 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Implicit Visual Reasoning
Dec 24, 2025While Large Multimodal Models (LMMs) have made significant progress, they remain largely text-centric, relying on language as their core reasoning modality. As a result, they are limited in their ability to handle reasoning tasks that are predominantly visual. Recent approaches have sought to address this by supervising intermediate visual steps with helper images, depth maps, or image crops. However, these strategies impose restrictive priors on what "useful" visual abstractions look like, add heavy annotation costs, and struggle to generalize across tasks. To address this critical limitation, we propose a task-agnostic mechanism that trains LMMs to discover and use visual reasoning tokens without explicit supervision. These tokens attend globally and re-encode the image in a task-adaptive way, enabling the model to extract relevant visual information without hand-crafted supervision. Our approach outperforms direct fine-tuning and achieves state-of-the-art results on a diverse range of vision-centric tasks -- including those where intermediate abstractions are hard to specify -- while also generalizing to multi-task instruction tuning.
Activation Reward Models for Few-Shot Model Alignment
Jul 02, 2025Aligning Large Language Models (LLMs) and Large Multimodal Models (LMMs) to human preferences is a central challenge in improving the quality of the models' generative outputs for real-world applications. A common approach is to use reward modeling to encode preferences, enabling alignment via post-training using reinforcement learning. However, traditional reward modeling is not easily adaptable to new preferences because it requires a separate reward model, commonly trained on large preference datasets. To address this, we introduce Activation Reward Models (Activation RMs) -- a novel few-shot reward modeling method that leverages activation steering to construct well-aligned reward signals using minimal supervision and no additional model finetuning. Activation RMs outperform existing few-shot reward modeling approaches such as LLM-as-a-judge with in-context learning, voting-based scoring, and token probability scoring on standard reward modeling benchmarks. Furthermore, we demonstrate the effectiveness of Activation RMs in mitigating reward hacking behaviors, highlighting their utility for safety-critical applications. Toward this end, we propose PreferenceHack, a novel few-shot setting benchmark, the first to test reward models on reward hacking in a paired preference format. Finally, we show that Activation RM achieves state-of-the-art performance on this benchmark, surpassing even GPT-4o.
Instructify: Demystifying Metadata to Visual Instruction Tuning Data Conversion
May 23, 2025Visual Instruction Tuning (VisIT) data, commonly available as human-assistant conversations with images interleaved in the human turns, are currently the most widespread vehicle for aligning strong LLMs to understand visual inputs, converting them to strong LMMs. While many VisIT datasets are available, most are constructed using ad-hoc techniques developed independently by different groups. They are often poorly documented, lack reproducible code, and rely on paid, closed-source model APIs such as GPT-4, Gemini, or Claude to convert image metadata (labels) into VisIT instructions. This leads to high costs and makes it challenging to scale, enhance quality, or generate VisIT data for new datasets. In this work, we address these challenges and propose an open and unified recipe and approach,~\textbf{\method}, for converting available metadata to VisIT instructions using open LLMs. Our multi-stage \method features an efficient framework for metadata grouping, quality control, data and prompt organization, and conversation sampling. We show that our approach can reproduce or enhance the data quality of available VisIT datasets when applied to the same image data and metadata sources, improving GPT-4 generated VisIT instructions by ~3\% on average and up to 12\% on individual benchmarks using open models, such as Gemma 2 27B and LLaMa 3.1 70B. Additionally, our approach enables effective performance scaling - both in quantity and quality - by enhancing the resulting LMM performance across a wide range of benchmarks. We also analyze the impact of various factors, including conversation format, base model selection, and resampling strategies. Our code, which supports the reproduction of equal or higher-quality VisIT datasets and facilities future metadata-to-VisIT data conversion for niche domains, is released at https://github.com/jacob-hansen/Instructify.
Overflow Prevention Enhances Long-Context Recurrent LLMs
May 12, 2025A recent trend in LLMs is developing recurrent sub-quadratic models that improve long-context processing efficiency. We investigate leading large long-context models, focusing on how their fixed-size recurrent memory affects their performance. Our experiments reveal that, even when these models are trained for extended contexts, their use of long contexts remains underutilized. Specifically, we demonstrate that a chunk-based inference procedure, which identifies and processes only the most relevant portion of the input can mitigate recurrent memory failures and be effective for many long-context tasks: On LongBench, our method improves the overall performance of Falcon3-Mamba-Inst-7B by 14%, Falcon-Mamba-Inst-7B by 28%, RecurrentGemma-IT-9B by 50%, and RWKV6-Finch-7B by 51%. Surprisingly, this simple approach also leads to state-of-the-art results in the challenging LongBench v2 benchmark, showing competitive performance with equivalent size Transformers. Furthermore, our findings raise questions about whether recurrent models genuinely exploit long-range dependencies, as our single-chunk strategy delivers stronger performance - even in tasks that presumably require cross-context relations.
CAV-MAE Sync: Improving Contrastive Audio-Visual Mask Autoencoders via Fine-Grained Alignment
May 02, 2025Recent advances in audio-visual learning have shown promising results in learning representations across modalities. However, most approaches rely on global audio representations that fail to capture fine-grained temporal correspondences with visual frames. Additionally, existing methods often struggle with conflicting optimization objectives when trying to jointly learn reconstruction and cross-modal alignment. In this work, we propose CAV-MAE Sync as a simple yet effective extension of the original CAV-MAE framework for self-supervised audio-visual learning. We address three key challenges: First, we tackle the granularity mismatch between modalities by treating audio as a temporal sequence aligned with video frames, rather than using global representations. Second, we resolve conflicting optimization goals by separating contrastive and reconstruction objectives through dedicated global tokens. Third, we improve spatial localization by introducing learnable register tokens that reduce semantic load on patch tokens. We evaluate the proposed approach on AudioSet, VGG Sound, and the ADE20K Sound dataset on zero-shot retrieval, classification and localization tasks demonstrating state-of-the-art performance and outperforming more complex architectures.
Visualizing Thought: Conceptual Diagrams Enable Robust Planning in LMMs
Mar 14, 2025Human reasoning relies on constructing and manipulating mental models-simplified internal representations of situations that we use to understand and solve problems. Conceptual diagrams (for example, sketches drawn by humans to aid reasoning) externalize these mental models, abstracting irrelevant details to efficiently capture relational and spatial information. In contrast, Large Language Models (LLMs) and Large Multimodal Models (LMMs) predominantly reason through textual representations, limiting their effectiveness in complex multi-step combinatorial and planning tasks. In this paper, we propose a zero-shot fully automatic framework that enables LMMs to reason through multiple chains of self-generated intermediate conceptual diagrams, significantly enhancing their combinatorial planning capabilities. Our approach does not require any human initialization beyond a natural language description of the task. It integrates both textual and diagrammatic reasoning within an optimized graph-of-thought inference framework, enhanced by beam search and depth-wise backtracking. Evaluated on multiple challenging PDDL planning domains, our method substantially improves GPT-4o's performance (for example, from 35.5% to 90.2% in Blocksworld). On more difficult planning domains with solution depths up to 40, our approach outperforms even the o1-preview reasoning model (for example, over 13% improvement in Parking). These results highlight the value of conceptual diagrams as a complementary reasoning medium in LMMs.
REAL-MM-RAG: A Real-World Multi-Modal Retrieval Benchmark
Feb 17, 2025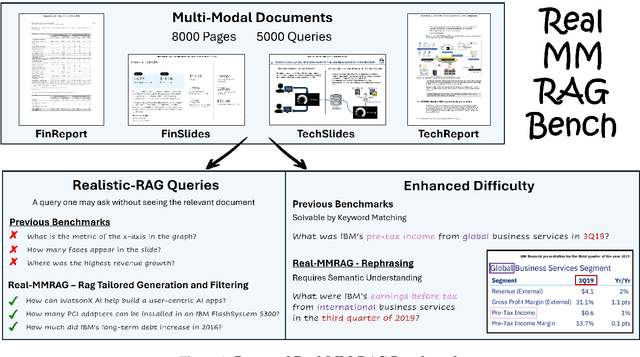
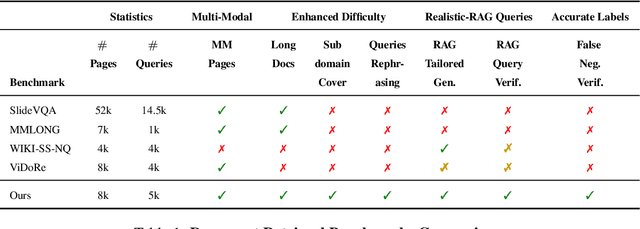

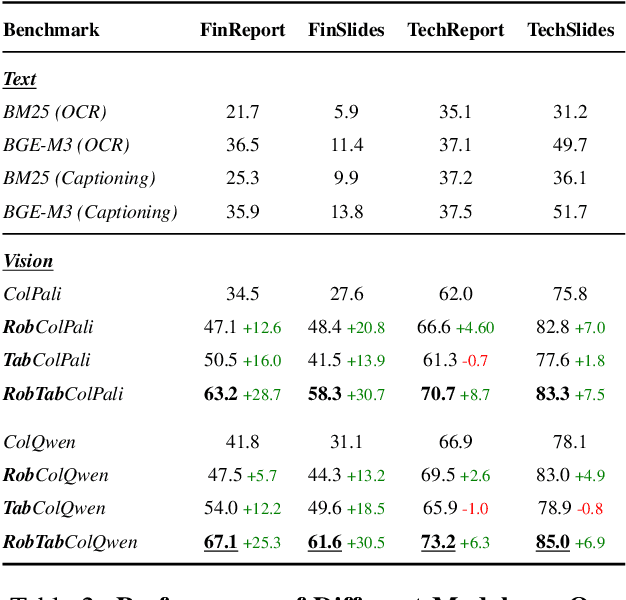
Accurate multi-modal document retrieval is crucial for Retrieval-Augmented Generation (RAG), yet existing benchmarks do not fully capture real-world challenges with their current design. We introduce REAL-MM-RAG, an automatically generated benchmark designed to address four key properties essential for real-world retrieval: (i) multi-modal documents, (ii) enhanced difficulty, (iii) Realistic-RAG queries and (iv) accurate labeling. Additionally, we propose a multi-difficulty-level scheme based on query rephrasing to evaluate models' semantic understanding beyond keyword matching. Our benchmark reveals significant model weaknesses, particularly in handling table-heavy documents and robustness to query rephrasing. To mitigate these shortcomings, we curate a rephrased training set and introduce a new finance-focused, table-heavy dataset. Fine-tuning on these datasets enables models to achieve state-of-the-art retrieval performance on REAL-MM-RAG benchmark. Our work offers a better way to evaluate and improve retrieval in multi-modal RAG systems while also providing training data and models that address current limitations.
Enhancing Robustness of CLIP to Common Corruptions through Bimodal Test-Time Adaptation
Dec 03, 2024



Although open-vocabulary classification models like Contrastive Language Image Pretraining (CLIP) have demonstrated strong zero-shot learning capabilities, their robustness to common image corruptions remains poorly understood. Through extensive experiments, we show that zero-shot CLIP lacks robustness to common image corruptions at increasing severity levels during test-time, necessitating the adaptation of CLIP to unlabeled corrupted images using test-time adaptation (TTA). However, we found that existing TTA methods have severe limitations in adapting CLIP due to their unimodal nature. To address these limitations, we propose \framework, a bimodal TTA method specially designed to improve CLIP's robustness to common image corruptions. The key insight of our approach is not only to adapt the visual encoders for better image feature extraction but also to strengthen the alignment between image and text features by promoting a stronger association between the image class prototype, computed using pseudo-labels, and the corresponding text feature. We evaluate our approach on benchmark image corruption datasets and achieve state-of-the-art results in TTA for CLIP, specifically for domains involving image corruption. Particularly, with a ViT-B/16 vision backbone, we obtain mean accuracy improvements of 9.7%, 5.94%, and 5.12% for CIFAR-10C, CIFAR-100C, and ImageNet-C, respectively.
Sparse Attention Vectors: Generative Multimodal Model Features Are Discriminative Vision-Language Classifiers
Nov 28, 2024



Generative Large Multimodal Models (LMMs) like LLaVA and Qwen-VL excel at a wide variety of vision-language (VL) tasks such as image captioning or visual question answering. Despite strong performance, LMMs are not directly suited for foundational discriminative vision-language tasks (i.e., tasks requiring discrete label predictions) such as image classification and multiple-choice VQA. One key challenge in utilizing LMMs for discriminative tasks is the extraction of useful features from generative models. To overcome this issue, we propose an approach for finding features in the model's latent space to more effectively leverage LMMs for discriminative tasks. Toward this end, we present Sparse Attention Vectors (SAVs) -- a finetuning-free method that leverages sparse attention head activations (fewer than 1\% of the heads) in LMMs as strong features for VL tasks. With only few-shot examples, SAVs demonstrate state-of-the-art performance compared to a variety of few-shot and finetuned baselines on a collection of discriminative tasks. Our experiments also imply that SAVs can scale in performance with additional examples and generalize to similar tasks, establishing SAVs as both effective and robust multimodal feature representations.
State-Space Large Audio Language Models
Nov 24, 2024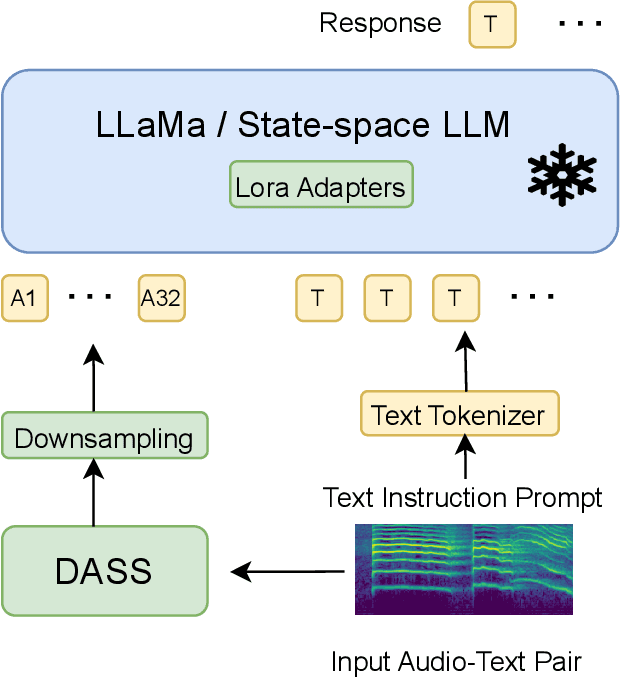
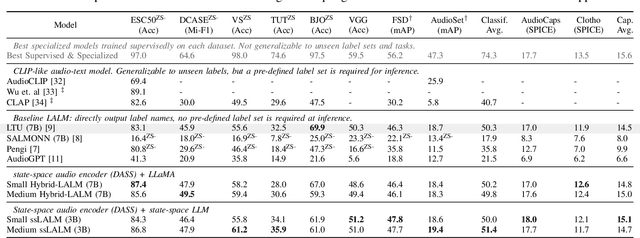

Large Audio Language Models (LALM) combine the audio perception models and the Large Language Models (LLM) and show a remarkable ability to reason about the input audio, infer the meaning, and understand the intent. However, these systems rely on Transformers which scale quadratically with the input sequence lengths which poses computational challenges in deploying these systems in memory and time-constrained scenarios. Recently, the state-space models (SSMs) have emerged as an alternative to transformer networks. While there have been successful attempts to replace transformer-based audio perception models with state-space ones, state-space-based LALMs remain unexplored. First, we begin by replacing the transformer-based audio perception module and then replace the transformer-based LLM and propose the first state-space-based LALM. Experimental results demonstrate that space-based LALM despite having a significantly lower number of parameters performs competitively with transformer-based LALMs on close-ended tasks on a variety of datasets.