 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Memory Placement using Evolutionary Graph Reinforcement Learning
Paper and Code
Jul 14, 2020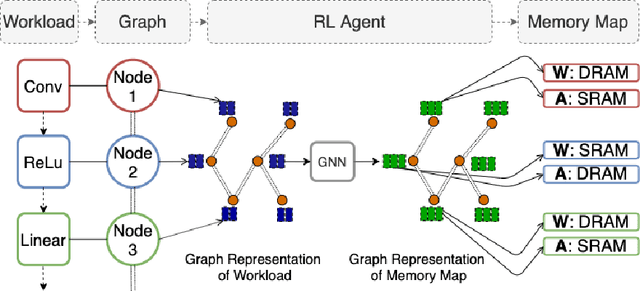

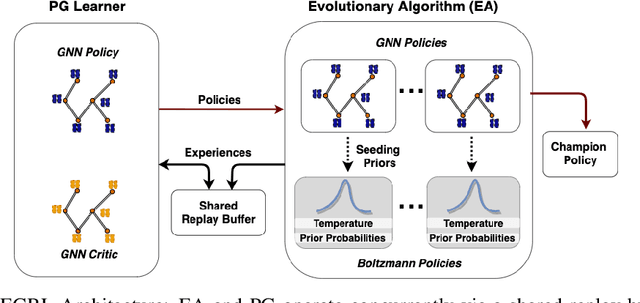
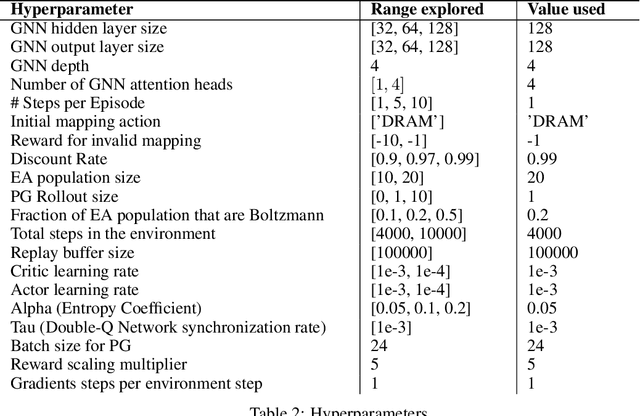
As modern neural networks have grown to billions of parameters, meeting tight latency budgets has become increasingly challenging. Approaches like compression, sparsification and network pruning have proven effective to tackle this problem - but they rely on modifications of the underlying network. In this paper, we look at a complimentary approach of optimizing how tensors are mapped to on-chip memory in an inference accelerator while leaving the network parameters untouched. Since different memory components trade off capacity for bandwidth differently, a sub-optimal mapping can result in high latency. We introduce evolutionary graph reinforcement learning (EGRL) - a method combining graph neural networks, reinforcement learning (RL) and evolutionary search - that aims to find the optimal mapping to minimize latency. Furthermore, a set of fast, stateless policies guide the evolutionary search to improve sample-efficiency. We train and validate our approach directly on the Intel NNP-I chip for inference using a batch size of 1. EGRL outperforms policy-gradient, evolutionary search and dynamic programming baselines on BERT, ResNet-101 and ResNet-50. We achieve 28-78% speed-up compared to the native NNP-I compiler on all three workloads.