 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroevolution-Enhanced Multi-Objective Optimization for Mixed-Precision Quantization
Jun 14, 2021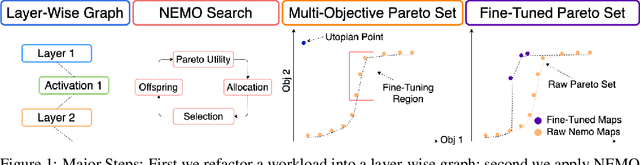
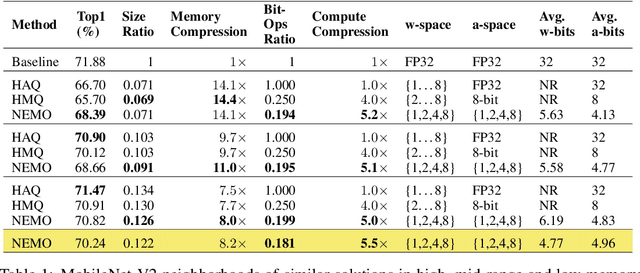
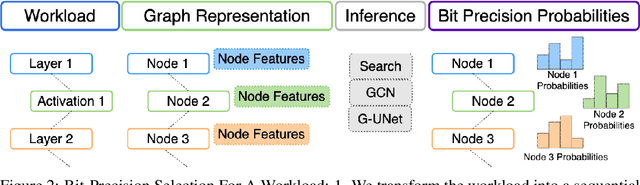
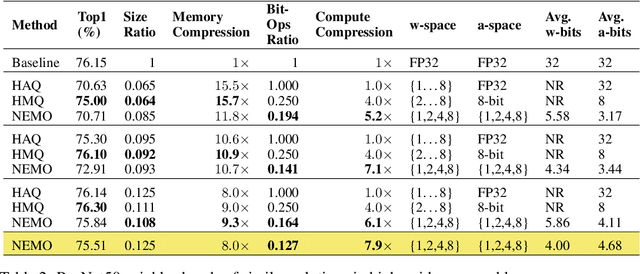
Mixed-precision quantization is a powerful tool to enable memory and compute savings of neural network workloads by deploying different sets of bit-width precisions on separate compute operations. Recent research has shown significant progress in applying mixed-precision quantization techniques to reduce the memory footprint of various workloads, while also preserving task performance. Prior work, however, has often ignored additional objectives, such as bit-operations, that are important for deployment of workloads on hardware. Here we present a flexible and scalable framework for automated mixed-precision quantization that optimizes multiple objectives. Our framework relies on Neuroevolution-Enhanced Multi-Objective Optimization (NEMO), a novel search method, to find Pareto optimal mixed-precision configurations for memory and bit-operations objectives. Within NEMO, a population is divided into structurally distinct sub-populations (species) which jointly form the Pareto frontier of solutions for the multi-objective problem. At each generation, species are re-sized in proportion to the goodness of their contribution to the Pareto frontier. This allows NEMO to leverage established search techniques and neuroevolution methods to continually improve the goodness of the Pareto frontier. In our experiments we apply a graph-based representation to describe the underlying workload, enabling us to deploy graph neural networks trained by NEMO to find Pareto optimal configurations for various workloads trained on ImageNet. Compared to the state-of-the-art, we achieve competitive results on memory compression and superior results for compute compression for MobileNet-V2, ResNet50 and ResNeXt-101-32x8d. A deeper analysis of the results obtained by NEMO also shows that both the graph representation and the species-based approach are critical in finding effective configurations for all workloads.
Optimizing Memory Placement using Evolutionary Graph Reinforcement Learning
Jul 14, 2020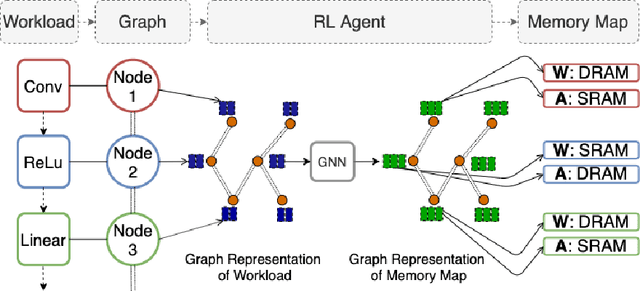

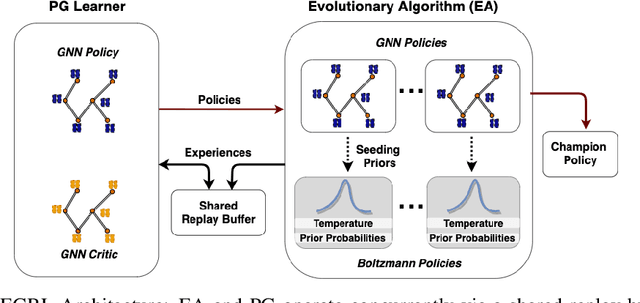
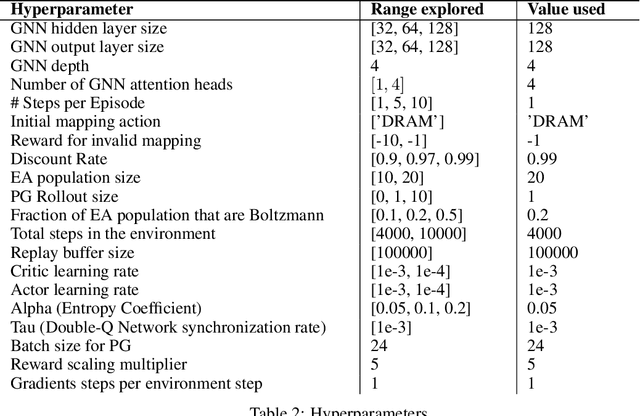
As modern neural networks have grown to billions of parameters, meeting tight latency budgets has become increasingly challenging. Approaches like compression, sparsification and network pruning have proven effective to tackle this problem - but they rely on modifications of the underlying network. In this paper, we look at a complimentary approach of optimizing how tensors are mapped to on-chip memory in an inference accelerator while leaving the network parameters untouched. Since different memory components trade off capacity for bandwidth differently, a sub-optimal mapping can result in high latency. We introduce evolutionary graph reinforcement learning (EGRL) - a method combining graph neural networks, reinforcement learning (RL) and evolutionary search - that aims to find the optimal mapping to minimize latency. Furthermore, a set of fast, stateless policies guide the evolutionary search to improve sample-efficiency. We train and validate our approach directly on the Intel NNP-I chip for inference using a batch size of 1. EGRL outperforms policy-gradient, evolutionary search and dynamic programming baselines on BERT, ResNet-101 and ResNet-50. We achieve 28-78% speed-up compared to the native NNP-I compiler on all three workloads.
RepMet: Representative-based metric learning for classification and one-shot object detection
Jun 15, 2018
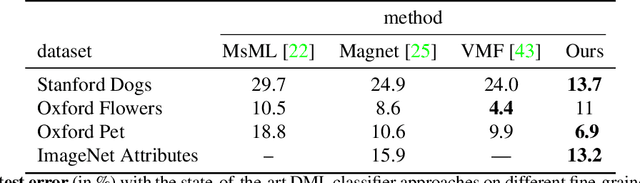
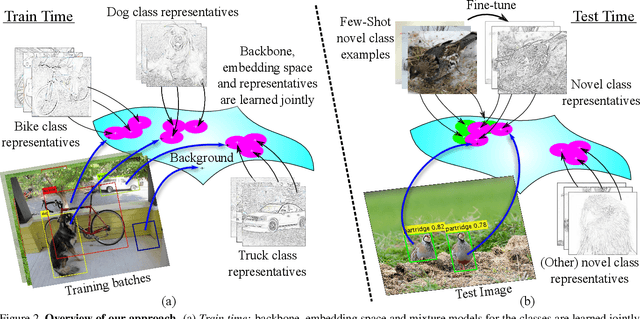
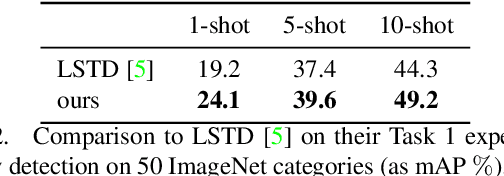
Distance metric learning (DML) has been successfully applied to object classification, both in the standard regime of rich training data and in the few-shot scenario, where each category is represented by only few examples. In this work, we propose a new method for DML, featuring a joint learning of the embedding space and of the data distribution of the training categories, in a single training process. Our method improves upon leading algorithms for DML-based object classification. Furthermore, it opens the door for a new task in Computer Vision - a few-shot object detection, since the proposed DML architecture can be naturally embedded as the classification head of any standard object detector. In numerous experiments, we achieve state-of-the-art classification results on a variety of fine-grained datasets, and offer the community a benchmark on the few-shot detection task, performed on the Imagenet-LOC dataset. The code will be made available upon acceptance.
Delta-encoder: an effective sample synthesis method for few-shot object recognition
Jun 12, 2018
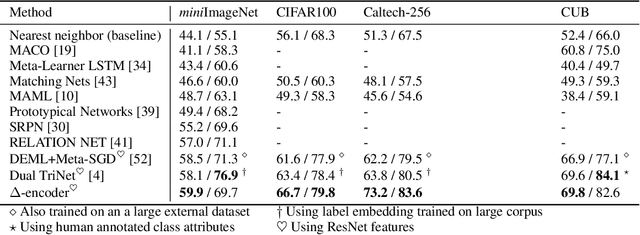
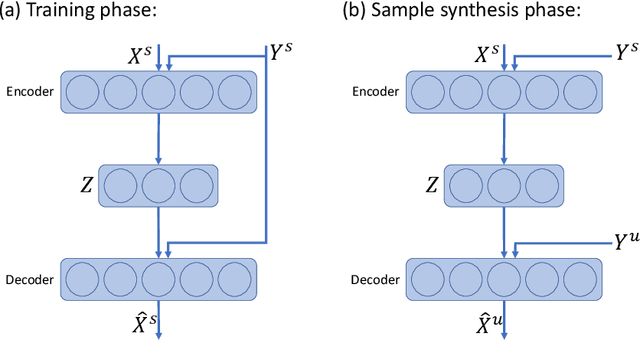

Learning to classify new categories based on just one or a few examples is a long-standing challenge in modern computer vision. In this work, we proposes a simple yet effective method for few-shot (and one-shot) object recognition. Our approach is based on a modified auto-encoder, denoted Delta-encoder, that learns to synthesize new samples for an unseen category just by seeing few examples from it. The synthesized samples are then used to train a classifier. The proposed approach learns to both extract transferable intra-class deformations, or "deltas", between same-class pairs of training examples, and to apply those deltas to the few provided examples of a novel class (unseen during training) in order to efficiently synthesize samples from that new class. The proposed method improves over the state-of-the-art in one-shot object-recognition and compares favorably in the few-shot case. Upon acceptance code will be made available.