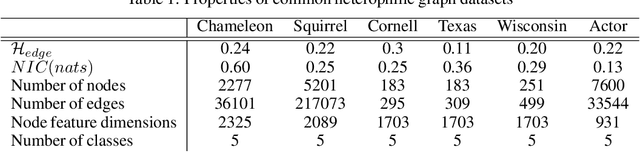
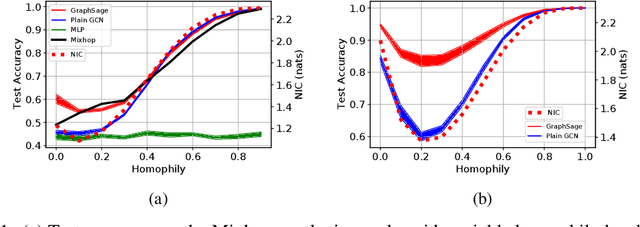
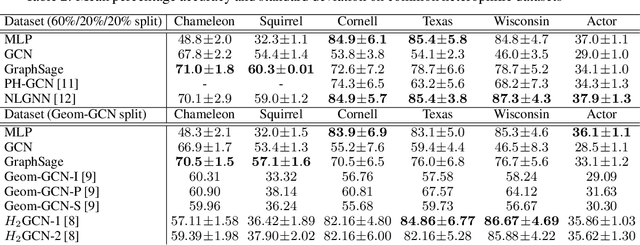
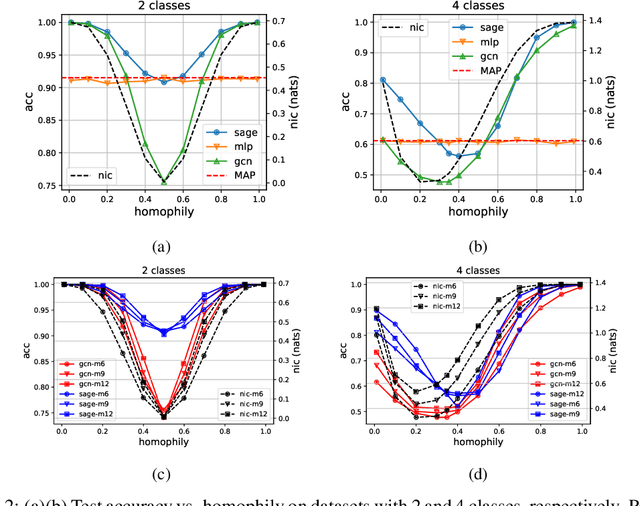
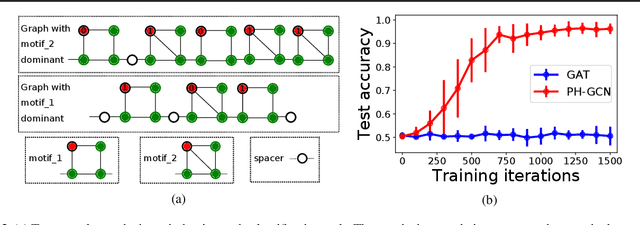
Many recent works have studied the performance of Graph Neural Networks (GNNs) in the context of graph homophily - a label-dependent measure of connectivity. Traditional GNNs generate node embeddings by aggregating information from a node's neighbors in the graph. Recent results in node classification tasks show that this local aggregation approach performs poorly in graphs with low homophily (heterophilic graphs). Several mechanisms have been proposed to improve the accuracy of GNNs on such graphs by increasing the aggregation range of a GNN layer, either through multi-hop aggregation, or through long-range aggregation from distant nodes. In this paper, we show that properly tuned classical GNNs and multi-layer perceptrons match or exceed the accuracy of recent long-range aggregation methods on heterophilic graphs. Thus, our results highlight the need for alternative datasets to benchmark long-range GNN aggregation mechanisms. We also show that homophily is a poor measure of the information in a node's local neighborhood and propose the Neighborhood Information Content(NIC) metric, which is a novel information-theoretic graph metric. We argue that NIC is more relevant for local aggregation methods as used by GNNs. We show that, empirically, it correlates better with GNN accuracy in node classification tasks than homophily.
Structured Citation Trend Prediction Using Graph Neural Networks
Apr 06, 2021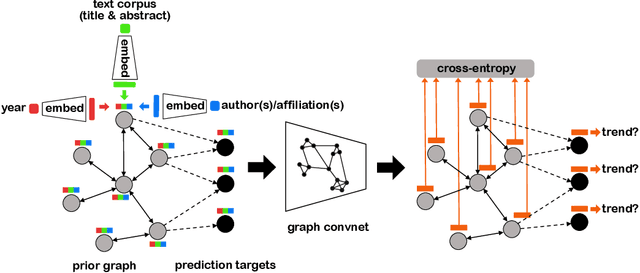
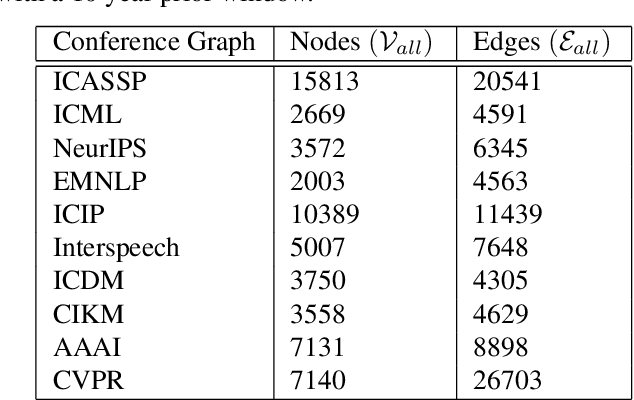
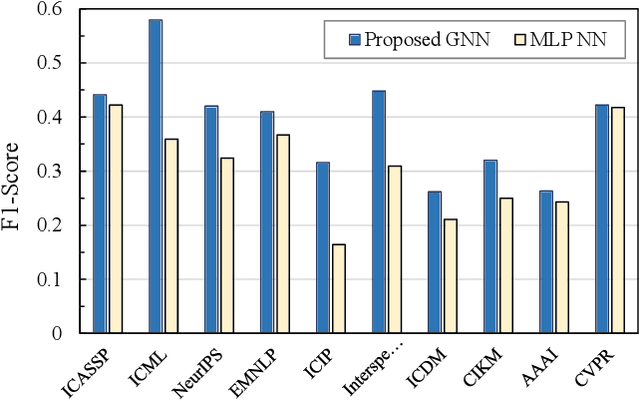

Academic citation graphs represent citation relationships between publications across the full range of academic fields. Top cited papers typically reveal future trends in their corresponding domains which is of importance to both researchers and practitioners. Prior citation prediction methods often require initial citation trends to be established and do not take advantage of the recent advancements in graph neural networks (GNNs). We present GNN-based architecture that predicts the top set of papers at the time of publication. For experiments, we curate a set of academic citation graphs for a variety of conferences and show that the proposed model outperforms other classic machine learning models in terms of the F1-score.
Permutohedral-GCN: Graph Convolutional Networks with Global Attention
Mar 02, 2020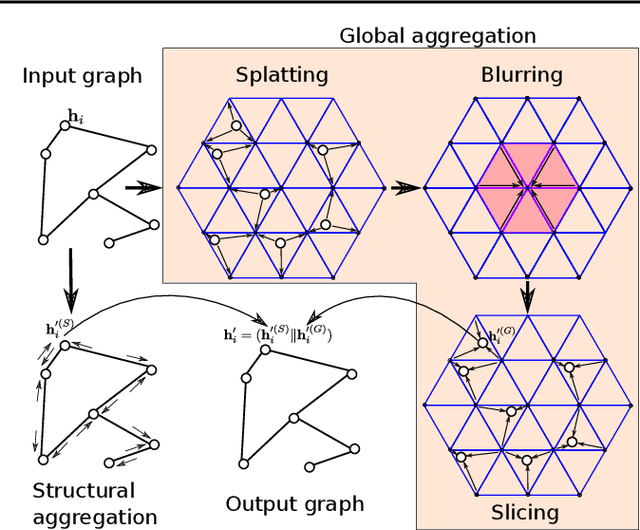

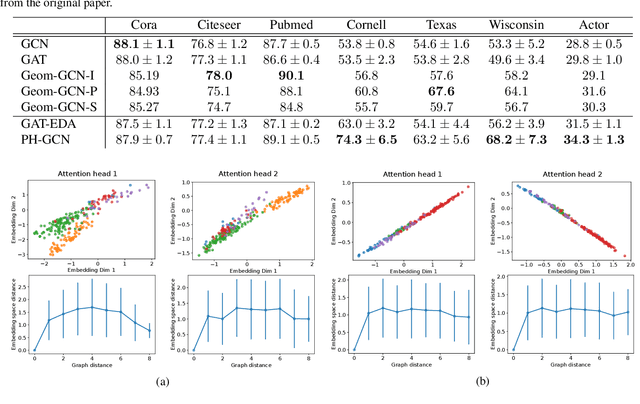
Graph convolutional networks (GCNs) update a node's feature vector by aggregating features from its neighbors in the graph. This ignores potentially useful contributions from distant nodes. Identifying such useful distant contributions is challenging due to scalability issues (too many nodes can potentially contribute) and oversmoothing (aggregating features from too many nodes risks swamping out relevant information and may result in nodes having different labels but indistinguishable features). We introduce a global attention mechanism where a node can selectively attend to, and aggregate features from, any other node in the graph. The attention coefficients depend on the Euclidean distance between learnable node embeddings, and we show that the resulting attention-based global aggregation scheme is analogous to high-dimensional Gaussian filtering. This makes it possible to use efficient approximate Gaussian filtering techniques to implement our attention-based global aggregation scheme. By employing an approximate filtering method based on the permutohedral lattice, the time complexity of our proposed global aggregation scheme only grows linearly with the number of nodes. The resulting GCNs, which we term permutohedral-GCNs, are differentiable and trained end-to-end, and they achieve state of the art performance on several node classification benchmarks.
Hierarchical Bipartite Graph Convolution Networks
Dec 13, 2018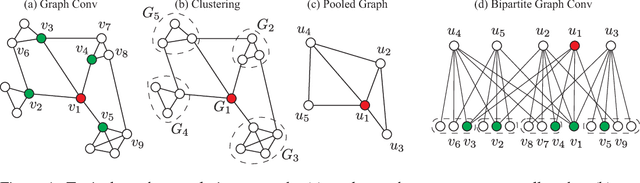
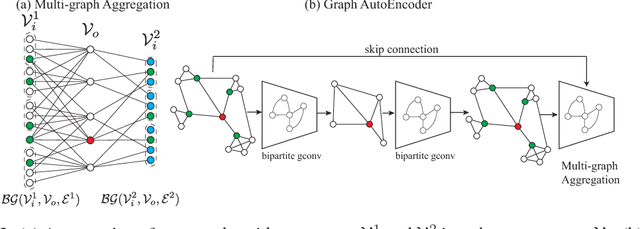

Recently, graph neural networks have been adopted in a wide variety of applications ranging from relational representations to modeling irregular data domains such as point clouds and social graphs. However, the space of graph neural network architectures remains highly fragmented impeding the development of optimized implementations similar to what is available for convolutional neural networks. In this work, we present BiGraphNet, a graph neural network architecture that generalizes many popular graph neural network models and enables new efficient operations similar to those supported by ConvNets. By explicitly separating the input and output nodes, BiGraphNet: (i) generalizes the graph convolution to support new efficient operations such as coarsened graph convolutions (similar to strided convolution in convnets), multiple input graphs convolution and graph expansions (unpooling) which can be used to implement various graph architectures such as graph autoencoders, and graph residual nets; and (ii) accelerates and scales the computations and memory requirements in hierarchical networks by performing computations only at specified output nodes.