 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training
Mar 12, 2026Humans perceive and understand real-world spaces through a stream of visual observations. Therefore, the ability to streamingly maintain and update spatial evidence from potentially unbounded video streams is essential for spatial intelligence. The core challenge is not simply longer context windows but how spatial information is selected, organized, and retained over time. In this paper, we propose Spatial-TTT towards streaming visual-based spatial intelligence with test-time training (TTT), which adapts a subset of parameters (fast weights) to capture and organize spatial evidence over long-horizon scene videos. Specifically, we design a hybrid architecture and adopt large-chunk updates parallel with sliding-window attention for efficient spatial video processing. To further promote spatial awareness, we introduce a spatial-predictive mechanism applied to TTT layers with 3D spatiotemporal convolution, which encourages the model to capture geometric correspondence and temporal continuity across frames. Beyond architecture design, we construct a dataset with dense 3D spatial descriptions, which guides the model to update its fast weights to memorize and organize global 3D spatial signals in a structured manner. Extensive experiments demonstrate that Spatial-TTT improves long-horizon spatial understanding and achieves state-of-the-art performance on video spatial benchmarks. Project page: https://liuff19.github.io/Spatial-TTT.
Holi-Spatial: Evolving Video Streams into Holistic 3D Spatial Intelligence
Mar 08, 2026The pursuit of spatial intelligence fundamentally relies on access to large-scale, fine-grained 3D data. However, existing approaches predominantly construct spatial understanding benchmarks by generating question-answer (QA) pairs from a limited number of manually annotated datasets, rather than systematically annotating new large-scale 3D scenes from raw web data. As a result, their scalability is severely constrained, and model performance is further hindered by domain gaps inherent in these narrowly curated datasets. In this work, we propose Holi-Spatial, the first fully automated, large-scale, spatially-aware multimodal dataset, constructed from raw video inputs without human intervention, using the proposed data curation pipeline. Holi-Spatial supports multi-level spatial supervision, ranging from geometrically accurate 3D Gaussian Splatting (3DGS) reconstructions with rendered depth maps to object-level and relational semantic annotations, together with corresponding spatial Question-Answer (QA) pairs. Following a principled and systematic pipeline, we further construct Holi-Spatial-4M, the first large-scale, high-quality 3D semantic dataset, containing 12K optimized 3DGS scenes, 1.3M 2D masks, 320K 3D bounding boxes, 320K instance captions, 1.2M 3D grounding instances, and 1.2M spatial QA pairs spanning diverse geometric, relational, and semantic reasoning tasks. Holi-Spatial demonstrates exceptional performance in data curation quality, significantly outperforming existing feed-forward and per-scene optimized methods on datasets such as ScanNet, ScanNet++, and DL3DV. Furthermore, fine-tuning Vision-Language Models (VLMs) on spatial reasoning tasks using this dataset has also led to substantial improvements in model performance.
CFG-Ctrl: Control-Based Classifier-Free Diffusion Guidance
Mar 03, 2026Classifier-Free Guidance (CFG) has emerged as a central approach for enhancing semantic alignment in flow-based diffusion models. In this paper, we explore a unified framework called CFG-Ctrl, which reinterprets CFG as a control applied to the first-order continuous-time generative flow, using the conditional-unconditional discrepancy as an error signal to adjust the velocity field. From this perspective, we summarize vanilla CFG as a proportional controller (P-control) with fixed gain, and typical follow-up variants develop extended control-law designs derived from it. However, existing methods mainly rely on linear control, inherently leading to instability, overshooting, and degraded semantic fidelity especially on large guidance scales. To address this, we introduce Sliding Mode Control CFG (SMC-CFG), which enforces the generative flow toward a rapidly convergent sliding manifold. Specifically, we define an exponential sliding mode surface over the semantic prediction error and introduce a switching control term to establish nonlinear feedback-guided correction. Moreover, we provide a Lyapunov stability analysis to theoretically support finite-time convergence. Experiments across text-to-image generation models including Stable Diffusion 3.5, Flux, and Qwen-Image demonstrate that SMC-CFG outperforms standard CFG in semantic alignment and enhances robustness across a wide range of guidance scales. Project Page: https://hanyang-21.github.io/CFG-Ctrl
SimRecon: SimReady Compositional Scene Reconstruction from Real Videos
Mar 03, 2026Compositional scene reconstruction seeks to create object-centric representations rather than holistic scenes from real-world videos, which is natively applicable for simulation and interaction. Conventional compositional reconstruction approaches primarily emphasize on visual appearance and show limited generalization ability to real-world scenarios. In this paper, we propose SimRecon, a framework that realizes a "Perception-Generation-Simulation" pipeline towards cluttered scene reconstruction, which first conducts scene-level semantic reconstruction from video input, then performs single-object generation, and finally assembles these assets in the simulator. However, naively combining these three stages leads to visual infidelity of generated assets and physical implausibility of the final scene, a problem particularly severe for complex scenes. Thus, we further propose two bridging modules between the three stages to address this problem. To be specific, for the transition from Perception to Generation, critical for visual fidelity, we introduce Active Viewpoint Optimization, which actively searches in 3D space to acquire optimal projected images as conditions for single-object completion. Moreover, for the transition from Generation to Simulation, essential for physical plausibility, we propose a Scene Graph Synthesizer, which guides the construction from scratch in 3D simulators, mirroring the native, constructive principle of the real world. Extensive experiments on the ScanNet dataset validate our method's superior performance over previous state-of-the-art approaches.
OnlineX: Unified Online 3D Reconstruction and Understanding with Active-to-Stable State Evolution
Mar 03, 2026Recent advances in generalizable 3D Gaussian Splatting (3DGS) have enabled rapid 3D scene reconstruction within seconds, eliminating the need for per-scene optimization. However, existing methods primarily follow an offline reconstruction paradigm, lacking the capacity for continuous reconstruction, which limits their applicability to online scenarios such as robotics and VR/AR. In this paper, we introduce OnlineX, a feed-forward framework that reconstructs both 3D visual appearance and language fields in an online manner using only streaming images. A key challenge in online formulation is the cumulative drift issue, which is rooted in the fundamental conflict between two opposing roles of the memory state: an active role that constantly refreshes to capture high-frequency local geometry, and a stable role that conservatively accumulates and preserves the long-term global structure. To address this, we introduce a decoupled active-to-stable state evolution paradigm. Our framework decouples the memory state into a dedicated active state and a persistent stable state, and then cohesively fuses the information from the former into the latter to achieve both fidelity and stability. Moreover, we jointly model visual appearance and language fields and incorporate an implicit Gaussian fusion module to enhance reconstruction quality. Experiments on mainstream datasets demonstrate that our method consistently outperforms prior work in novel view synthesis and semantic understanding, showcasing robust performance across input sequences of varying lengths with real-time inference speed.
BabyVision: Visual Reasoning Beyond Language
Jan 10, 2026While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.
IGGT: Instance-Grounded Geometry Transformer for Semantic 3D Reconstruction
Oct 26, 2025Humans naturally perceive the geometric structure and semantic content of a 3D world as intertwined dimensions, enabling coherent and accurate understanding of complex scenes. However, most prior approaches prioritize training large geometry models for low-level 3D reconstruction and treat high-level spatial understanding in isolation, overlooking the crucial interplay between these two fundamental aspects of 3D-scene analysis, thereby limiting generalization and leading to poor performance in downstream 3D understanding tasks. Recent attempts have mitigated this issue by simply aligning 3D models with specific language models, thus restricting perception to the aligned model's capacity and limiting adaptability to downstream tasks. In this paper, we propose InstanceGrounded Geometry Transformer (IGGT), an end-to-end large unified transformer to unify the knowledge for both spatial reconstruction and instance-level contextual understanding. Specifically, we design a 3D-Consistent Contrastive Learning strategy that guides IGGT to encode a unified representation with geometric structures and instance-grounded clustering through only 2D visual inputs. This representation supports consistent lifting of 2D visual inputs into a coherent 3D scene with explicitly distinct object instances. To facilitate this task, we further construct InsScene-15K, a large-scale dataset with high-quality RGB images, poses, depth maps, and 3D-consistent instance-level mask annotations with a novel data curation pipeline.
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
LangScene-X: Reconstruct Generalizable 3D Language-Embedded Scenes with TriMap Video Diffusion
Jul 03, 2025


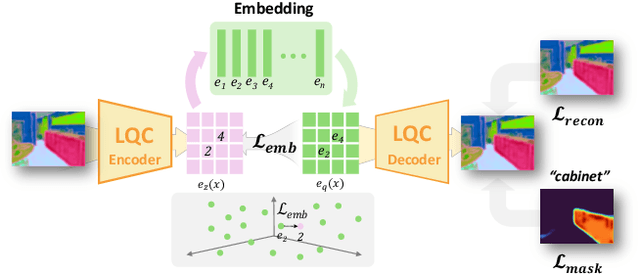
Recovering 3D structures with open-vocabulary scene understanding from 2D images is a fundamental but daunting task. Recent developments have achieved this by performing per-scene optimization with embedded language information. However, they heavily rely on the calibrated dense-view reconstruction paradigm, thereby suffering from severe rendering artifacts and implausible semantic synthesis when limited views are available. In this paper, we introduce a novel generative framework, coined LangScene-X, to unify and generate 3D consistent multi-modality information for reconstruction and understanding. Powered by the generative capability of creating more consistent novel observations, we can build generalizable 3D language-embedded scenes from only sparse views. Specifically, we first train a TriMap video diffusion model that can generate appearance (RGBs), geometry (normals), and semantics (segmentation maps) from sparse inputs through progressive knowledge integration. Furthermore, we propose a Language Quantized Compressor (LQC), trained on large-scale image datasets, to efficiently encode language embeddings, enabling cross-scene generalization without per-scene retraining. Finally, we reconstruct the language surface fields by aligning language information onto the surface of 3D scenes, enabling open-ended language queries. Extensive experiments on real-world data demonstrate the superiority of our LangScene-X over state-of-the-art methods in terms of quality and generalizability. Project Page: https://liuff19.github.io/LangScene-X.
xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations
Jun 16, 2025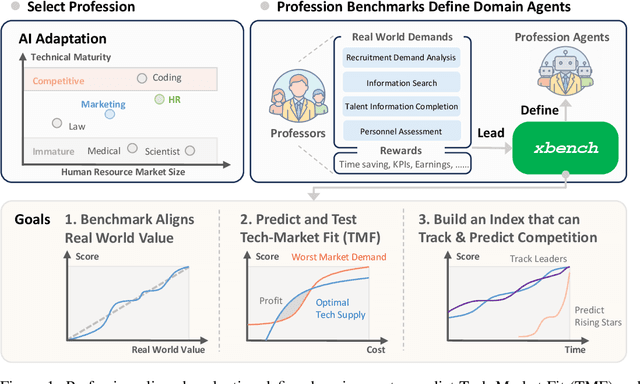

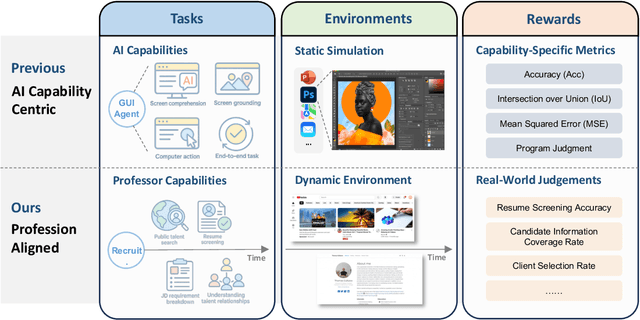
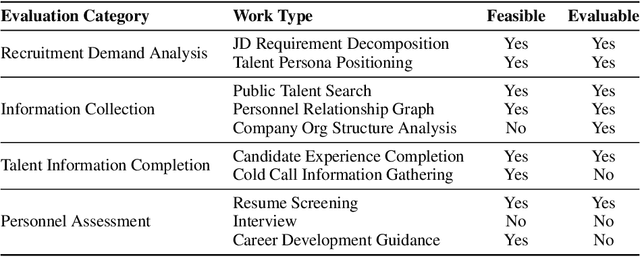
We introduce xbench, a dynamic, profession-aligned evaluation suite designed to bridge the gap between AI agent capabilities and real-world productivity. While existing benchmarks often focus on isolated technical skills, they may not accurately reflect the economic value agents deliver in professional settings. To address this, xbench targets commercially significant domains with evaluation tasks defined by industry professionals. Our framework creates metrics that strongly correlate with productivity value, enables prediction of Technology-Market Fit (TMF), and facilitates tracking of product capabilities over time. As our initial implementations, we present two benchmarks: Recruitment and Marketing. For Recruitment, we collect 50 tasks from real-world headhunting business scenarios to evaluate agents' abilities in company mapping, information retrieval, and talent sourcing. For Marketing, we assess agents' ability to match influencers with advertiser needs, evaluating their performance across 50 advertiser requirements using a curated pool of 836 candidate influencers. We present initial evaluation results for leading contemporary agents, establishing a baseline for these professional domains. Our continuously updated evalsets and evaluations are available at https://xbench.org.