 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFloorSet -- a VLSI Floorplanning Dataset with Design Constraints of Real-World SoCs
May 09, 2024



Floorplanning for systems-on-a-chip (SoCs) and its sub-systems is a crucial and non-trivial step of the physical design flow. It represents a difficult combinatorial optimization problem. A typical large scale SoC with 120 partitions generates a search-space of nearly 10E250. As novel machine learning (ML) approaches emerge to tackle such problems, there is a growing need for a modern benchmark that comprises a large training dataset and performance metrics that better reflect real-world constraints and objectives compared to existing benchmarks. To address this need, we present FloorSet -- two comprehensive datasets of synthetic fixed-outline floorplan layouts that reflect the distribution of real SoCs. Each dataset has 1M training samples and 100 test samples where each sample is a synthetic floor-plan. FloorSet-Prime comprises fully-abutted rectilinear partitions and near-optimal wire-length. A simplified dataset that reflects early design phases, FloorSet-Lite comprises rectangular partitions, with under 5 percent white-space and near-optimal wire-length. Both datasets define hard constraints seen in modern design flows such as shape constraints, edge-affinity, grouping constraints, and pre-placement constraints. FloorSet is intended to spur fundamental research on large-scale constrained optimization problems. Crucially, FloorSet alleviates the core issue of reproducibility in modern ML driven solutions to such problems. FloorSet is available as an open-source repository for the research community.
Learning Long-Term Spatial-Temporal Graphs for Active Speaker Detection
Jul 19, 2022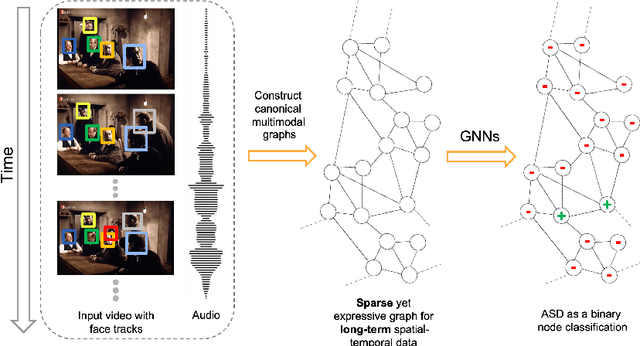

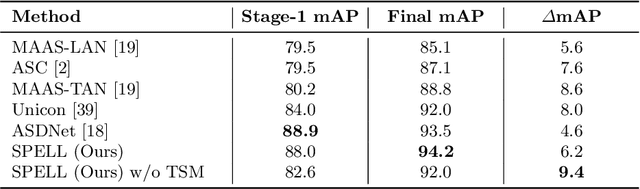
Active speaker detection (ASD) in videos with multiple speakers is a challenging task as it requires learning effective audiovisual features and spatial-temporal correlations over long temporal windows. In this paper, we present SPELL, a novel spatial-temporal graph learning framework that can solve complex tasks such as ASD. To this end, each person in a video frame is first encoded in a unique node for that frame. Nodes corresponding to a single person across frames are connected to encode their temporal dynamics. Nodes within a frame are also connected to encode inter-person relationships. Thus, SPELL reduces ASD to a node classification task. Importantly, SPELL is able to reason over long temporal contexts for all nodes without relying on computationally expensive fully connected graph neural networks. Through extensive experiments on the AVA-ActiveSpeaker dataset, we demonstrate that learning graph-based representations can significantly improve the active speaker detection performance owing to its explicit spatial and temporal structure. SPELL outperforms all previous state-of-the-art approaches while requiring significantly lower memory and computational resources. Our code is publicly available at https://github.com/SRA2/SPELL
Joint Hand Motion and Interaction Hotspots Prediction from Egocentric Videos
Apr 04, 2022
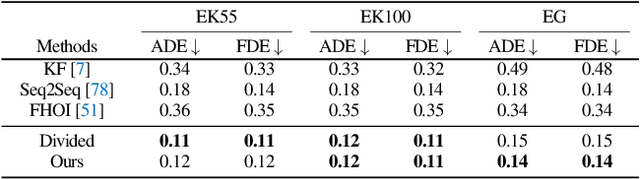


We propose to forecast future hand-object interactions given an egocentric video. Instead of predicting action labels or pixels, we directly predict the hand motion trajectory and the future contact points on the next active object (i.e., interaction hotspots). This relatively low-dimensional representation provides a concrete description of future interactions. To tackle this task, we first provide an automatic way to collect trajectory and hotspots labels on large-scale data. We then use this data to train an Object-Centric Transformer (OCT) model for prediction. Our model performs hand and object interaction reasoning via the self-attention mechanism in Transformers. OCT also provides a probabilistic framework to sample the future trajectory and hotspots to handle uncertainty in prediction. We perform experiments on the Epic-Kitchens-55, Epic-Kitchens-100, and EGTEA Gaze+ datasets, and show that OCT significantly outperforms state-of-the-art approaches by a large margin. Project page is available at https://stevenlsw.github.io/hoi-forecast .
Exploiting Long-Term Dependencies for Generating Dynamic Scene Graphs
Dec 18, 2021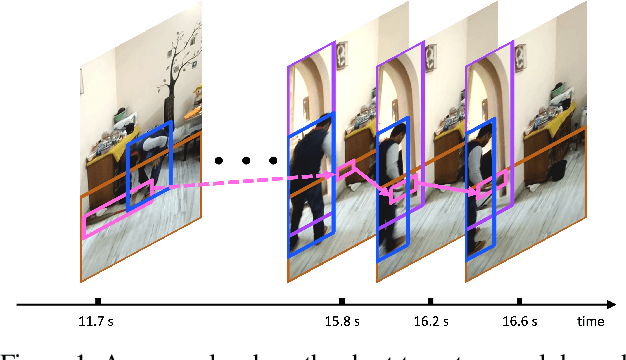
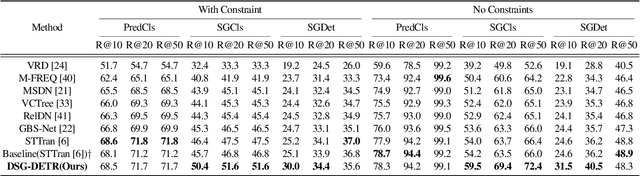
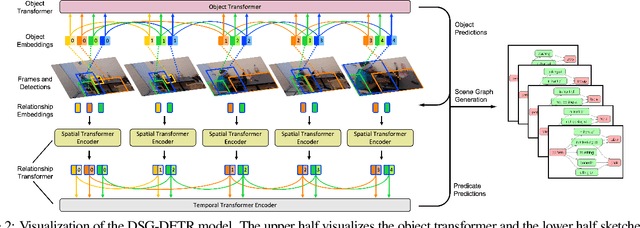
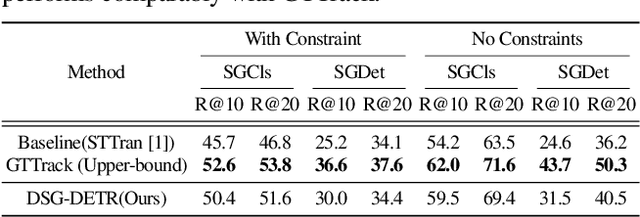
Structured video representation in the form of dynamic scene graphs is an effective tool for several video understanding tasks. Compared to the task of scene graph generation from images, dynamic scene graph generation is more challenging due to the temporal dynamics of the scene and the inherent temporal fluctuations of predictions. We show that capturing long-term dependencies is the key to effective generation of dynamic scene graphs. We present the detect-track-recognize paradigm by constructing consistent long-term object tracklets from a video, followed by transformers to capture the dynamics of objects and visual relations. Experimental results demonstrate that our Dynamic Scene Graph Detection Transformer (DSG-DETR) outperforms state-of-the-art methods by a significant margin on the benchmark dataset Action Genome. We also perform ablation studies and validate the effectiveness of each component of the proposed approach.
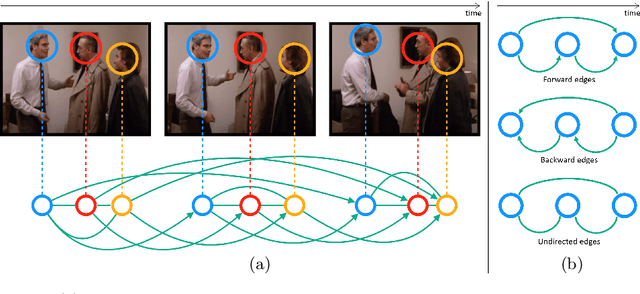
Learning Spatial-Temporal Graphs for Active Speaker Detection
Dec 03, 2021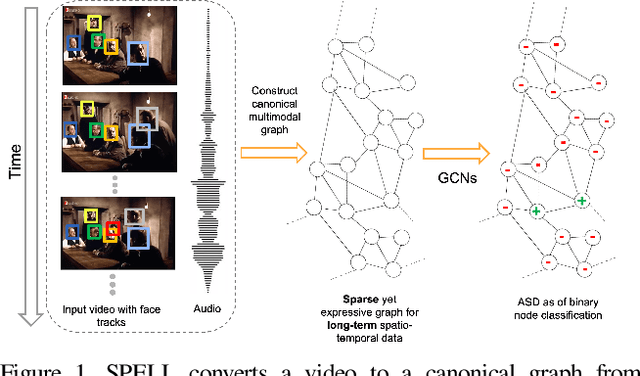
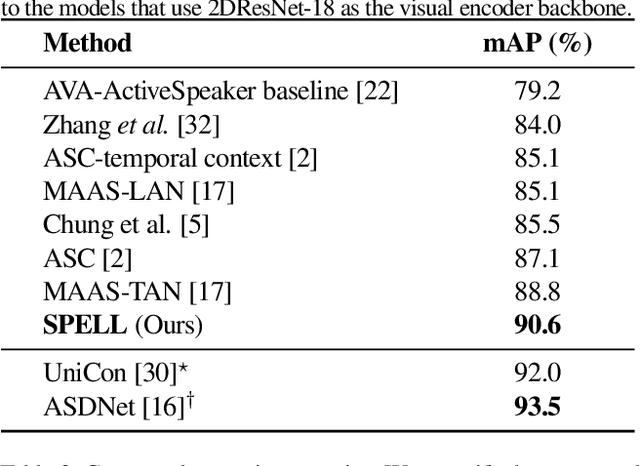
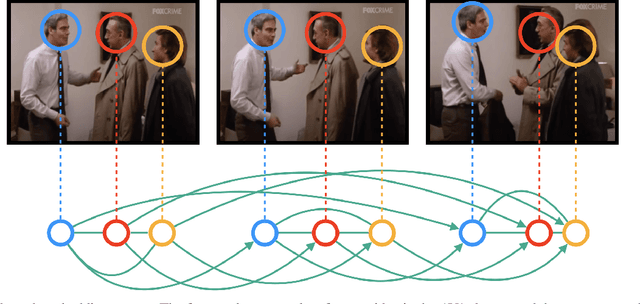
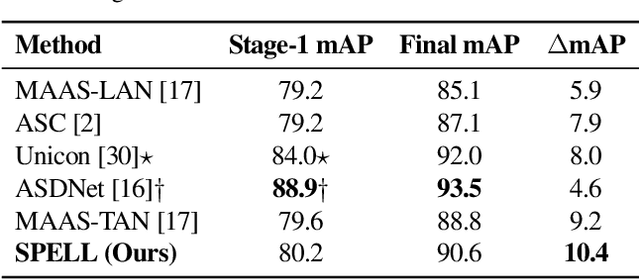
We address the problem of active speaker detection through a new framework, called SPELL, that learns long-range multimodal graphs to encode the inter-modal relationship between audio and visual data. We cast active speaker detection as a node classification task that is aware of longer-term dependencies. We first construct a graph from a video so that each node corresponds to one person. Nodes representing the same identity share edges between them within a defined temporal window. Nodes within the same video frame are also connected to encode inter-person interactions. Through extensive experiments on the Ava-ActiveSpeaker dataset, we demonstrate that learning graph-based representation, owing to its explicit spatial and temporal structure, significantly improves the overall performance. SPELL outperforms several relevant baselines and performs at par with state of the art models while requiring an order of magnitude lower computation cost.
Minimizing Communication while Maximizing Performance in Multi-Agent Reinforcement Learning
Jun 18, 2021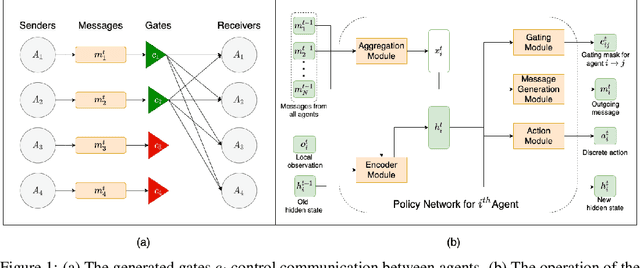

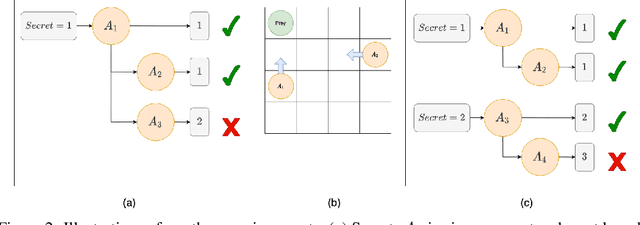
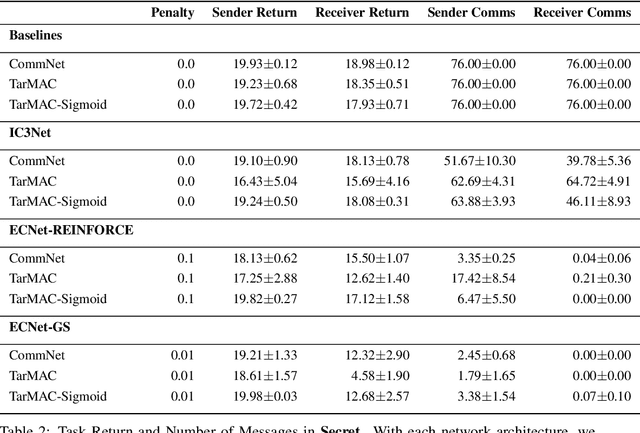
Inter-agent communication can significantly increase performance in multi-agent tasks that require co-ordination to achieve a shared goal. Prior work has shown that it is possible to learn inter-agent communication protocols using multi-agent reinforcement learning and message-passing network architectures. However, these models use an unconstrained broadcast communication model, in which an agent communicates with all other agents at every step, even when the task does not require it. In real-world applications, where communication may be limited by system constraints like bandwidth, power and network capacity, one might need to reduce the number of messages that are sent. In this work, we explore a simple method of minimizing communication while maximizing performance in multi-task learning: simultaneously optimizing a task-specific objective and a communication penalty. We show that the objectives can be optimized using Reinforce and the Gumbel-Softmax reparameterization. We introduce two techniques to stabilize training: 50% training and message forwarding. Training with the communication penalty on only 50% of the episodes prevents our models from turning off their outgoing messages. Second, repeating messages received previously helps models retain information, and further improves performance. With these techniques, we show that we can reduce communication by 75% with no loss of performance.
Neuroevolution-Enhanced Multi-Objective Optimization for Mixed-Precision Quantization
Jun 14, 2021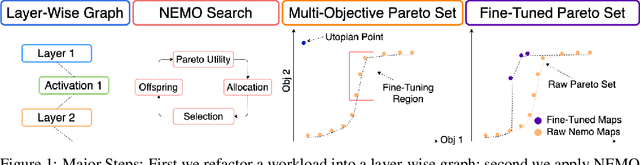
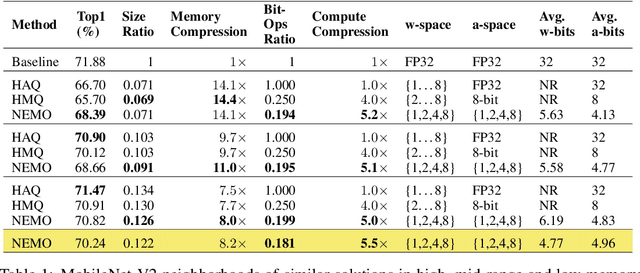
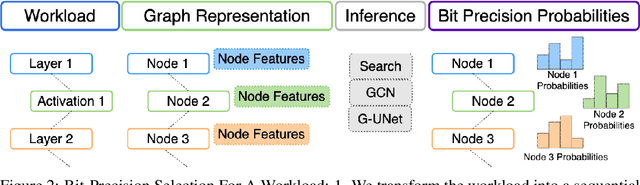
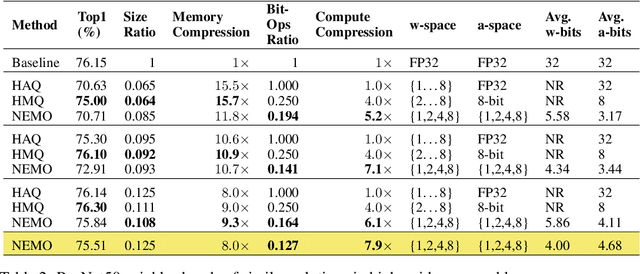
Mixed-precision quantization is a powerful tool to enable memory and compute savings of neural network workloads by deploying different sets of bit-width precisions on separate compute operations. Recent research has shown significant progress in applying mixed-precision quantization techniques to reduce the memory footprint of various workloads, while also preserving task performance. Prior work, however, has often ignored additional objectives, such as bit-operations, that are important for deployment of workloads on hardware. Here we present a flexible and scalable framework for automated mixed-precision quantization that optimizes multiple objectives. Our framework relies on Neuroevolution-Enhanced Multi-Objective Optimization (NEMO), a novel search method, to find Pareto optimal mixed-precision configurations for memory and bit-operations objectives. Within NEMO, a population is divided into structurally distinct sub-populations (species) which jointly form the Pareto frontier of solutions for the multi-objective problem. At each generation, species are re-sized in proportion to the goodness of their contribution to the Pareto frontier. This allows NEMO to leverage established search techniques and neuroevolution methods to continually improve the goodness of the Pareto frontier. In our experiments we apply a graph-based representation to describe the underlying workload, enabling us to deploy graph neural networks trained by NEMO to find Pareto optimal configurations for various workloads trained on ImageNet. Compared to the state-of-the-art, we achieve competitive results on memory compression and superior results for compute compression for MobileNet-V2, ResNet50 and ResNeXt-101-32x8d. A deeper analysis of the results obtained by NEMO also shows that both the graph representation and the species-based approach are critical in finding effective configurations for all workloads.
On Local Aggregation in Heterophilic Graphs
Jun 06, 2021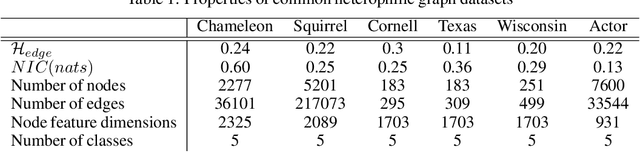
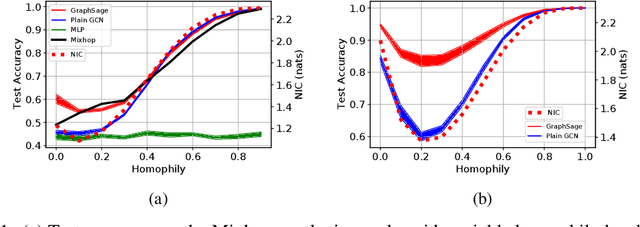
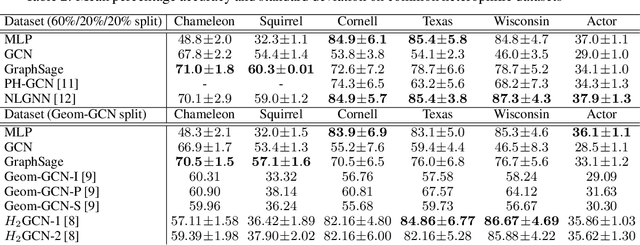
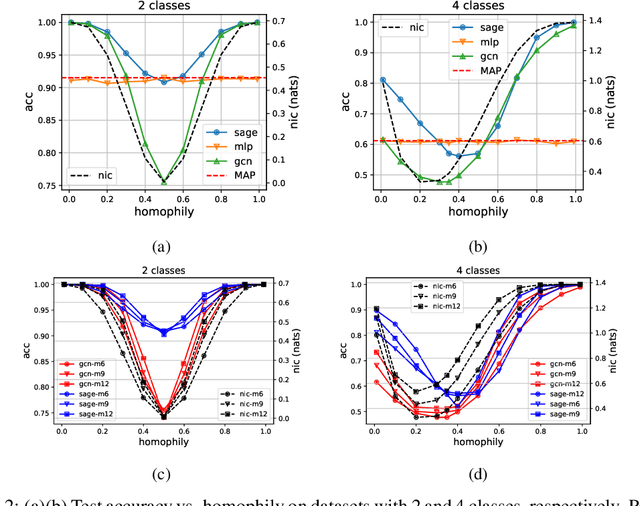
Many recent works have studied the performance of Graph Neural Networks (GNNs) in the context of graph homophily - a label-dependent measure of connectivity. Traditional GNNs generate node embeddings by aggregating information from a node's neighbors in the graph. Recent results in node classification tasks show that this local aggregation approach performs poorly in graphs with low homophily (heterophilic graphs). Several mechanisms have been proposed to improve the accuracy of GNNs on such graphs by increasing the aggregation range of a GNN layer, either through multi-hop aggregation, or through long-range aggregation from distant nodes. In this paper, we show that properly tuned classical GNNs and multi-layer perceptrons match or exceed the accuracy of recent long-range aggregation methods on heterophilic graphs. Thus, our results highlight the need for alternative datasets to benchmark long-range GNN aggregation mechanisms. We also show that homophily is a poor measure of the information in a node's local neighborhood and propose the Neighborhood Information Content(NIC) metric, which is a novel information-theoretic graph metric. We argue that NIC is more relevant for local aggregation methods as used by GNNs. We show that, empirically, it correlates better with GNN accuracy in node classification tasks than homophily.
Dream and Search to Control: Latent Space Planning for Continuous Control
Oct 19, 2020
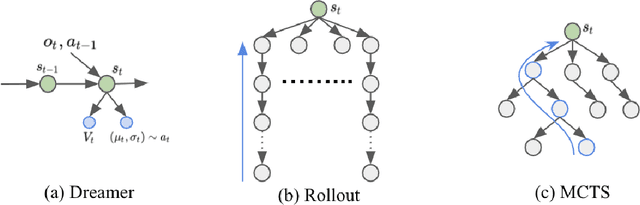
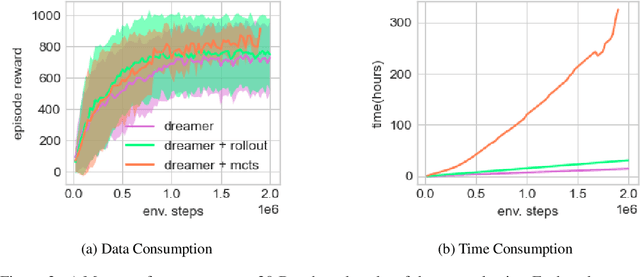
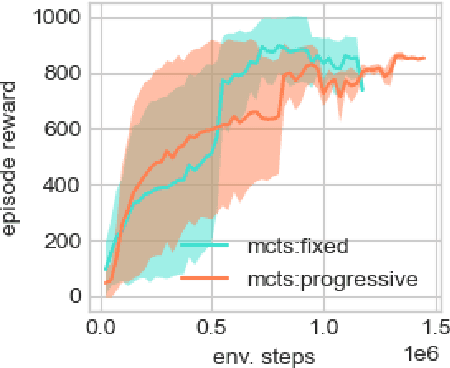
Learning and planning with latent space dynamics has been shown to be useful for sample efficiency in model-based reinforcement learning (MBRL) for discrete and continuous control tasks. In particular, recent work, for discrete action spaces, demonstrated the effectiveness of latent-space planning via Monte-Carlo Tree Search (MCTS) for bootstrapping MBRL during learning and at test time. However, the potential gains from latent-space tree search have not yet been demonstrated for environments with continuous action spaces. In this work, we propose and explore an MBRL approach for continuous action spaces based on tree-based planning over learned latent dynamics. We show that it is possible to demonstrate the types of bootstrapping benefits as previously shown for discrete spaces. In particular, the approach achieves improved sample efficiency and performance on a majority of challenging continuous-control benchmarks compared to the state-of-the-art.
Learning Intrinsic Symbolic Rewards in Reinforcement Learning
Oct 09, 2020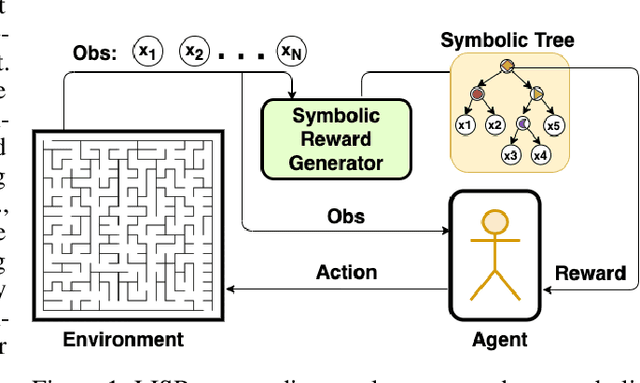
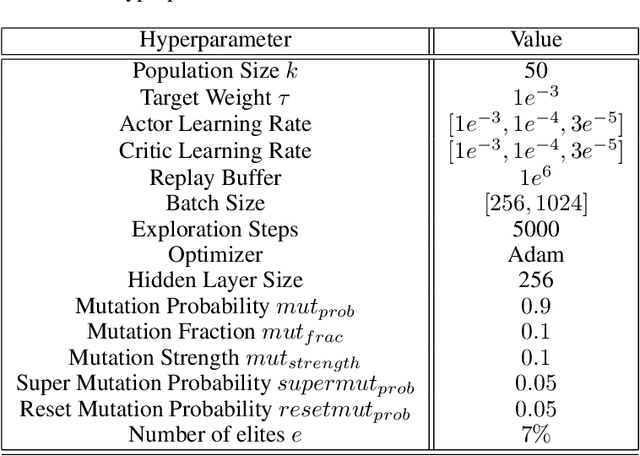
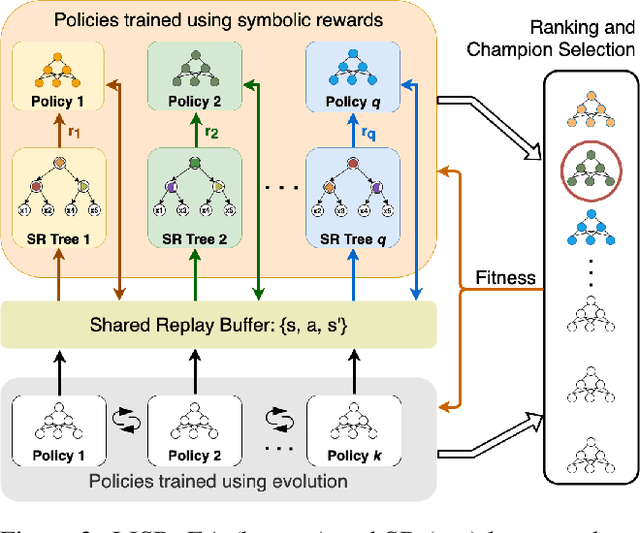
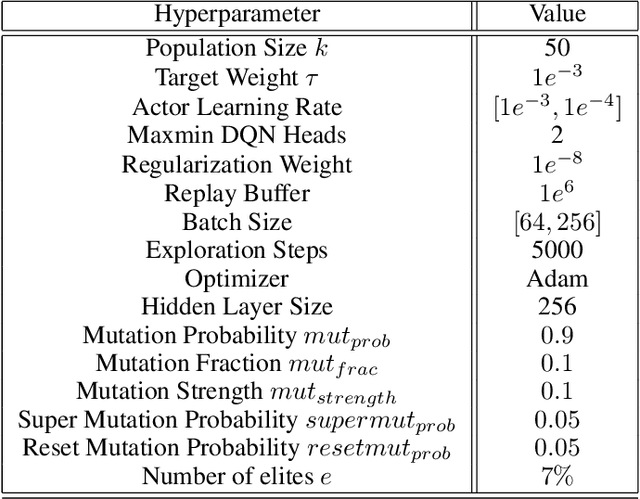
Learning effective policies for sparse objectives is a key challenge in Deep Reinforcement Learning (RL). A common approach is to design task-related dense rewards to improve task learnability. While such rewards are easily interpreted, they rely on heuristics and domain expertise. Alternate approaches that train neural networks to discover dense surrogate rewards avoid heuristics, but are high-dimensional, black-box solutions offering little interpretability. In this paper, we present a method that discovers dense rewards in the form of low-dimensional symbolic trees - thus making them more tractable for analysis. The trees use simple functional operators to map an agent's observations to a scalar reward, which then supervises the policy gradient learning of a neural network policy. We test our method on continuous action spaces in Mujoco and discrete action spaces in Atari and Pygame environments. We show that the discovered dense rewards are an effective signal for an RL policy to solve the benchmark tasks. Notably, we significantly outperform a widely used, contemporary neural-network based reward-discovery algorithm in all environments considered.