 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge\$OneMillion-Bench: How Far are Language Agents from Human Experts?
Mar 09, 2026As language models (LMs) evolve from chat assistants to long-horizon agents capable of multi-step reasoning and tool use, existing benchmarks remain largely confined to structured or exam-style tasks that fall short of real-world professional demands. To this end, we introduce \$OneMillion-Bench \$OneMillion-Bench, a benchmark of 400 expert-curated tasks spanning Law, Finance, Industry, Healthcare, and Natural Science, built to evaluate agents across economically consequential scenarios. Unlike prior work, the benchmark requires retrieving authoritative sources, resolving conflicting evidence, applying domain-specific rules, and making constraint decisions, where correctness depends as much on the reasoning process as the final answer. We adopt a rubric-based evaluation protocol scoring factual accuracy, logical coherence, practical feasibility, and professional compliance, focused on expert-level problems to ensure meaningful differentiation across agents. Together, \$OneMillion-Bench provides a unified testbed for assessing agentic reliability, professional depth, and practical readiness in domain-intensive scenarios.
AgentIF-OneDay: A Task-level Instruction-Following Benchmark for General AI Agents in Daily Scenarios
Jan 28, 2026The capacity of AI agents to effectively handle tasks of increasing duration and complexity continues to grow, demonstrating exceptional performance in coding, deep research, and complex problem-solving evaluations. However, in daily scenarios, the perception of these advanced AI capabilities among general users remains limited. We argue that current evaluations prioritize increasing task difficulty without sufficiently addressing the diversity of agentic tasks necessary to cover the daily work, life, and learning activities of a broad demographic. To address this, we propose AgentIF-OneDay, aimed at determining whether general users can utilize natural language instructions and AI agents to complete a diverse array of daily tasks. These tasks require not only solving problems through dialogue but also understanding various attachment types and delivering tangible file-based results. The benchmark is structured around three user-centric categories: Open Workflow Execution, which assesses adherence to explicit and complex workflows; Latent Instruction, which requires agents to infer implicit instructions from attachments; and Iterative Refinement, which involves modifying or expanding upon ongoing work. We employ instance-level rubrics and a refined evaluation pipeline that aligns LLM-based verification with human judgment, achieving an 80.1% agreement rate using Gemini-3-Pro. AgentIF-OneDay comprises 104 tasks covering 767 scoring points. We benchmarked four leading general AI agents and found that agent products built based on APIs and ChatGPT agents based on agent RL remain in the first tier simultaneously. Leading LLM APIs and open-source models have internalized agentic capabilities, enabling AI application teams to develop cutting-edge Agent products.
BabyVision: Visual Reasoning Beyond Language
Jan 10, 2026While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.
OneReward: Unified Mask-Guided Image Generation via Multi-Task Human Preference Learning
Aug 28, 2025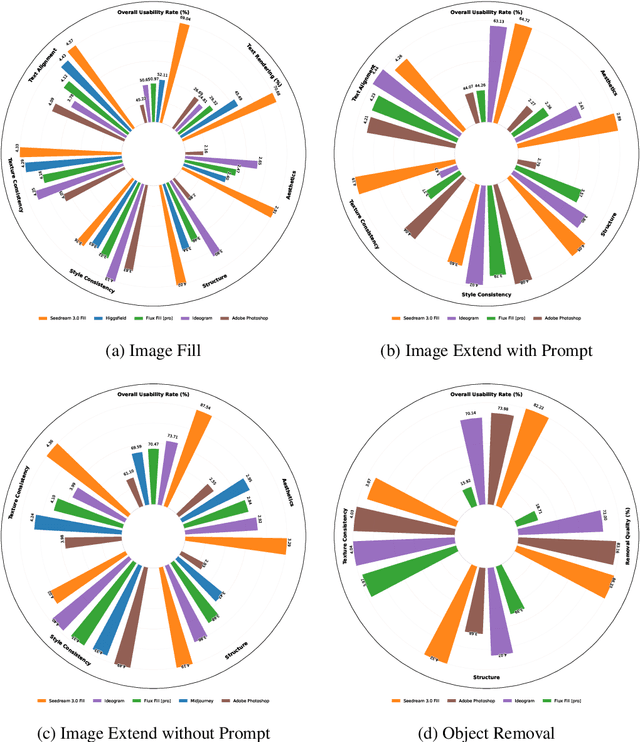

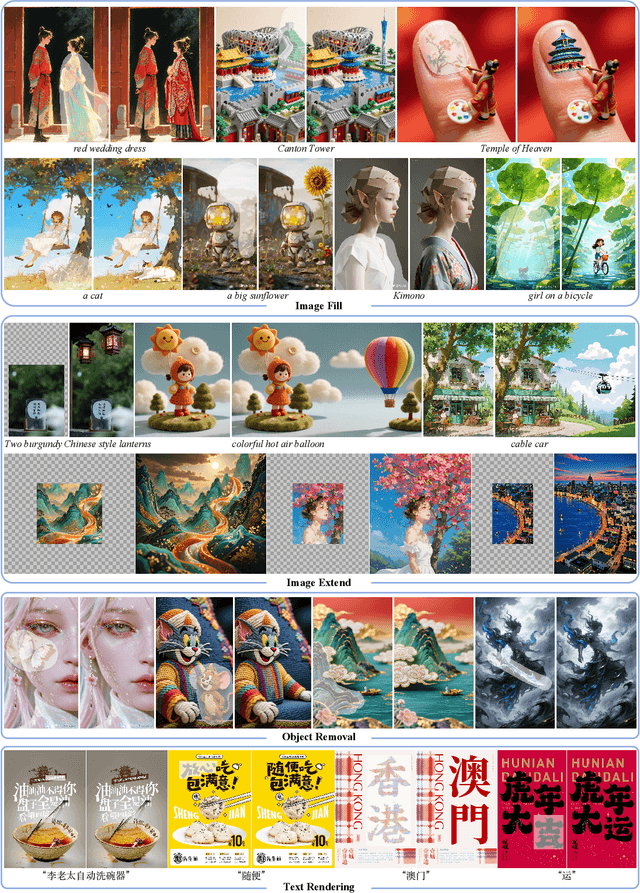
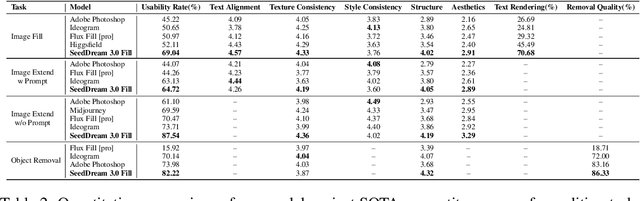
In this paper, we introduce OneReward, a unified reinforcement learning framework that enhances the model's generative capabilities across multiple tasks under different evaluation criteria using only \textit{One Reward} model. By employing a single vision-language model (VLM) as the generative reward model, which can distinguish the winner and loser for a given task and a given evaluation criterion, it can be effectively applied to multi-task generation models, particularly in contexts with varied data and diverse task objectives. We utilize OneReward for mask-guided image generation, which can be further divided into several sub-tasks such as image fill, image extend, object removal, and text rendering, involving a binary mask as the edit area. Although these domain-specific tasks share same conditioning paradigm, they differ significantly in underlying data distributions and evaluation metrics. Existing methods often rely on task-specific supervised fine-tuning (SFT), which limits generalization and training efficiency. Building on OneReward, we develop Seedream 3.0 Fill, a mask-guided generation model trained via multi-task reinforcement learning directly on a pre-trained base model, eliminating the need for task-specific SFT. Experimental results demonstrate that our unified edit model consistently outperforms both commercial and open-source competitors, such as Ideogram, Adobe Photoshop, and FLUX Fill [Pro], across multiple evaluation dimensions. Code and model are available at: https://one-reward.github.io
xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations
Jun 16, 2025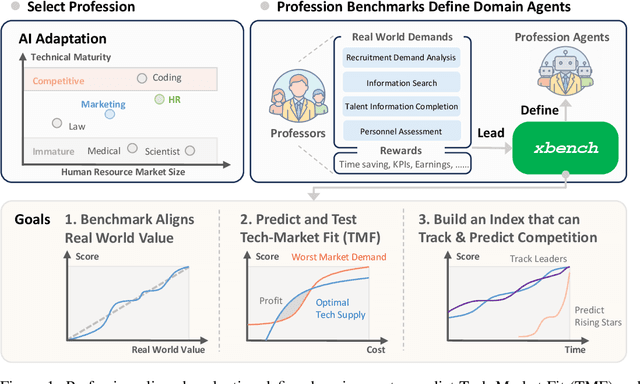

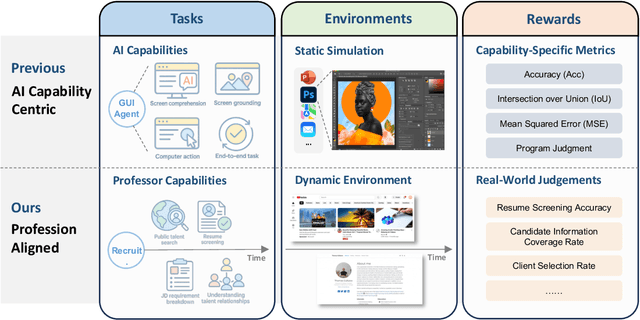
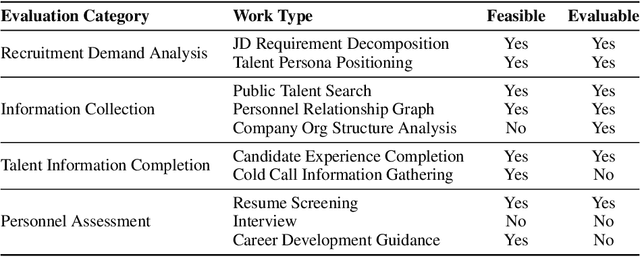
We introduce xbench, a dynamic, profession-aligned evaluation suite designed to bridge the gap between AI agent capabilities and real-world productivity. While existing benchmarks often focus on isolated technical skills, they may not accurately reflect the economic value agents deliver in professional settings. To address this, xbench targets commercially significant domains with evaluation tasks defined by industry professionals. Our framework creates metrics that strongly correlate with productivity value, enables prediction of Technology-Market Fit (TMF), and facilitates tracking of product capabilities over time. As our initial implementations, we present two benchmarks: Recruitment and Marketing. For Recruitment, we collect 50 tasks from real-world headhunting business scenarios to evaluate agents' abilities in company mapping, information retrieval, and talent sourcing. For Marketing, we assess agents' ability to match influencers with advertiser needs, evaluating their performance across 50 advertiser requirements using a curated pool of 836 candidate influencers. We present initial evaluation results for leading contemporary agents, establishing a baseline for these professional domains. Our continuously updated evalsets and evaluations are available at https://xbench.org.
CAV-MAE Sync: Improving Contrastive Audio-Visual Mask Autoencoders via Fine-Grained Alignment
May 02, 2025Recent advances in audio-visual learning have shown promising results in learning representations across modalities. However, most approaches rely on global audio representations that fail to capture fine-grained temporal correspondences with visual frames. Additionally, existing methods often struggle with conflicting optimization objectives when trying to jointly learn reconstruction and cross-modal alignment. In this work, we propose CAV-MAE Sync as a simple yet effective extension of the original CAV-MAE framework for self-supervised audio-visual learning. We address three key challenges: First, we tackle the granularity mismatch between modalities by treating audio as a temporal sequence aligned with video frames, rather than using global representations. Second, we resolve conflicting optimization goals by separating contrastive and reconstruction objectives through dedicated global tokens. Third, we improve spatial localization by introducing learnable register tokens that reduce semantic load on patch tokens. We evaluate the proposed approach on AudioSet, VGG Sound, and the ADE20K Sound dataset on zero-shot retrieval, classification and localization tasks demonstrating state-of-the-art performance and outperforming more complex architectures.
Can Diffusion Models Disentangle? A Theoretical Perspective
Mar 31, 2025This paper presents a novel theoretical framework for understanding how diffusion models can learn disentangled representations. Within this framework, we establish identifiability conditions for general disentangled latent variable models, analyze training dynamics, and derive sample complexity bounds for disentangled latent subspace models. To validate our theory, we conduct disentanglement experiments across diverse tasks and modalities, including subspace recovery in latent subspace Gaussian mixture models, image colorization, image denoising, and voice conversion for speech classification. Additionally, our experiments show that training strategies inspired by our theory, such as style guidance regularization, consistently enhance disentanglement performance.
State-Space Large Audio Language Models
Nov 24, 2024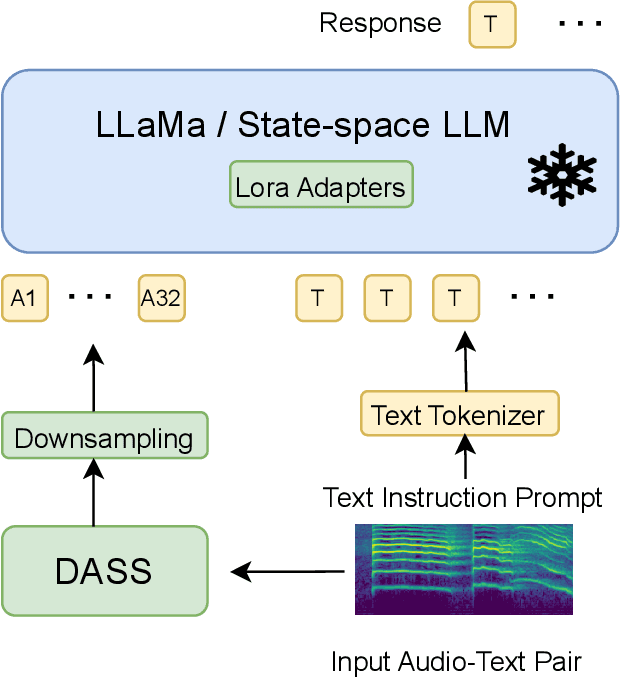
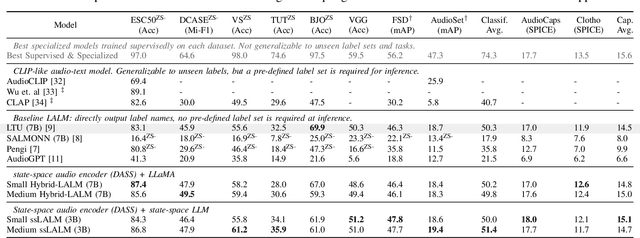

Large Audio Language Models (LALM) combine the audio perception models and the Large Language Models (LLM) and show a remarkable ability to reason about the input audio, infer the meaning, and understand the intent. However, these systems rely on Transformers which scale quadratically with the input sequence lengths which poses computational challenges in deploying these systems in memory and time-constrained scenarios. Recently, the state-space models (SSMs) have emerged as an alternative to transformer networks. While there have been successful attempts to replace transformer-based audio perception models with state-space ones, state-space-based LALMs remain unexplored. First, we begin by replacing the transformer-based audio perception module and then replace the transformer-based LLM and propose the first state-space-based LALM. Experimental results demonstrate that space-based LALM despite having a significantly lower number of parameters performs competitively with transformer-based LALMs on close-ended tasks on a variety of datasets.
A Closer Look at Neural Codec Resynthesis: Bridging the Gap between Codec and Waveform Generation
Oct 29, 2024


Neural Audio Codecs, initially designed as a compression technique, have gained more attention recently for speech generation. Codec models represent each audio frame as a sequence of tokens, i.e., discrete embeddings. The discrete and low-frequency nature of neural codecs introduced a new way to generate speech with token-based models. As these tokens encode information at various levels of granularity, from coarse to fine, most existing works focus on how to better generate the coarse tokens. In this paper, we focus on an equally important but often overlooked question: How can we better resynthesize the waveform from coarse tokens? We point out that both the choice of learning target and resynthesis approach have a dramatic impact on the generated audio quality. Specifically, we study two different strategies based on token prediction and regression, and introduce a new method based on Schr\"odinger Bridge. We examine how different design choices affect machine and human perception.
AER-LLM: Ambiguity-aware Emotion Recognition Leveraging Large Language Models
Sep 26, 2024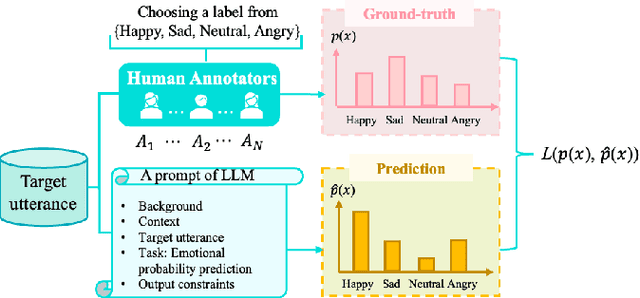
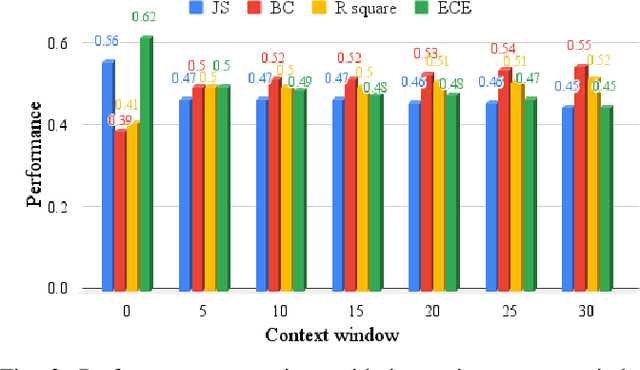
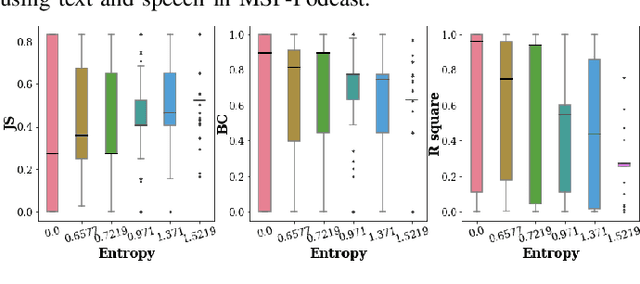
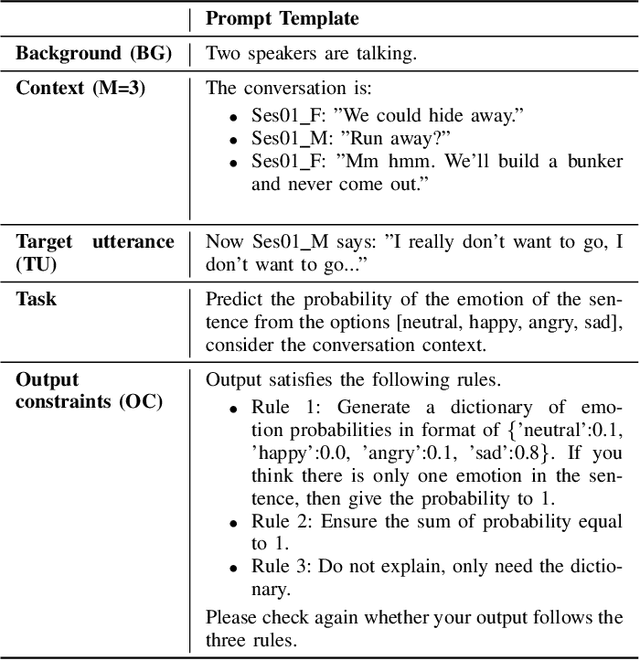
Recent advancements in Large Language Models (LLMs) have demonstrated great success in many Natural Language Processing (NLP) tasks. In addition to their cognitive intelligence, exploring their capabilities in emotional intelligence is also crucial, as it enables more natural and empathetic conversational AI. Recent studies have shown LLMs' capability in recognizing emotions, but they often focus on single emotion labels and overlook the complex and ambiguous nature of human emotions. This study is the first to address this gap by exploring the potential of LLMs in recognizing ambiguous emotions, leveraging their strong generalization capabilities and in-context learning. We design zero-shot and few-shot prompting and incorporate past dialogue as context information for ambiguous emotion recognition. Experiments conducted using three datasets indicate significant potential for LLMs in recognizing ambiguous emotions, and highlight the substantial benefits of including context information. Furthermore, our findings indicate that LLMs demonstrate a high degree of effectiveness in recognizing less ambiguous emotions and exhibit potential for identifying more ambiguous emotions, paralleling human perceptual capabilities.