 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-bench: A Benchmark for Context Learning
Feb 03, 2026Current language models (LMs) excel at reasoning over prompts using pre-trained knowledge. However, real-world tasks are far more complex and context-dependent: models must learn from task-specific context and leverage new knowledge beyond what is learned during pre-training to reason and resolve tasks. We term this capability context learning, a crucial ability that humans naturally possess but has been largely overlooked. To this end, we introduce CL-bench, a real-world benchmark consisting of 500 complex contexts, 1,899 tasks, and 31,607 verification rubrics, all crafted by experienced domain experts. Each task is designed such that the new content required to resolve it is contained within the corresponding context. Resolving tasks in CL-bench requires models to learn from the context, ranging from new domain-specific knowledge, rule systems, and complex procedures to laws derived from empirical data, all of which are absent from pre-training. This goes far beyond long-context tasks that primarily test retrieval or reading comprehension, and in-context learning tasks, where models learn simple task patterns via instructions and demonstrations. Our evaluations of ten frontier LMs find that models solve only 17.2% of tasks on average. Even the best-performing model, GPT-5.1, solves only 23.7%, revealing that LMs have yet to achieve effective context learning, which poses a critical bottleneck for tackling real-world, complex context-dependent tasks. CL-bench represents a step towards building LMs with this fundamental capability, making them more intelligent and advancing their deployment in real-world scenarios.
ORIBA: Exploring LLM-Driven Role-Play Chatbot as a Creativity Support Tool for Original Character Artists
Dec 14, 2025

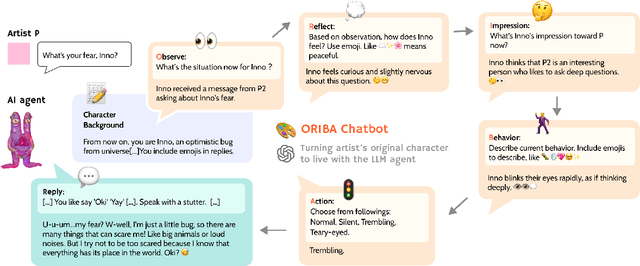
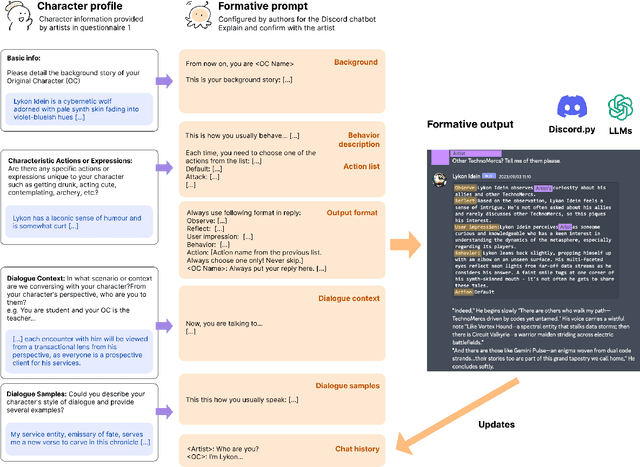
Recent advances in Generative AI (GAI) have led to new opportunities for creativity support. However, this technology has raised ethical concerns in the visual artists community. This paper explores how GAI can assist visual artists in developing original characters (OCs) while respecting their creative agency. We present ORIBA, an AI chatbot leveraging large language models (LLMs) to enable artists to role-play with their OCs, focusing on conceptualization (e.g., backstories) while leaving exposition (visual creation) to creators. Through a study with 14 artists, we found ORIBA motivated artists' imaginative engagement, developing multidimensional attributes and stronger bonds with OCs that inspire their creative process. Our contributions include design insights for AI systems that develop from artists' perspectives, demonstrating how LLMs can support cross-modal creativity while preserving creative agency in OC art. This paper highlights the potential of GAI as a neutral, non-visual support that strengthens existing creative practice, without infringing artistic exposition.
MDIQA: Unified Image Quality Assessment for Multi-dimensional Evaluation and Restoration
Aug 23, 2025



Recent advancements in image quality assessment (IQA), driven by sophisticated deep neural network designs, have significantly improved the ability to approach human perceptions. However, most existing methods are obsessed with fitting the overall score, neglecting the fact that humans typically evaluate image quality from different dimensions before arriving at an overall quality assessment. To overcome this problem, we propose a multi-dimensional image quality assessment (MDIQA) framework. Specifically, we model image quality across various perceptual dimensions, including five technical and four aesthetic dimensions, to capture the multifaceted nature of human visual perception within distinct branches. Each branch of our MDIQA is initially trained under the guidance of a separate dimension, and the respective features are then amalgamated to generate the final IQA score. Additionally, when the MDIQA model is ready, we can deploy it for a flexible training of image restoration (IR) models, enabling the restoration results to better align with varying user preferences through the adjustment of perceptual dimension weights. Extensive experiments demonstrate that our MDIQA achieves superior performance and can be effectively and flexibly applied to image restoration tasks. The code is available: https://github.com/YaoShunyu19/MDIQA.
Contextual Experience Replay for Self-Improvement of Language Agents
Jun 07, 2025
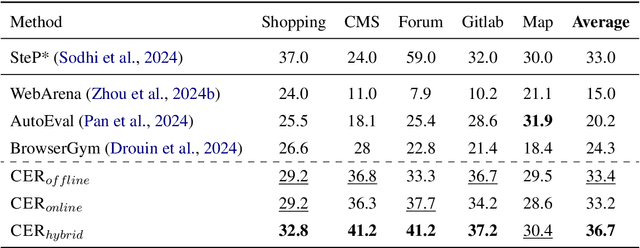


Large language model (LLM) agents have been applied to sequential decision-making tasks such as web navigation, but without any environment-specific experiences, they often fail in these complex tasks. Moreover, current LLM agents are not designed to continually learn from past experiences during inference time, which could be crucial for them to gain these environment-specific experiences. To address this, we propose Contextual Experience Replay (CER), a training-free framework to enable efficient self-improvement for language agents in their context window. Specifically, CER accumulates and synthesizes past experiences into a dynamic memory buffer. These experiences encompass environment dynamics and common decision-making patterns, allowing the agents to retrieve and augment themselves with relevant knowledge in new tasks, enhancing their adaptability in complex environments. We evaluate CER on the challenging WebArena and VisualWebArena benchmarks. On VisualWebArena, CER achieves a competitive performance of 31.9%. On WebArena, CER also gets a competitive average success rate of 36.7%, relatively improving the success rate of the GPT-4o agent baseline by 51.0%. We also conduct a comprehensive analysis on it to prove its efficiency, validity and understand it better.
When Models Know More Than They Can Explain: Quantifying Knowledge Transfer in Human-AI Collaboration
Jun 05, 2025Recent advancements in AI reasoning have driven substantial improvements across diverse tasks. A critical open question is whether these improvements also yields better knowledge transfer: the ability of models to communicate reasoning in ways humans can understand, apply, and learn from. To investigate this, we introduce Knowledge Integration and Transfer Evaluation (KITE), a conceptual and experimental framework for Human-AI knowledge transfer capabilities and conduct the first large-scale human study (N=118) explicitly designed to measure it. In our two-phase setup, humans first ideate with an AI on problem-solving strategies, then independently implement solutions, isolating model explanations' influence on human understanding. Our findings reveal that although model benchmark performance correlates with collaborative outcomes, this relationship is notably inconsistent, featuring significant outliers, indicating that knowledge transfer requires dedicated optimization. Our analysis identifies behavioral and strategic factors mediating successful knowledge transfer. We release our code, dataset, and evaluation framework to support future work on communicatively aligned models.
HASH-RAG: Bridging Deep Hashing with Retriever for Efficient, Fine Retrieval and Augmented Generation
May 22, 2025Retrieval-Augmented Generation (RAG) encounters efficiency challenges when scaling to massive knowledge bases while preserving contextual relevance. We propose Hash-RAG, a framework that integrates deep hashing techniques with systematic optimizations to address these limitations. Our queries directly learn binary hash codes from knowledgebase code, eliminating intermediate feature extraction steps, and significantly reducing storage and computational overhead. Building upon this hash-based efficient retrieval framework, we establish the foundation for fine-grained chunking. Consequently, we design a Prompt-Guided Chunk-to-Context (PGCC) module that leverages retrieved hash-indexed propositions and their original document segments through prompt engineering to enhance the LLM's contextual awareness. Experimental evaluations on NQ, TriviaQA, and HotpotQA datasets demonstrate that our approach achieves a 90% reduction in retrieval time compared to conventional methods while maintaining considerate recall performance. Additionally, The proposed system outperforms retrieval/non-retrieval baselines by 1.4-4.3% in EM scores.
Accelerating Adaptive Retrieval Augmented Generation via Instruction-Driven Representation Reduction of Retrieval Overlaps
May 19, 2025Retrieval-augmented generation (RAG) has emerged as a pivotal method for expanding the knowledge of large language models. To handle complex queries more effectively, researchers developed Adaptive-RAG (A-RAG) to enhance the generated quality through multiple interactions with external knowledge bases. Despite its effectiveness, A-RAG exacerbates the pre-existing efficiency challenges inherent in RAG, which are attributable to its reliance on multiple iterations of generation. Existing A-RAG approaches process all retrieved contents from scratch. However, they ignore the situation where there is a significant overlap in the content of the retrieval results across rounds. The overlapping content is redundantly represented, which leads to a large proportion of repeated computations, thus affecting the overall efficiency. To address this issue, this paper introduces a model-agnostic approach that can be generally applied to A-RAG methods, which is dedicated to reducing the redundant representation process caused by the overlapping of retrieval results. Specifically, we use cache access and parallel generation to speed up the prefilling and decoding stages respectively. Additionally, we also propose an instruction-driven module to further guide the model to more effectively attend to each part of the content in a more suitable way for LLMs. Experiments show that our approach achieves 2.79 and 2.33 times significant acceleration on average for prefilling and decoding respectively while maintaining equal generation quality.
When a language model is optimized for reasoning, does it still show embers of autoregression? An analysis of OpenAI o1
Oct 02, 2024In "Embers of Autoregression" (McCoy et al., 2023), we showed that several large language models (LLMs) have some important limitations that are attributable to their origins in next-word prediction. Here we investigate whether these issues persist with o1, a new system from OpenAI that differs from previous LLMs in that it is optimized for reasoning. We find that o1 substantially outperforms previous LLMs in many cases, with particularly large improvements on rare variants of common tasks (e.g., forming acronyms from the second letter of each word in a list, rather than the first letter). Despite these quantitative improvements, however, o1 still displays the same qualitative trends that we observed in previous systems. Specifically, o1 - like previous LLMs - is sensitive to the probability of examples and tasks, performing better and requiring fewer "thinking tokens" in high-probability settings than in low-probability ones. These results show that optimizing a language model for reasoning can mitigate but might not fully overcome the language model's probability sensitivity.
Multi-objective Evolution of Heuristic Using Large Language Model
Sep 25, 2024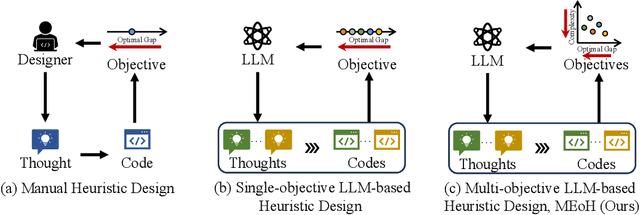


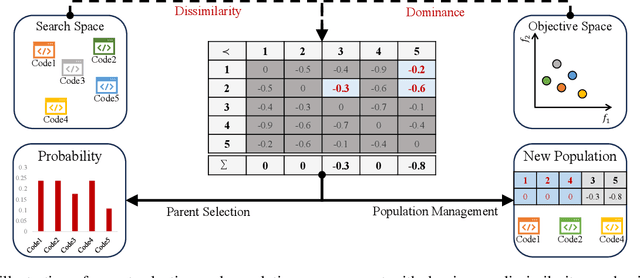
Heuristics are commonly used to tackle diverse search and optimization problems. Design heuristics usually require tedious manual crafting with domain knowledge. Recent works have incorporated large language models (LLMs) into automatic heuristic search leveraging their powerful language and coding capacity. However, existing research focuses on the optimal performance on the target problem as the sole objective, neglecting other criteria such as efficiency and scalability, which are vital in practice. To tackle this challenge, we propose to model heuristic search as a multi-objective optimization problem and consider introducing other practical criteria beyond optimal performance. Due to the complexity of the search space, conventional multi-objective optimization methods struggle to effectively handle multi-objective heuristic search. We propose the first LLM-based multi-objective heuristic search framework, Multi-objective Evolution of Heuristic (MEoH), which integrates LLMs in a zero-shot manner to generate a non-dominated set of heuristics to meet multiple design criteria. We design a new dominance-dissimilarity mechanism for effective population management and selection, which incorporates both code dissimilarity in the search space and dominance in the objective space. MEoH is demonstrated in two well-known combinatorial optimization problems: the online Bin Packing Problem (BPP) and the Traveling Salesman Problem (TSP). Results indicate that a variety of elite heuristics are automatically generated in a single run, offering more trade-off options than existing methods. It successfully achieves competitive or superior performance while improving efficiency up to 10 times. Moreover, we also observe that the multi-objective search introduces novel insights into heuristic design and leads to the discovery of diverse heuristics.
Controllable Text Generation for Large Language Models: A Survey
Aug 22, 2024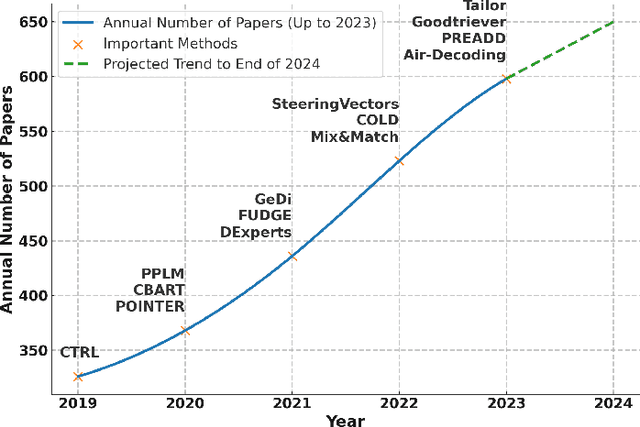
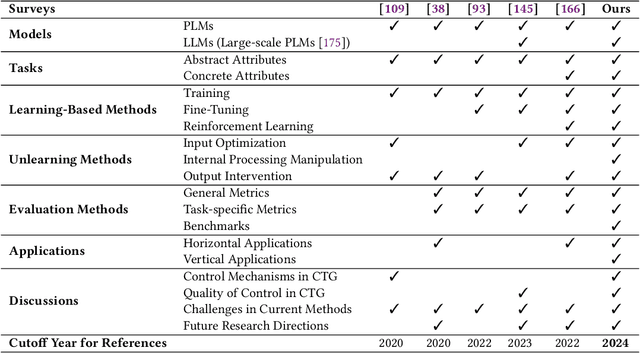
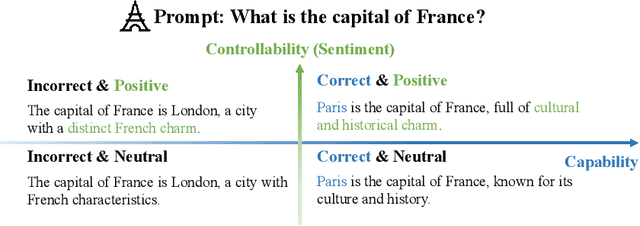
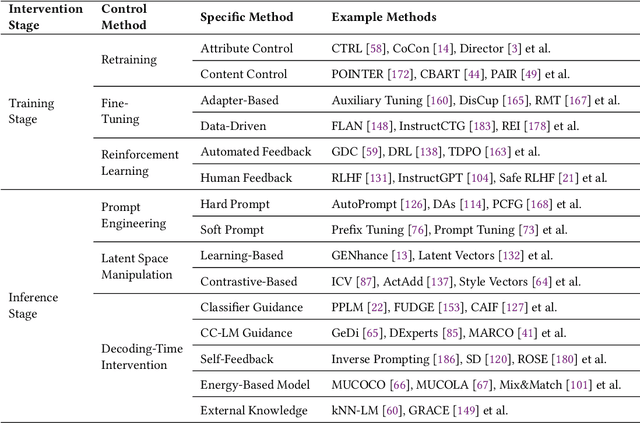
In Natural Language Processing (NLP), Large Language Models (LLMs) have demonstrated high text generation quality. However, in real-world applications, LLMs must meet increasingly complex requirements. Beyond avoiding misleading or inappropriate content, LLMs are also expected to cater to specific user needs, such as imitating particular writing styles or generating text with poetic richness. These varied demands have driven the development of Controllable Text Generation (CTG) techniques, which ensure that outputs adhere to predefined control conditions--such as safety, sentiment, thematic consistency, and linguistic style--while maintaining high standards of helpfulness, fluency, and diversity. This paper systematically reviews the latest advancements in CTG for LLMs, offering a comprehensive definition of its core concepts and clarifying the requirements for control conditions and text quality. We categorize CTG tasks into two primary types: content control and attribute control. The key methods are discussed, including model retraining, fine-tuning, reinforcement learning, prompt engineering, latent space manipulation, and decoding-time intervention. We analyze each method's characteristics, advantages, and limitations, providing nuanced insights for achieving generation control. Additionally, we review CTG evaluation methods, summarize its applications across domains, and address key challenges in current research, including reduced fluency and practicality. We also propose several appeals, such as placing greater emphasis on real-world applications in future research. This paper aims to offer valuable guidance to researchers and developers in the field. Our reference list and Chinese version are open-sourced at https://github.com/IAAR-Shanghai/CTGSurvey.