 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense and Aligned Captions (DAC) Promote Compositional Reasoning in VL Models
Jun 01, 2023



Vision and Language (VL) models offer an effective method for aligning representation spaces of images and text, leading to numerous applications such as cross-modal retrieval, visual question answering, captioning, and more. However, the aligned image-text spaces learned by all the popular VL models are still suffering from the so-called `object bias' - their representations behave as `bags of nouns', mostly ignoring or downsizing the attributes, relations, and states of objects described/appearing in texts/images. Although some great attempts at fixing these `compositional reasoning' issues were proposed in the recent literature, the problem is still far from being solved. In this paper, we uncover two factors limiting the VL models' compositional reasoning performance. These two factors are properties of the paired VL dataset used for finetuning and pre-training the VL model: (i) the caption quality, or in other words `image-alignment', of the texts; and (ii) the `density' of the captions in the sense of mentioning all the details appearing on the image. We propose a fine-tuning approach for automatically treating these factors leveraging a standard VL dataset (CC3M). Applied to CLIP, we demonstrate its significant compositional reasoning performance increase of up to $\sim27\%$ over the base model, up to $\sim20\%$ over the strongest baseline, and by $6.7\%$ on average.
MAEDAY: MAE for few and zero shot AnomalY-Detection
Nov 25, 2022



The goal of Anomaly-Detection (AD) is to identify outliers, or outlying regions, from some unknown distribution given only a set of positive (good) examples. Few-Shot AD (FSAD) aims to solve the same task with a minimal amount of normal examples. Recent embedding-based methods, that compare the embedding vectors of queries to a set of reference embeddings, have demonstrated impressive results for FSAD, where as little as one good example is provided. A different approach, image-reconstruction-based, has been historically used for AD. The idea is to train a model to recover normal images from corrupted observations, assuming that the model will fail to recover regions when encountered with an out-of-distribution image. However, image-reconstruction-based methods were not yet used in the low-shot regime as they need to be trained on a diverse set of normal images in order to properly perform. We suggest using Masked Auto-Encoder (MAE), a self-supervised transformer model trained for recovering missing image regions based on their surroundings for FSAD. We show that MAE performs well by pre-training on an arbitrary set of natural images (ImageNet) and only fine-tuning on a small set of normal images. We name this method MAEDAY. We further find that MAEDAY provides an orthogonal signal to the embedding-based methods and the ensemble of the two approaches achieves very strong SOTA results. We also present a novel task of Zero-Shot AD (ZSAD) where no normal samples are available at training time. We show that MAEDAY performs surprisingly well at this task. Finally, we provide a new dataset for detecting foreign objects on the ground and demonstrate superior results for this task as well. Code is available at https://github.com/EliSchwartz/MAEDAY .
Teaching Structured Vision&Language Concepts to Vision&Language Models
Nov 21, 2022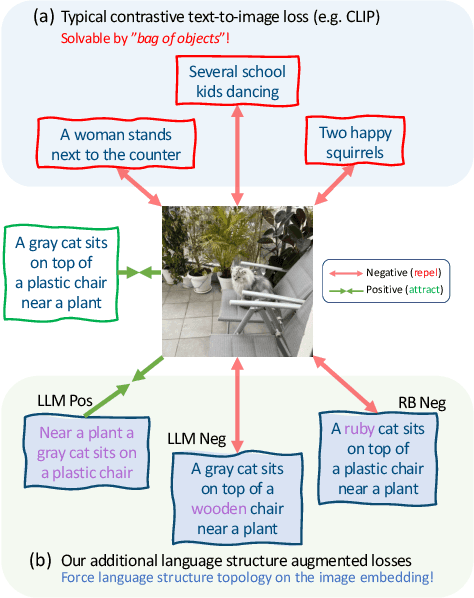
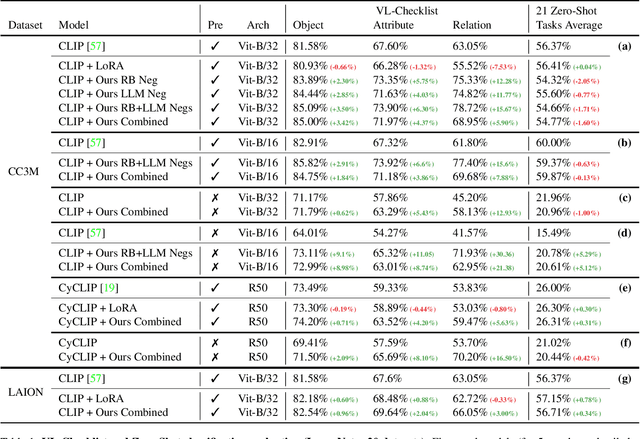
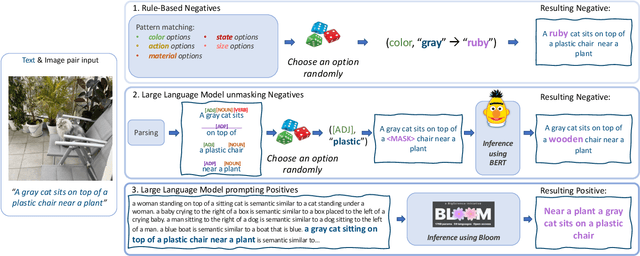

Vision and Language (VL) models have demonstrated remarkable zero-shot performance in a variety of tasks. However, some aspects of complex language understanding still remain a challenge. We introduce the collective notion of Structured Vision&Language Concepts (SVLC) which includes object attributes, relations, and states which are present in the text and visible in the image. Recent studies have shown that even the best VL models struggle with SVLC. A possible way of fixing this issue is by collecting dedicated datasets for teaching each SVLC type, yet this might be expensive and time-consuming. Instead, we propose a more elegant data-driven approach for enhancing VL models' understanding of SVLCs that makes more effective use of existing VL pre-training datasets and does not require any additional data. While automatic understanding of image structure still remains largely unsolved, language structure is much better modeled and understood, allowing for its effective utilization in teaching VL models. In this paper, we propose various techniques based on language structure understanding that can be used to manipulate the textual part of off-the-shelf paired VL datasets. VL models trained with the updated data exhibit a significant improvement of up to 15% in their SVLC understanding with only a mild degradation in their zero-shot capabilities both when training from scratch or fine-tuning a pre-trained model.
FETA: Towards Specializing Foundation Models for Expert Task Applications
Sep 08, 2022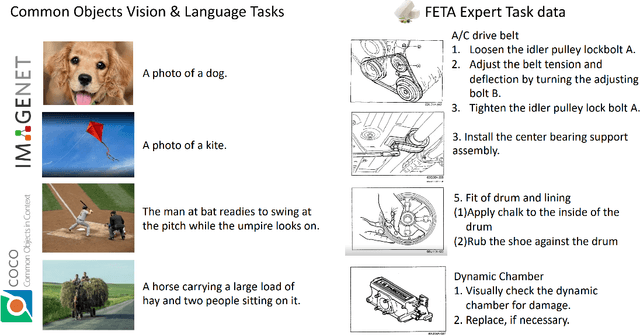

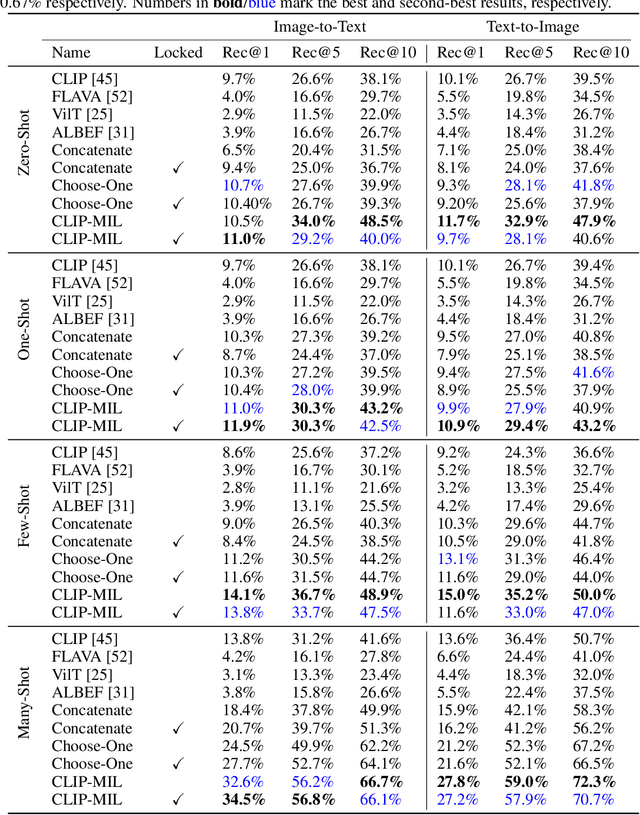
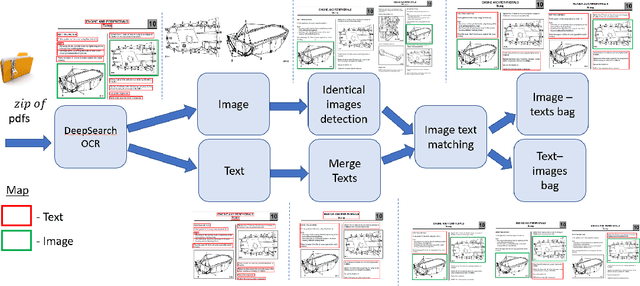
Foundation Models (FMs) have demonstrated unprecedented capabilities including zero-shot learning, high fidelity data synthesis, and out of domain generalization. However, as we show in this paper, FMs still have poor out-of-the-box performance on expert tasks (e.g. retrieval of car manuals technical illustrations from language queries), data for which is either unseen or belonging to a long-tail part of the data distribution of the huge datasets used for FM pre-training. This underlines the necessity to explicitly evaluate and finetune FMs on such expert tasks, arguably ones that appear the most in practical real-world applications. In this paper, we propose a first of its kind FETA benchmark built around the task of teaching FMs to understand technical documentation, via learning to match their graphical illustrations to corresponding language descriptions. Our FETA benchmark focuses on text-to-image and image-to-text retrieval in public car manuals and sales catalogue brochures. FETA is equipped with a procedure for completely automatic annotation extraction (code would be released upon acceptance), allowing easy extension of FETA to more documentation types and application domains in the future. Our automatic annotation leads to an automated performance metric shown to be consistent with metrics computed on human-curated annotations (also released). We provide multiple baselines and analysis of popular FMs on FETA leading to several interesting findings that we believe would be very valuable to the FM community, paving the way towards real-world application of FMs for practical expert tasks currently 'overlooked' by standard benchmarks focusing on common objects.
Unsupervised Domain Generalization by Learning a Bridge Across Domains
Dec 04, 2021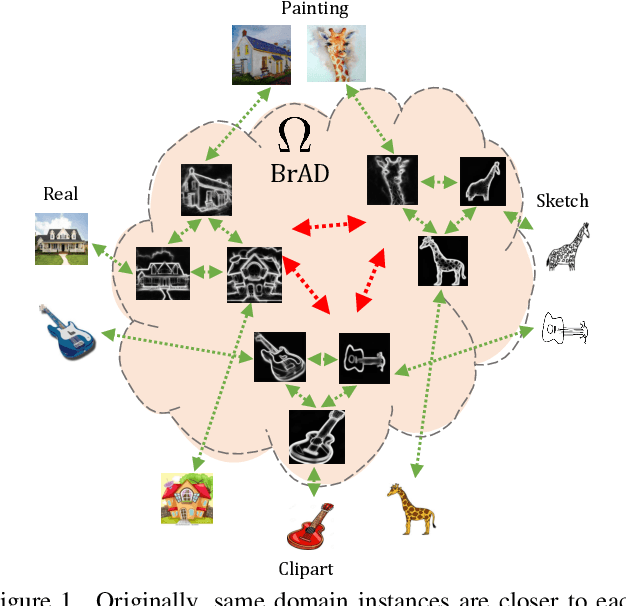
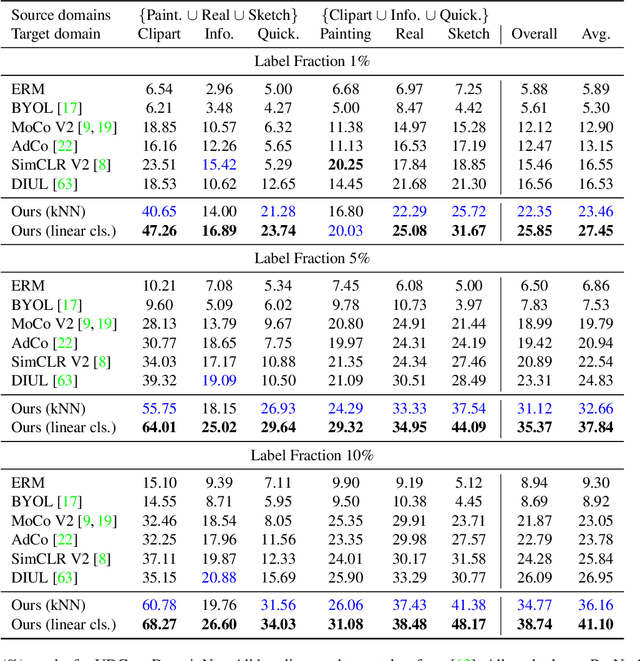
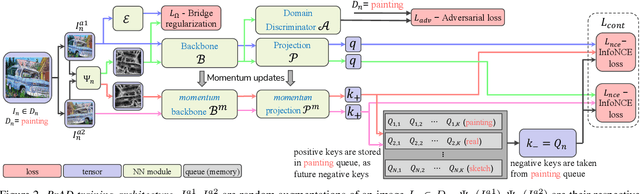
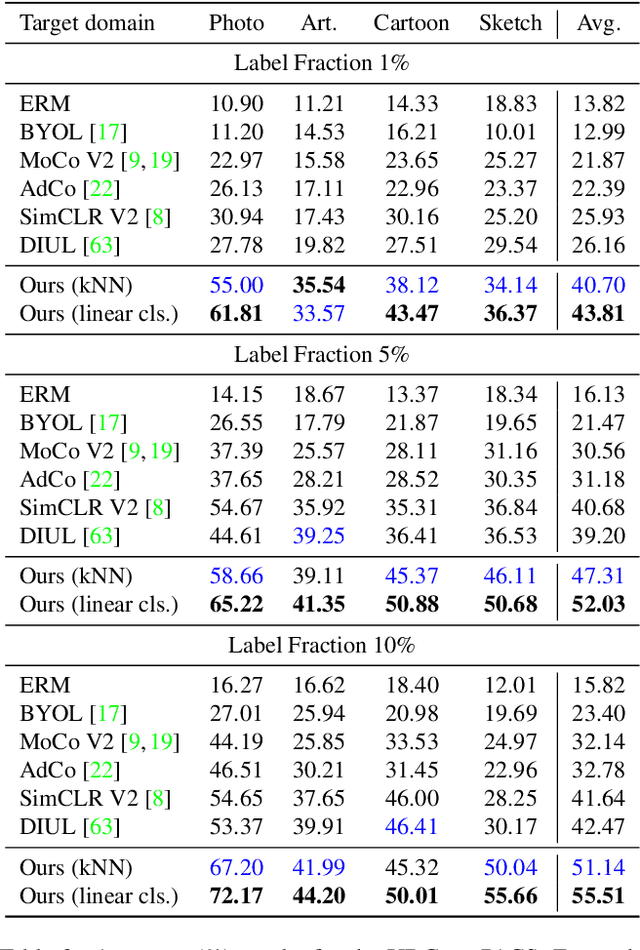
The ability to generalize learned representations across significantly different visual domains, such as between real photos, clipart, paintings, and sketches, is a fundamental capacity of the human visual system. In this paper, different from most cross-domain works that utilize some (or full) source domain supervision, we approach a relatively new and very practical Unsupervised Domain Generalization (UDG) setup of having no training supervision in neither source nor target domains. Our approach is based on self-supervised learning of a Bridge Across Domains (BrAD) - an auxiliary bridge domain accompanied by a set of semantics preserving visual (image-to-image) mappings to BrAD from each of the training domains. The BrAD and mappings to it are learned jointly (end-to-end) with a contrastive self-supervised representation model that semantically aligns each of the domains to its BrAD-projection, and hence implicitly drives all the domains (seen or unseen) to semantically align to each other. In this work, we show how using an edge-regularized BrAD our approach achieves significant gains across multiple benchmarks and a range of tasks, including UDG, Few-shot UDA, and unsupervised generalization across multi-domain datasets (including generalization to unseen domains and classes).
CHARTER: heatmap-based multi-type chart data extraction
Nov 28, 2021
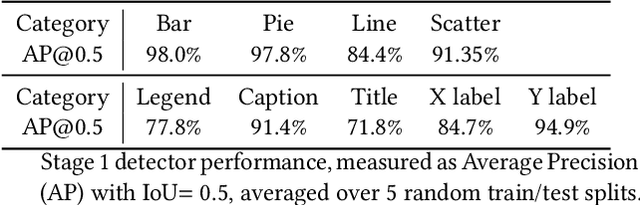
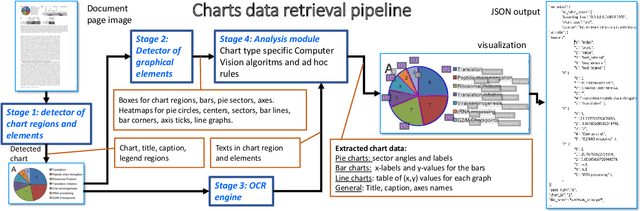
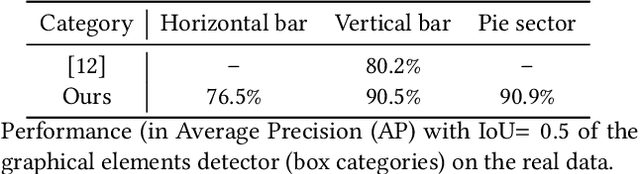
The digital conversion of information stored in documents is a great source of knowledge. In contrast to the documents text, the conversion of the embedded documents graphics, such as charts and plots, has been much less explored. We present a method and a system for end-to-end conversion of document charts into machine readable tabular data format, which can be easily stored and analyzed in the digital domain. Our approach extracts and analyses charts along with their graphical elements and supporting structures such as legends, axes, titles, and captions. Our detection system is based on neural networks, trained solely on synthetic data, eliminating the limiting factor of data collection. As opposed to previous methods, which detect graphical elements using bounding-boxes, our networks feature auxiliary domain specific heatmaps prediction enabling the precise detection of pie charts, line and scatter plots which do not fit the rectangular bounding-box presumption. Qualitative and quantitative results show high robustness and precision, improving upon previous works on popular benchmarks
* Joseph Shtok, Sivan Harary and Leonid Karlinsky had equal contribution
StarNet: towards weakly supervised few-shot detection and explainable few-shot classification
Mar 15, 2020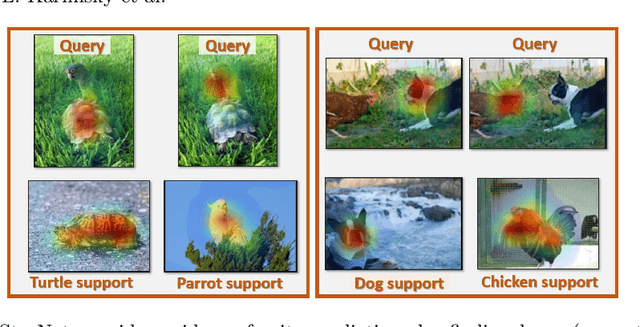
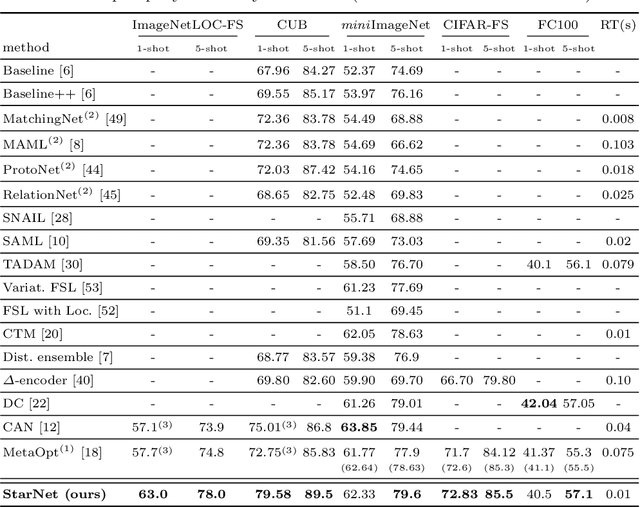
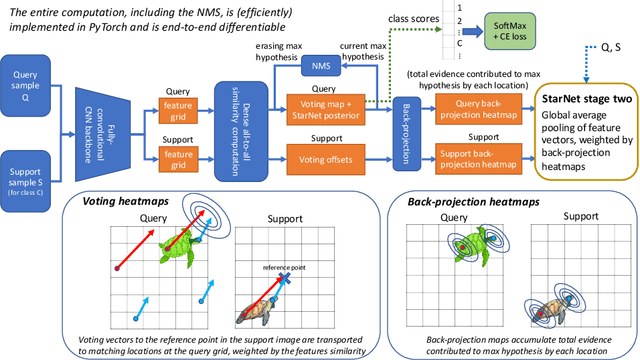
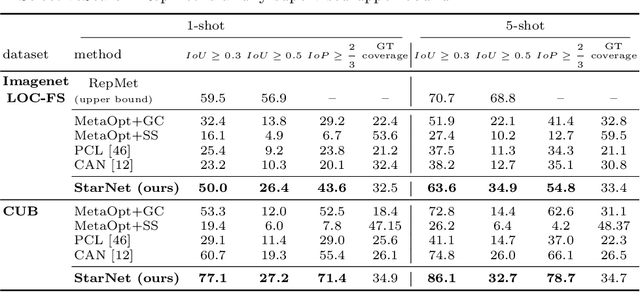
In this paper, we propose a new few-shot learning method called StarNet, which is an end-to-end trainable non-parametric star-model few-shot classifier. While being meta-trained using only image-level class labels, StarNet learns not only to predict the class labels for each query image of a few-shot task, but also to localize (via a heatmap) what it believes to be the key image regions supporting its prediction, thus effectively detecting the instances of the novel categories. The localization is enabled by the StarNet's ability to find large, arbitrarily shaped, semantically matching regions between all pairs of support and query images of a few-shot task. We evaluate StarNet on multiple few-shot classification benchmarks attaining significant state-of-the-art improvement on the CUB and ImageNetLOC-FS, and smaller improvements on other benchmarks. At the same time, in many cases, StarNet provides plausible explanations for its class label predictions, by highlighting the correctly paired novel category instances on the query and on its best matching support (for the predicted class). In addition, we test the proposed approach on the previously unexplored and challenging task of Weakly Supervised Few-Shot Object Detection (WS-FSOD), obtaining significant improvements over the baselines.
LaSO: Label-Set Operations networks for multi-label few-shot learning
Feb 26, 2019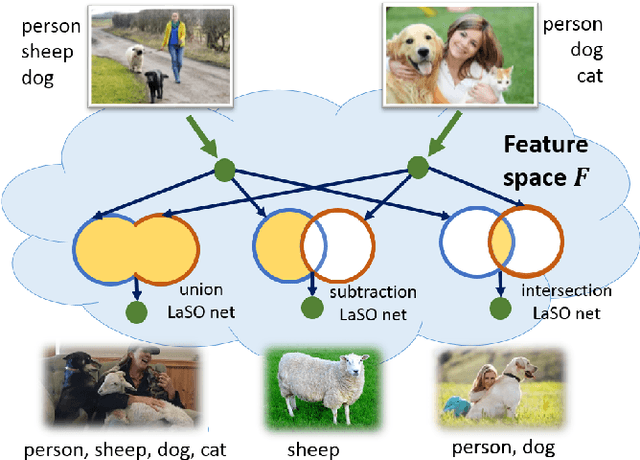
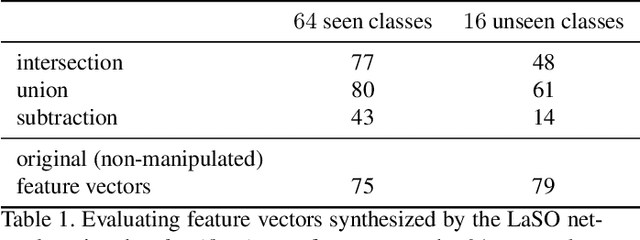

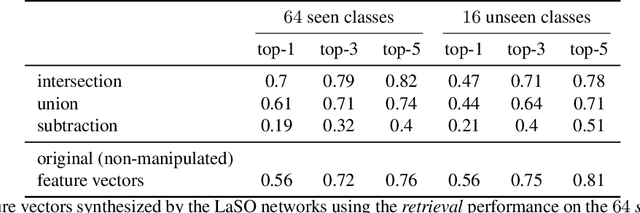
Example synthesis is one of the leading methods to tackle the problem of few-shot learning, where only a small number of samples per class are available. However, current synthesis approaches only address the scenario of a single category label per image. In this work, we propose a novel technique for synthesizing samples with multiple labels for the (yet unhandled) multi-label few-shot classification scenario. We propose to combine pairs of given examples in feature space, so that the resulting synthesized feature vectors will correspond to examples whose label sets are obtained through certain set operations on the label sets of the corresponding input pairs. Thus, our method is capable of producing a sample containing the intersection, union or set-difference of labels present in two input samples. As we show, these set operations generalize to labels unseen during training. This enables performing augmentation on examples of novel categories, thus, facilitating multi-label few-shot classifier learning. We conduct numerous experiments showing promising results for the label-set manipulation capabilities of the proposed approach, both directly (using the classification and retrieval metrics), and in the context of performing data augmentation for multi-label few-shot learning. We propose a benchmark for this new and challenging task and show that our method compares favorably to all the common baselines.
RepMet: Representative-based metric learning for classification and one-shot object detection
Jun 15, 2018
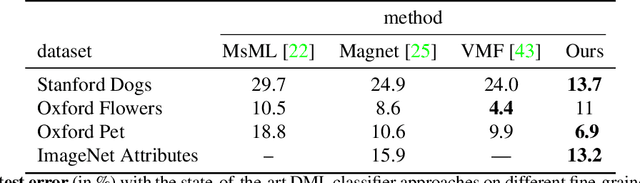
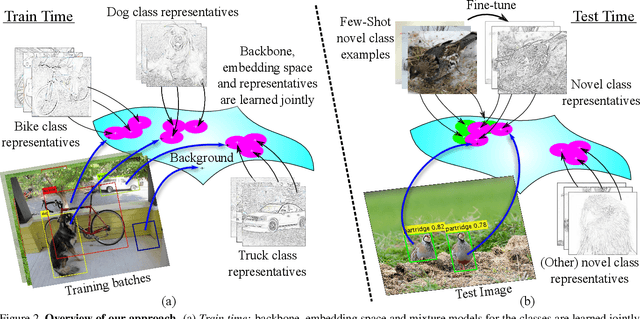
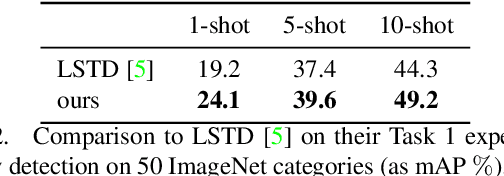
Distance metric learning (DML) has been successfully applied to object classification, both in the standard regime of rich training data and in the few-shot scenario, where each category is represented by only few examples. In this work, we propose a new method for DML, featuring a joint learning of the embedding space and of the data distribution of the training categories, in a single training process. Our method improves upon leading algorithms for DML-based object classification. Furthermore, it opens the door for a new task in Computer Vision - a few-shot object detection, since the proposed DML architecture can be naturally embedded as the classification head of any standard object detector. In numerous experiments, we achieve state-of-the-art classification results on a variety of fine-grained datasets, and offer the community a benchmark on the few-shot detection task, performed on the Imagenet-LOC dataset. The code will be made available upon acceptance.
Delta-encoder: an effective sample synthesis method for few-shot object recognition
Jun 12, 2018
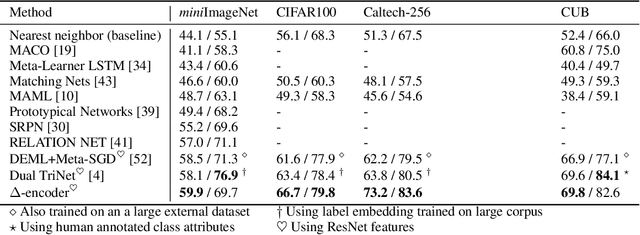
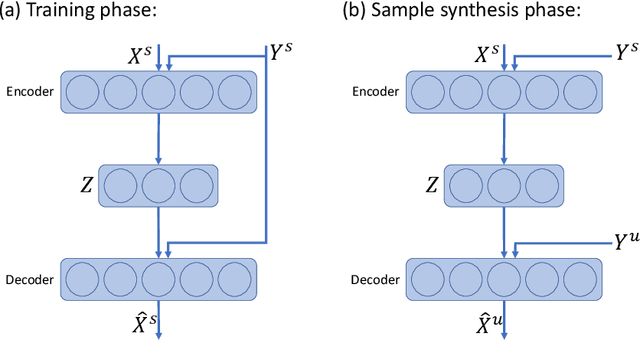

Learning to classify new categories based on just one or a few examples is a long-standing challenge in modern computer vision. In this work, we proposes a simple yet effective method for few-shot (and one-shot) object recognition. Our approach is based on a modified auto-encoder, denoted Delta-encoder, that learns to synthesize new samples for an unseen category just by seeing few examples from it. The synthesized samples are then used to train a classifier. The proposed approach learns to both extract transferable intra-class deformations, or "deltas", between same-class pairs of training examples, and to apply those deltas to the few provided examples of a novel class (unseen during training) in order to efficiently synthesize samples from that new class. The proposed method improves over the state-of-the-art in one-shot object-recognition and compares favorably in the few-shot case. Upon acceptance code will be made available.