 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Intrinsic Symbolic Rewards in Reinforcement Learning
Oct 09, 2020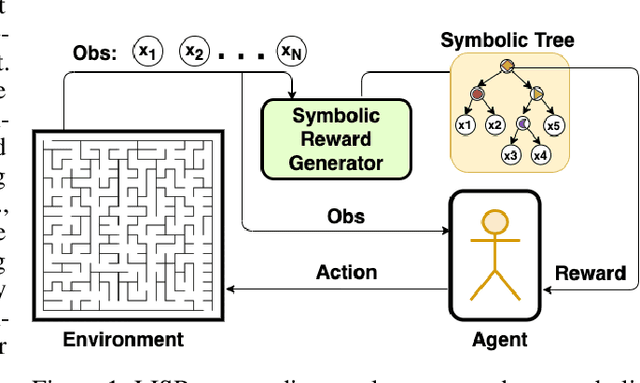
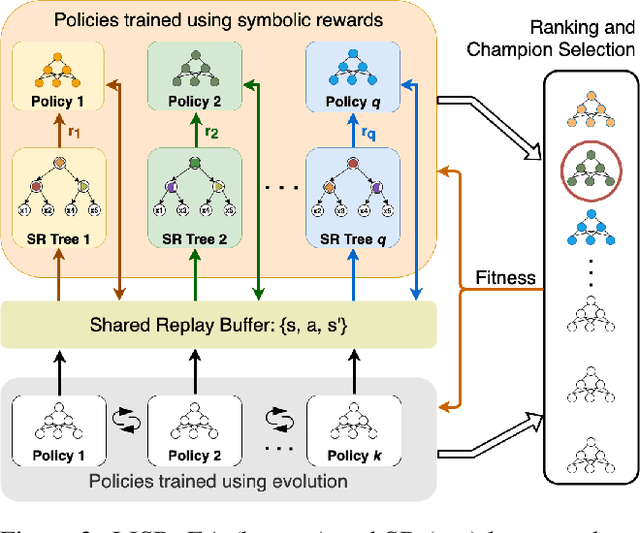
Learning effective policies for sparse objectives is a key challenge in Deep Reinforcement Learning (RL). A common approach is to design task-related dense rewards to improve task learnability. While such rewards are easily interpreted, they rely on heuristics and domain expertise. Alternate approaches that train neural networks to discover dense surrogate rewards avoid heuristics, but are high-dimensional, black-box solutions offering little interpretability. In this paper, we present a method that discovers dense rewards in the form of low-dimensional symbolic trees - thus making them more tractable for analysis. The trees use simple functional operators to map an agent's observations to a scalar reward, which then supervises the policy gradient learning of a neural network policy. We test our method on continuous action spaces in Mujoco and discrete action spaces in Atari and Pygame environments. We show that the discovered dense rewards are an effective signal for an RL policy to solve the benchmark tasks. Notably, we significantly outperform a widely used, contemporary neural-network based reward-discovery algorithm in all environments considered.
Optimizing Memory Placement using Evolutionary Graph Reinforcement Learning
Jul 14, 2020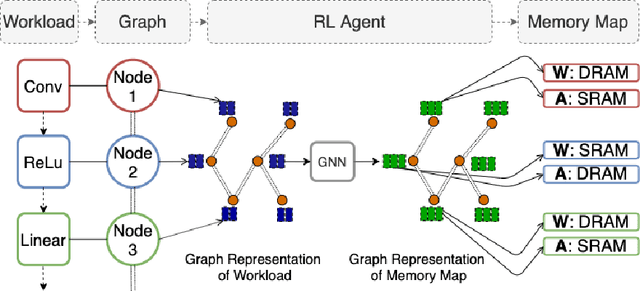

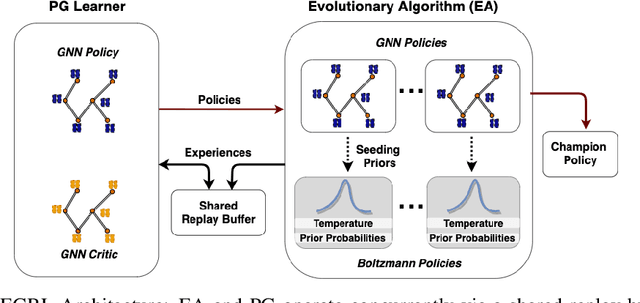
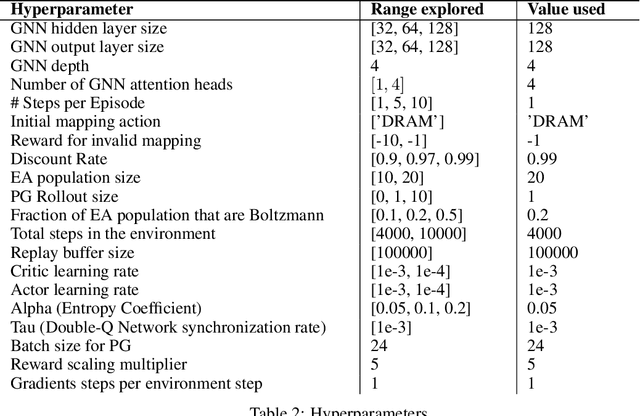
As modern neural networks have grown to billions of parameters, meeting tight latency budgets has become increasingly challenging. Approaches like compression, sparsification and network pruning have proven effective to tackle this problem - but they rely on modifications of the underlying network. In this paper, we look at a complimentary approach of optimizing how tensors are mapped to on-chip memory in an inference accelerator while leaving the network parameters untouched. Since different memory components trade off capacity for bandwidth differently, a sub-optimal mapping can result in high latency. We introduce evolutionary graph reinforcement learning (EGRL) - a method combining graph neural networks, reinforcement learning (RL) and evolutionary search - that aims to find the optimal mapping to minimize latency. Furthermore, a set of fast, stateless policies guide the evolutionary search to improve sample-efficiency. We train and validate our approach directly on the Intel NNP-I chip for inference using a batch size of 1. EGRL outperforms policy-gradient, evolutionary search and dynamic programming baselines on BERT, ResNet-101 and ResNet-50. We achieve 28-78% speed-up compared to the native NNP-I compiler on all three workloads.
Evolutionary Reinforcement Learning for Sample-Efficient Multiagent Coordination
Jun 18, 2019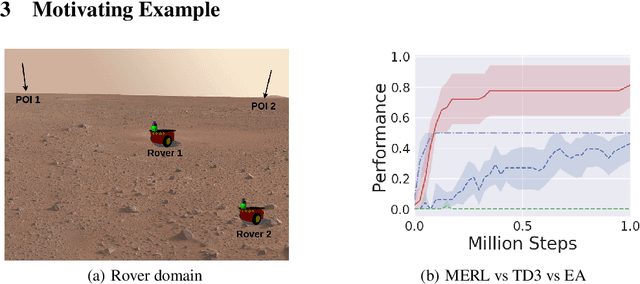
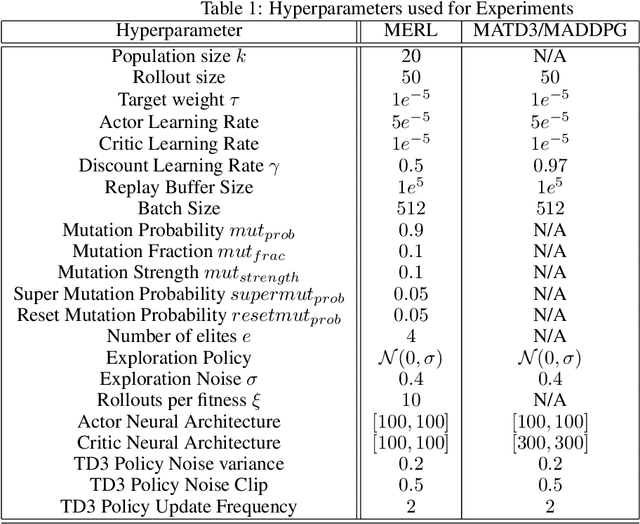
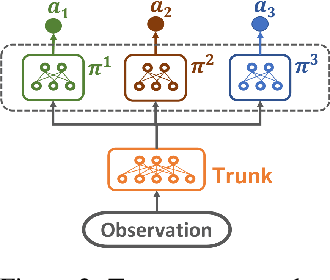

A key challenge for Multiagent RL (Reinforcement Learning) is the design of agent-specific, local rewards that are aligned with sparse global objectives. In this paper, we introduce MERL (Multiagent Evolutionary RL), a hybrid algorithm that does not require an explicit alignment between local and global objectives. MERL uses fast, policy-gradient based learning for each agent by utilizing their dense local rewards. Concurrently, an evolutionary algorithm is used to recruit agents into a team by directly optimizing the sparser global objective. We explore problems that require coupling (a minimum number of agents required to coordinate for success), where the degree of coupling is not known to the agents. We demonstrate that MERL's integrated approach is more sample-efficient and retains performance better with increasing coupling orders compared to MADDPG, the state-of-the-art policy-gradient algorithm for multiagent coordination.
Collaborative Evolutionary Reinforcement Learning
May 06, 2019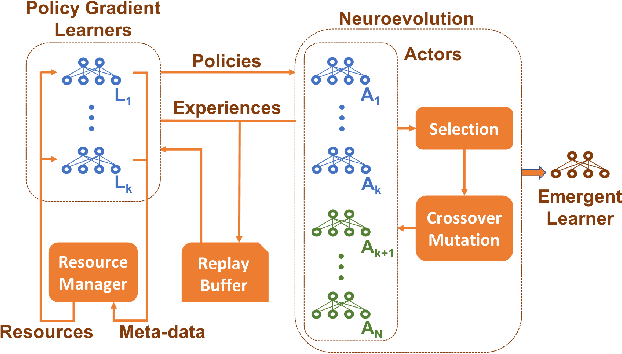
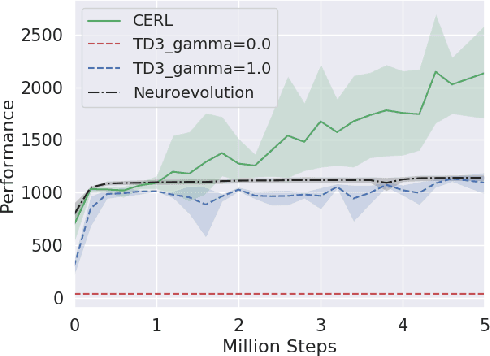
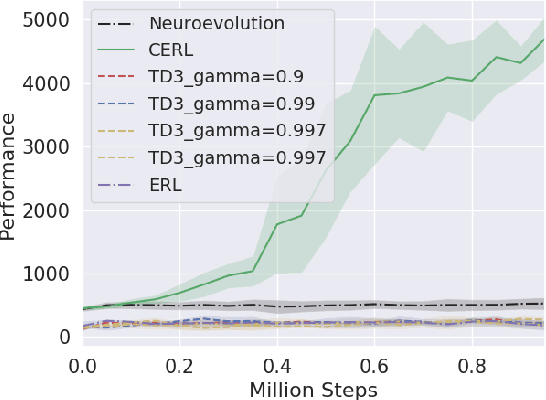
Deep reinforcement learning algorithms have been successfully applied to a range of challenging control tasks. However, these methods typically struggle with achieving effective exploration and are extremely sensitive to the choice of hyperparameters. One reason is that most approaches use a noisy version of their operating policy to explore - thereby limiting the range of exploration. In this paper, we introduce Collaborative Evolutionary Reinforcement Learning (CERL), a scalable framework that comprises a portfolio of policies that simultaneously explore and exploit diverse regions of the solution space. A collection of learners - typically proven algorithms like TD3 - optimize over varying time-horizons leading to this diverse portfolio. All learners contribute to and use a shared replay buffer to achieve greater sample efficiency. Computational resources are dynamically distributed to favor the best learners as a form of online algorithm selection. Neuroevolution binds this entire process to generate a single emergent learner that exceeds the capabilities of any individual learner. Experiments in a range of continuous control benchmarks demonstrate that the emergent learner significantly outperforms its composite learners while remaining overall more sample-efficient - notably solving the Mujoco Humanoid benchmark where all of its composite learners (TD3) fail entirely in isolation.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
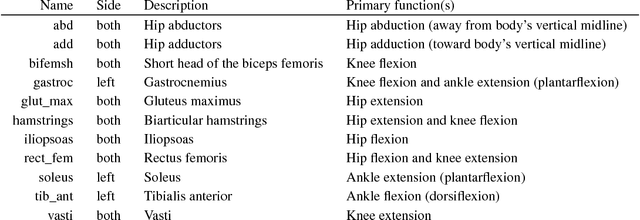
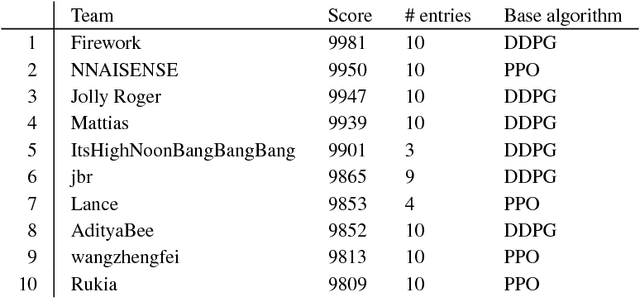

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.
Evolution-Guided Policy Gradient in Reinforcement Learning
Oct 27, 2018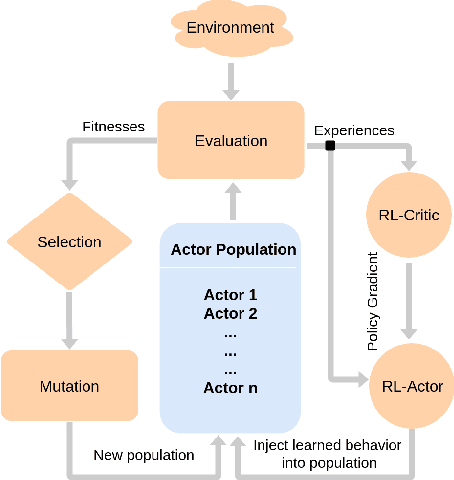
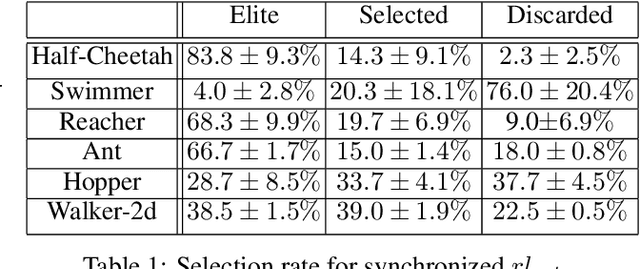
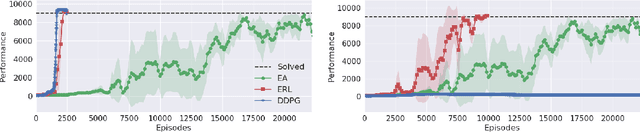
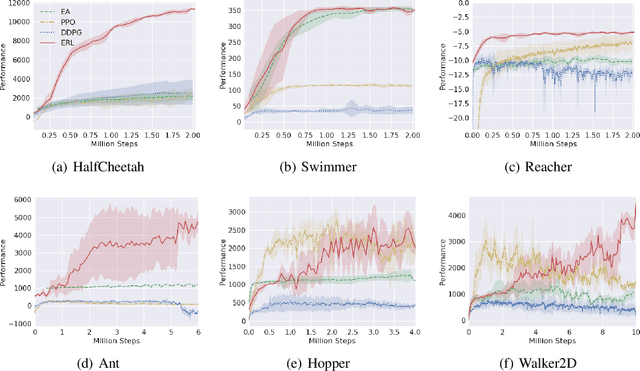
Deep Reinforcement Learning (DRL) algorithms have been successfully applied to a range of challenging control tasks. However, these methods typically suffer from three core difficulties: temporal credit assignment with sparse rewards, lack of effective exploration, and brittle convergence properties that are extremely sensitive to hyperparameters. Collectively, these challenges severely limit the applicability of these approaches to real-world problems. Evolutionary Algorithms (EAs), a class of black box optimization techniques inspired by natural evolution, are well suited to address each of these three challenges. However, EAs typically suffer from high sample complexity and struggle to solve problems that require optimization of a large number of parameters. In this paper, we introduce Evolutionary Reinforcement Learning (ERL), a hybrid algorithm that leverages the population of an EA to provide diversified data to train an RL agent, and reinserts the RL agent into the EA population periodically to inject gradient information into the EA. ERL inherits EA's ability of temporal credit assignment with a fitness metric, effective exploration with a diverse set of policies, and stability of a population-based approach and complements it with off-policy DRL's ability to leverage gradients for higher sample efficiency and faster learning. Experiments in a range of challenging continuous control benchmarks demonstrate that ERL significantly outperforms prior DRL and EA methods.